




{kind=link}
In a fast-paced world of technological innovation, leaders must continuously find the best technology to meet users' needs across their organizations. As advanced analytics and AI become everyday technologies, the challenge to support everyone and encourage collaboration between teams becomes paramount.
With Dataiku and Databricks, everyone from data professionals to business experts has what they need to collaborate and develop successful data and AI projects at scale. This blog outlines the latest integrations between Dataiku and Databricks, making it simple for data analysts and domain experts to mix Spark code and visual recipes in Dataiku and run them all on Databricks.
The key integration points are defined below and outlined with detailed examples in the subsequent sections:
- Named Databricks Connection: Connect directly into a Databricks Lakehouse to read /write Delta Tables in Dataiku.
- SQL Pushdown Computation: Pushdown Visual and SQL recipes to Databricks engine.
- Databricks Connect: Write PySpark code in Python recipes or code notebooks to be executed on Databricks cluster.
- Exchange MLFlow Models: Import a previously trained MLFlow model from Databricks into Dataiku as a Dataiku saved model for native evaluation and operationalization or export a model trained in Dataiku into Databricks.
Named Databricks Connection
The named Databricks connection allows you to load data directly from Databricks into Dataiku datasets. This gives business users the ability to access data in Lakehouse. With this direct connection, users can leverage the security and governance features of Lakehouse, as data never leaves Databricks. Users can also use the fast path to load/unload data between Databricks and other data sources via a Sync recipe.
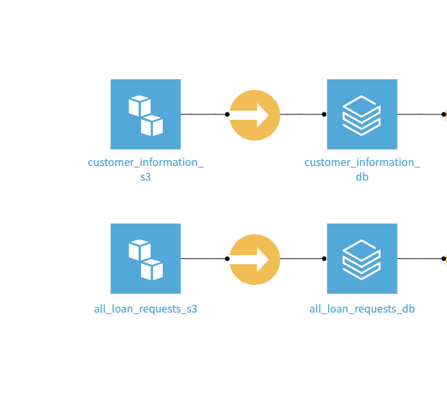
Example load / unload from S3 bucket into Databricks
SQL Pushdown Computation
With the read/write capabilities to Databricks, you can now push down all computation of Dataiku visual recipes or SQL recipes to your Databricks cluster. This means sophisticated analytic pipelines developed in Dataiku using visual or code recipes can be processed in Databricks. This feature highlights Dataiku as a platform for all, allowing developers to write code to collaborate with peers leveraging Dataiku’s visual recipes. Either way, the entire pipeline is optimized by leveraging the computational power of Databricks.
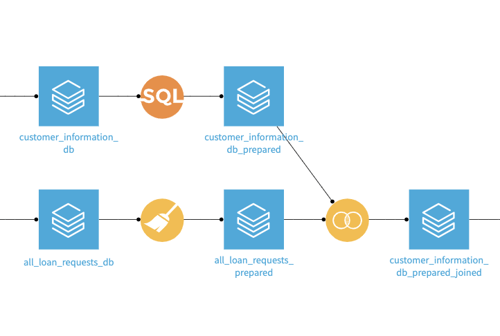
Both visual and code recipes in Dataiku leverage the compute of Databricks
Databricks Connect
Databricks’ announcement on Databricks Connect enables developers to write PySpark code in a remote environment (think: Dataiku code recipe or notebook) to execute on Databricks. Integrated seamlessly through our Python API, Dataiku can connect to your Databricks cluster by referencing the already established Dataiku connection, eliminating the need to enter credential information each time. After loading in the dataset as a dataframe, write familiar PySpark code to perform data processing.
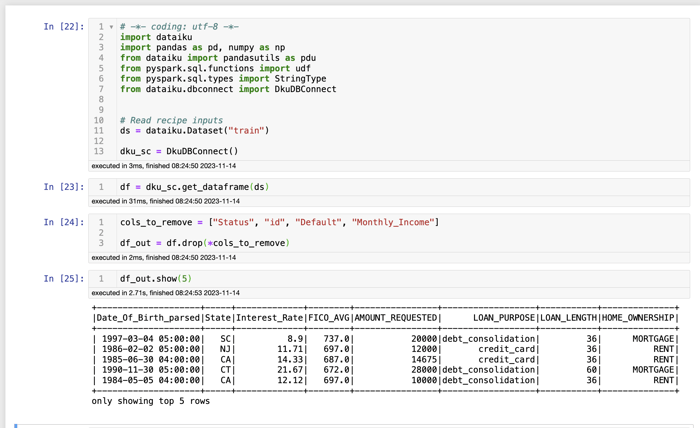
Write PySpark code in Jupyter notebooks to execute on Databricks
Exchange MLFlow Models
You can import previously trained MLFlow models into Dataiku, giving users access to all the ML management capabilities of Dataiku. A workflow may include training a model in Databricks, retrieving a registered model via an API call, and importing the MLFlow as a Dataiku saved model.
As a saved model, you can score new data with a score recipe, evaluate the performance of a model, compare multiple models or multiple versions of the model, and analyze data and performance drift. The bi-directional deployment pattern means you can also train a Dataiku model in Visual ML and export it as a MLFlow model to deploy in your Lakehouse environment.
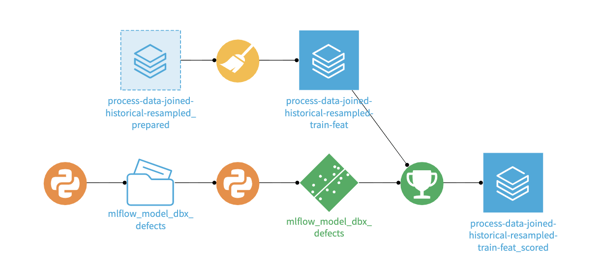
Import a previously trained model from Databricks to score with new data in Dataiku
Bringing It All Together
This how-to guide shows how our complementing technologies provide the best-in-breed stack to unify data and domain experts. Through the power of Dataiku’s collaborative interface coupled with Databricks powerful compute and storage capabilities, actionable business outcomes are just around the corner, leaving no user, their talent, or data left behind.