




{kind=link}
Over the past few years, many organizations have devoted increasing amounts of time and resources to machine learning and, more recently, artificial intelligence (AI). But many (if not most) of them express a desire to see more value from their efforts. Dataiku 4.2 is designed to move businesses along their data journey from analytics at scale to Enterprise AI. Its major upgrades in the areas of deep learning and machine learning execution and monitoring are intended to bring value from AI and machine learning, today.
Heads Up!
This blog post is about an older version of Dataiku. See the release notes for the latest version.


The three key features in Dataiku 4.2 are:
- Deep learning for images - use pre-trained deep learning models and create custom vision models with the power of transfer learning;
- Streamlined scheduling and monitoring - schedule and monitor analytics pipelines and follow the evolution of models and datasets using metrics; and
- Sample weights for training and optimization - uses weights so that rows you consider more important account for more in the training and optimization of models.
Use Deep Learning Today With Your Images
Deep learning is often presented as a technology whose application to most use cases is years off, but with Dataiku you can take advantage of deep learning to create value from your images right now.
.png?width=600&name=Infographic_l%20(1).png)
Take advantage of pre-trained models to train your own deep learning model quickly.
Using technology based on state-of-the-art research led by numerous scholars, including researchers at Google, the Dataiku Deep Learning for Images plugin extracts meaningful information from your images without training your own neural network. With just a small quantity of images, train a powerful classifier that uses the power of transfer learning to decrypt the images you input.
The custom vision models you build can classify your images into clusters, or you can extract features (e.g., shapes, colors, etc.) that can be added to existing machine learning models to improve their performance. By adding recipes directly in the interface of Dataiku, the deep learning for images plugin gets you started instantaneously.
Streamline Your Scheduling and Monitoring
As data teams scale their operations, the complexity of scheduling and monitoring analytics pipelines grows. Furthermore, monitoring models and datasets is essential for performance as data, features, and business needs shift.
Monitoring is difficult for analytics teams because they have little visibility and control in the production environment, and it is difficult for IT teams because they do not know all the metrics they should be monitoring.
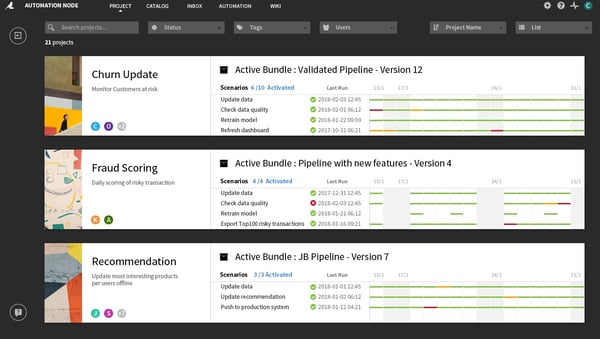
Dataiku 4.2's new interface for scheduling and monitoring analytics pipelines
Dataiku 4.2 streamlines monitoring with a dedicated interface that shows the results of each scheduled task for each project you have, from reconstructing data science pipelines to populating dashboards. Combined with the collaborative features at the core of Dataiku, this increases the visibility of projects between analytics teams and IT so that both business and technical metrics are given the attention they require.
Additionally, use Dataiku to view dedicated metrics, run checks, set scenario-based actions, and power dashboards of all your models and datasets as they evolve. Easily plug in new data sources and upgrade models and workflows. Deploy and roll back to previous versions without a hitch.
Use Sample Weights for Smarter Machine Learning
Normally, machine learning algorithms treat each row of data equally, but sometimes you need to give certain rows more weight than others — for example, if you want to optimize on a variable like amount of fraud detected, this requires weighting transactions by their amount. Now, Dataiku incorporates sample weights into training and validating machine learning models so that they can be smarter than ever.
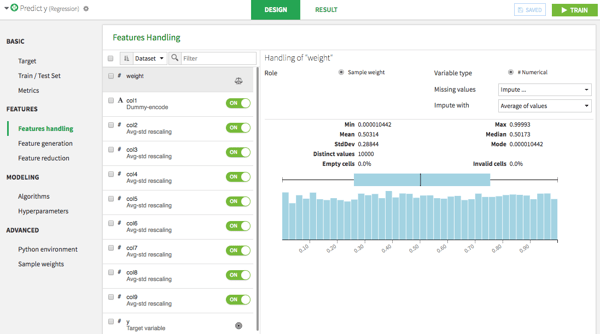
Dataiku 4.2 incorporates sample weights into its visual machine learning.
Weights can also be used for rebalancing a dataset by applying a higher weight to under-represented classes, and also for working with aggregated data that might result from grouping or anonymizing data according to security or regulatory requirements. For example, we might aggregate 1000 users into a single line of data — using sample weights tells our algorithm to treat that row as if it were really 1,000 rows.
Dataiku’s sample weights functionality works at three distinct points in the machine learning process. First, it uses the weights so that “heavier” rows account for more in the training algorithm. Second, hyperparameters optimization is done by optimizing weighted metrics. And third, the final model evaluation also uses weighted metrics.
For a demo of Dataiku, including the new features, fill out the form on this page. Or go ahead and download Dataiku now and explore it yourself!