




{kind=link}
“First, we need clean and centralized data” is probably the one sentence responsible for the most failures of large-scale data initiatives (close second to “we’ll figure out how to deploy once we have models”). In helping organizations around the globe set up and implement their data science and AI strategies, we often hear teams say that they’re waiting to figure out their data first before beginning to generate value with advanced analytics and AI — whether they’re referring to data quality, data silos, or centralization in a data lake. Indeed, conventional thinking tells us that value can be created only after siloed data is centralized and cleaned. In fact, independent market research firm Vanson Bourne surveyed hundreds of businesses across the U.S. and U.K. and 40% of respondents identified data silos as a barrier to centralizing data efforts.
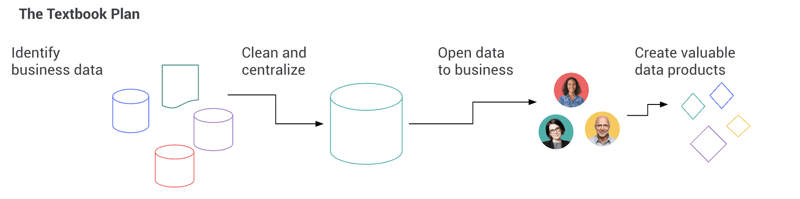
The unfortunate truth is that there is no such thing as “clean and centralized data,” there is only data good enough to support given applications. Data is like quantum physics’ Schrödinger’s cat: It is of both good and bad quality at the same time, until the point when you actually use it for a specific purpose.
To make matters worse, the exponential growth of the use of data makes it impossible to anticipate what these future uses will be (and if you do, you are actually putting constraints on the serendipitous value creation data is meant to be all about). And because bad news comes in three, whatever data you centralize and clean will most likely be obsolete by the time the effort is completed.
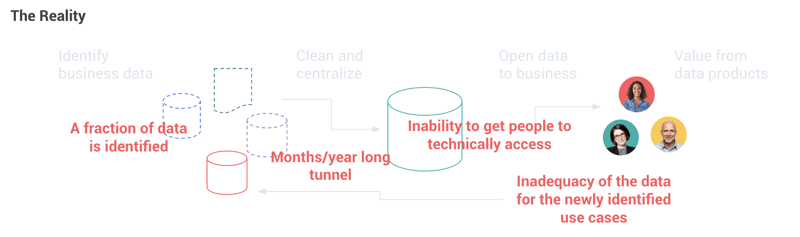 By starting with the objective of cleaning and centralizing data, many companies have ultimately delayed their ability to generate additional value from their data by a couple of years, and ended up with data swamps. But, on the other hand, if you do not have clean and centralized data, how can you actually deliver value?
By starting with the objective of cleaning and centralizing data, many companies have ultimately delayed their ability to generate additional value from their data by a couple of years, and ended up with data swamps. But, on the other hand, if you do not have clean and centralized data, how can you actually deliver value?
While it may seem all doom and gloom, things start to look brighter when you reconsider some of the key assumptions:
1) The data may be bad, but that data is still good enough for you to run your company today, so it can probably sustain at least some AI applications.
2) Centralizing the data is not an end game, but actually it is just one of the many ways to open broader use of data.
3) Business people actually understand their own data better than anyone else.
From these, it is possible not to think of data centralization and cleansing as a first step towards value delivery, but both of these as a continuous virtuous cycle of execution: “Business drives data that drives business.” When done right, not starting with data centralization and cleansing can actually accelerate it!
For this to succeed, only two things are required: empowering domain experts to take ownership of their data, and facilitating cross-functional reuse of any data assets created. By doing so, cross-silo sharing will be driven by business priorities without having to be first transmitted through a central team’s backlog. Central teams can focus on what matters, which is helping data assets improve over time to become more reusable and, therefore, more valuable. These data assets are built by those who know the data best.
Hear from Dataiku AI Evangelist Stephanie Griffiths below about why you shouldn’t wait until your data is in order to get started with AI.
How Does Dataiku Enable This in Practice?
By taking the approach outlined above, teams can break down data silos by locally empowering their own domain experts. Here’s what we mean:
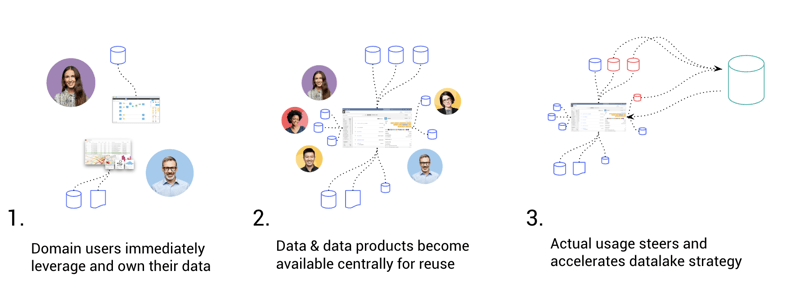
1. Domain users immediately leverage and own their data.
By empowering domain users to connect to and use their own data, teams can drive massive efficiency gains with pipelining, ops, and even machine learning. Dataiku provides pre-built connectors to dozens of leading data sources both on-premises and in the cloud, including Amazon S3, Azure Blob Storage, Google Cloud Storage, Snowflake, SQL databases, NoSQL databases, HDFS, and more.
2. Data and data products become available centrally for reuse.
Data used by various teams is cataloged and browsable by other users in compliance with proper security requirements and regulations. Data is available with its context: how it is processed for use, wikis, tagging, models, dashboards, and statistical analysis.
3. Actual usage steers and accelerates data centralization and cleansing strategy
A complete view of data dependency and preparation within and between projects helps identify key data resources. A validation and governance path can be defined and critical path data can be specifically stewarded or centralized in a new repository, with a lift and shift of existing projects.
Successful AI Is Everyday AI
As mentioned above, in order to organically make trustable data leverageable by the broader organizations, teams need to be able to deliver instant value and a long-term data foundation. This nicely aligns with the multi-pronged approach to Everyday AI, that is:
-
Short-Term: Delivering Quick, High-Impact AI Wins: because, let’s face it, you can’t afford to wait years to prove the return on investment of AI initiatives.
-
Long-Term: Enabling a Transformative AI Culture: because thinking about AI implementation is only on a use-case-by-use-case basis for the long term isn’t sustainable (or economical).
By taking this same approach to their data efforts and not waiting to get all of their data ducks in a row (from data catalogs and warehousing to data lineage and master data management) before planning for and attempting to enable AI, organizations will be able to mitigate risk, drive initial successes and generate buy-in, and successfully set themselves up for the future.