{kind=link}
Picture this: You’re scrolling through your favorite social media platform, and you come across a stunning image of a picturesque landscape. Intrigued, you type in a question about the location, expecting a response from a fellow user. But instead, a machine seamlessly identifies the scene and its location, provides a detailed description, and even suggests nearby attractions.
This scenario is not science fiction but a glimpse into the capabilities of Multimodal Large Language Models (M-LLMs), where the convergence of various modalities extends the landscape of AI.

M-LLMs seamlessly integrate multimodal information, enabling them to comprehend the world by processing diverse forms of data, including text, images, audio, and so on. At their core, M-LLMs consist of versatile neural networks capable of ingesting various data types, thereby gaining insights across different modalities.
M-LLMs exhibit remarkable proficiency across various real-world tasks. For instance, they excel in generating relevant captions for images, providing detailed descriptions that enhance user engagement on social media platforms. When presented with a photograph of a scenic mountain landscape, an M-LLM might generate a captivating caption like, “A breathtaking view of snow-capped mountains against a clear blue sky.”
Moreover, M-LLMs adeptly answer questions about visual content, aiding in tasks like image recognition and scene understanding. When asked “What landmarks are visible in this cityscape?” an M-LLM might accurately identify and list prominent landmarks like the Eiffel Tower, the Statue of Liberty, and the Sydney Opera House.
In this blog post, we delve into the workings of M-LLMs, unraveling the intricacies of their architecture, with a particular focus on text and vision integration. Additionally, we’ll explore their proficiency in tasks such as generating descriptive captions for images and answering questions about visual content. Here’s what we’ll cover:
- Deep Dive Into Tasks
- M-LLMs for Visual Question Answering (VQA)
- M-LLMs for Image Captioning - Applications of M-LLMs Across Various Domains
- Exploring M-LLM Algorithms
- LENS: A Framework That Combines Vision Models & LLMs
- IDEFICS: An Open State-of-the-Art Visual Language Model
- GPT-4 (Vision): The famous GPT model with Vision Capabilities
Deep Dive Into Tasks
M-LLMs for Visual Question Answering (VQA)
Visual Question Answering (VQA) is a task in AI where a model is presented with an image along with a natural language question about that image, and it must generate an accurate answer. This task requires the model to understand both the visual content of the image and the linguistic context of the question to provide a relevant response.
M-LLMs are well suited to tackle VQA due to their ability to process and fuse information from both textual and visual modalities. By leveraging advanced deep learning architectures, M-LLMs can analyze the image and question simultaneously, extracting relevant features from both modalities and synthesizing them into a cohesive understanding. It allows M-LLMs to provide accurate and contextually relevant answers to a wide range of questions about visual content.
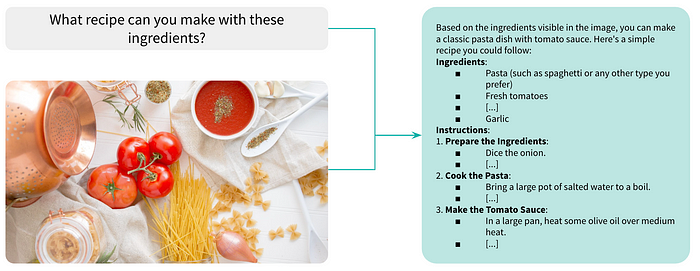
For instance, imagine presenting a M-LLM with an image of a kitchen counter featuring ingredients like pasta, tomato, onion, and garlic, alongside the question, “What recipe can you make with these ingredients?” In this case, the model might generate answers such as, “You can make a classic pasta dish with tomato sauce,” followed by a precise description of the ingredients and the steps of the recipe. The M-LLM achieves this by correlating the ingredients with common recipes, understanding the visual patterns associated with cooking, and generating responses based on what the model learned on culinary practices during its training phase.
M-LLMs for Image Captioning
Image captioning refers to the process of automatically generating textual descriptions or captions for images. Through input fusion of image and text, M-LLMs can generate coherent descriptive captions.
Consider an example of art image captioning using M-LLMs. In this scenario, a M-LLM is tasked with generating captions for a painting depicting a mid-20th century main street with cars at sunset. The model, pre-trained on a vast corpus of textual and visual data, first analyzes the visual features of the painting, recognizing elements such as the sun sinking low over the horizon, casting a warm, golden light across the bustling street, the shadows of the cars across the street, and the silhouettes of buildings, evoking a sense of nostalgia and tranquility as day transitions into night.
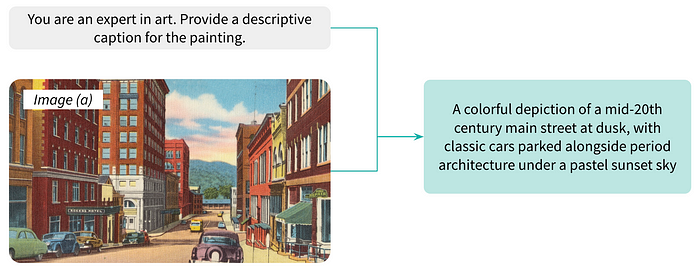
The M-LLM generates a caption that encapsulates the essence of the painting. This caption not only describes the visual content of the artwork but also conveys the mood and atmosphere it evokes, demonstrating the M-LLM’s ability to generate rich and contextually relevant descriptions for art images.
Applications of M-LLMs Across Various Domains
M-LLMs demonstrate a vast potential of applications in various industries:
- Medical Diagnostics: In the medical domain, VQA powered by M-LLMs can assist healthcare professionals by analyzing medical images and answering specific questions about diagnoses, treatment options, or patient conditions. For instance, one would be able to answer specific questions like, “Where is the tumor located?” or “What treatment options are suitable based on this scan?” on an MRI scan of a patient’s brain, aiding radiologists and oncologists in making precise diagnoses and treatment decisions.
- E-Commerce: M-LLMs can be used to improve product descriptions on e-commerce platforms. For instance, a M-LLM could analyze an image of a dress on an e-commerce platform and generate a descriptive caption such as, “Elegant black cocktail dress with lace detailing, perfect for evening events,” providing potential buyers with detailed and engaging information about the product’s features and usage scenarios, thus improving their shopping experience and likelihood of making a purchase.
- Virtual Personal Assistants: The broad understanding of M-LLMs can further improve the performance and usefulness of virtual personal assistants, enabling them to process and execute more complex commands. Combining image captioning and VQA, virtual personal assistants can provide comprehensive assistance to visually impaired individuals by not only describing images but also answering questions about them. For example, a visually impaired user could ask their virtual assistant about the contents of an image they received, and the assistant would both describe the image and answer any related questions.
Exploring M-LLM Algorithms
Numerous M-LLMs have been developed to tackle VQA and Image Captioning. In this section, we delve into three different approaches.
LENS: A Framework That Combines Vision Models and LLMs
The first approach consists in using a framework called LENS (Large Language Models ENhanced to See). LENS has been proposed by Contextual AI and Stanford University. It combines the power of cutting-edge, independent vision modules and LLMs to enable comprehensive multimodal understanding.
LENS works in two main steps:
- Rich textual information is extracted using existing vision modules, such as contrastive text-image models (CLIP) and image-captioning models (BLIP). This text information includes tags, attributes, captions.
- Then, the text is sent to a reasoning module, a frozen LLM which generates answers based on the textual descriptions fed by the vision modules and a prompt.
Here is a diagram of the LENS functioning:
LENS, as a zero-shot approach, stands out by achieving competitive performance comparable to popular multimodal models like Flamingo and BLIP-2, despite not being explicitly trained to handle both images and text.
One limitation observed while testing the LENS approach, particularly in VQA, is its heavy reliance on the output of the first modules, namely CLIP and BLIP captions. For example, when querying, “How many cats are there in the picture?” for the Image (b), the second module (i.e., the LLM) wasn’t able to provide an answer due to varying captions generated by CLIP and BLIP, such as, “There are three cats in the picture” versus “There are fivecats in the picture.”

