




{kind=link}
Big news: Dataiku 5.0 is here, and it has a fresh new look and feel. But it's not just cosmetics — the latest release introduces a suite of powerful features to help organizations take the plunge into Enterprise AI.
Heads Up!
This blog post is about an older version of Dataiku. See what's new in the latest version.


With this new release, Dataiku 5.0:
- Takes containerization with Docker and Kubernetes to in-memory processing of Python and R recipes for optimized resource usage.
- It also welcomes the powerful TensorFlow library to its Visual AutoML Interface, enabling both beginner and expert users to leverage deep learning in their work.
- Last but not least, Group Discussions, Wikis, and Personalized Project Home Pages take collaboration a few steps further, from a team-centric to a large scale, organization-wide approach.
Sign up for a demo of Dataiku here, or read on for an in-depth dive into its top new features.
Full Containerization With Docker & Kubernetes
In Dataiku 4.3, we introduced Single Click Model Deployment making it possible for a standard user to create a one-stop-shop to deploy models, without having to distract IT or DevOps from their respective jobs. How? By introducing Docker/Kubernetes.
These technologies give users the ability to create containerized environments (i.e., self contained entities that can be moved to various servers) and deploy a scoring API on an elastic infrastructure to load models and serve requests in one click.
Bye-bye human bottlenecks — hello quick models to deployment and user independence.
In 5.0, we’re taking Docker and the power of “containerization” one step further: to in-memory processing of Python & R recipes, as well as in-memory model training and scoring.
When individuals need to run in-memory jobs, Dataiku will create a Docker image containing the code and required libraries or packages, and automatically deploy it to a Kubernetes cluster. Kubernetes will then take care of job orchestration and execution where cluster resources are available, thus bringing computation elasticity (and thus saved resources) and power both to the users and to the machines.
The result? More scaling and easier isolation for optimized resource usage.
Deep Learning With Keras & TensorFlow Now Available in Dataiku’s Visual AutoML Interface
Dataiku 5.0 welcomes Keras, the neural network library written in Python, to it’s ever-growing family of supported open-source libraries and technologies. Users can now define the architecture of their deep learning models directly from the Visual Machine Learning Interface. From there, Dataiku will automatically handle data preprocessing, and model training, deployment, versioning, rollback, and monitoring.

Dataiku 5.0 supports training models both on CPU and GPU, including multiple GPUs. Through containerization capabilities, training and deployment of models can happen on dynamic GPU clusters in the cloud. Plus, thanks to the availability of code samples and Tensorboard, even the members of the team who aren’t familiar with deep learning architectures can now participate in building and monitoring these more complex models and AI applications.
New-and-Improved Documentation
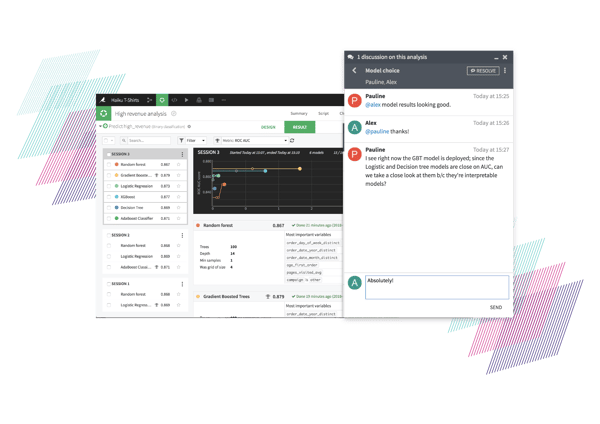
Dataiku 5.0 introduces comprehensive documentation with group discussions, wikis, and personalized project home pages:
- Dataiku Discussions: Share knowledge across the organization with Dataiku Discussions. In 5.0, anyone can create, subscribe, comment, and interact with teammates or subject matter experts across the enterprise on their chosen topics of interest. Typically associated to Dataiku items such as models, dashboards, preparation scripts (also called “recipes”), and much more, any member of the organization can easily find — or create — the information they need or want to share in the places where it is most relevant. The discussion features include notifications, conversation searches, and filtering.
- Wikis: Just like any wiki out there, users can now create spaces within Dataiku for collaborative creation and editing of documentation. Within these wikis, associate Dataiku items together, from certain datasets to dashboards, or simply list the resources within Dataiku that are apropos to specific teams. Finally, use these wikis to welcome newcomers on-board with accurate and relevant team and project documentation.
- Personalized Project Home Pages: Working on one project with many team members doesn’t mean all involved are interested in the same facets of a given project. That’s why Dataiku 5.0 let’s individual users personalize their own Project Home Page with the information that is most relevant to them. At Dataiku, we’re all about collaboration, yes, but not at the expense of individual attributes, interests, or needs.