The adaptability of LENS to diverse language models offers scalability and flexibility, representing a significant advancement in task-solving without additional pre-training and showcasing potential for application in various modalities like audio classification or video action reasoning tasks.
IDEFICS: An Open State-of-the-Art Visual Language Model
The second approach involves an open-source M-LLM known as IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS). IDEFICS, released by Hugging Face, marks the first open-access visual language model at the 80B scale. Based on the architecture of Flamingo, a multimodal model developed by DeepMind in April 2022, IDEFICS is tailored to handle sequences of interleaved images and texts as inputs, generating text outputs with remarkable accuracy.
Indeed, IDEFICS has been trained on a diverse range of data, including sources such as Wikipedia, the Public Multimodal Dataset, LAION, but especially the newly introduced OBELICS dataset. OBELICS is an open, massive, and curated collection of interleaved image-text web documents, containing 141 million English documents, 115 billion text tokens, and 353 million images, extracted from Common Crawl dumps between February 2020 and February 2023. Models trained on these web documents demonstrate superior performance compared to vision and language models trained exclusively on image-text pairs across a range of benchmarks.
Here is a figure showing a comparison of extraction from the same web document:

As explained in the research paper, for image-text pairs, the text associated with each image is often short or non-grammatical. However, for OBELICS, the extracted multimodal web document interleaves long-form text with the images on the page.
As far as its architecture is concerned, IDEFICS follows a structure similar to Flamingo. Flamingo is a M-LLM that processes text interleaved with images and videos and generates text. Images are encoded by a vision encoder and processed by a Perceiver Resampler that outputs a fixed number of tokens. These tokens are then used to condition a frozen language model through cross-attention layers.
Here is a figure providing with an overview of the Flamingo architecture:
IDEFICS was thus inspired by this approach. It contains two main pre-trained components:
- A vision encoder known as OpenCLIP, for extracting image embeddings.
- A language model named Llama v1, for generating text embeddings.
IDEFICS comes in two variants: a large-scale version with 80 billion parameters and a smaller-scale version with 9 billion parameters.
The performance of IDEFICS was particularly notable in VQA tasks, where it demonstrated accuracy in providing answers to questions such as, “How many cats are there in the picture?” for Image (b) where the answer from IDEFICS was “There are four cats in the picture.”
However, in image captioning tasks, IDEFICS tended to generate relatively simple descriptions. For example, for Image (a) was captioned with the straightforward description: “A city street with buildings and cars.”
While these descriptions accurately conveyed the visual content, they were notably concise and lacked additional contextual elements such as the author or publication date.
GPT-4 (Vision): The famous GPT model with Vision Capabilities
The third method entails the use of a proprietary LLM known as GPT-4 (Vision). GPT-4V integrates visual analysis capabilities into the renowned GPT-4 model, allowing users to instruct the model to analyze image inputs provided by the user. This represents the latest advancement in OpenAI’s GPT-4 capabilities.
While the detailed architecture of GPT-4V remains undisclosed, several key aspects are known:
- Training for GPT-4V was finalized in 2022, with early access to the system becoming available in March 2023.
- Similar to GPT-4, GPT-4V underwent training to predict the next word in a document, leveraging a vast dataset comprising text and image data from various online sources and licensed databases.
- The pre-trained model underwent further refinement through reinforcement learning from human feedback (RLHF), aimed at generating outputs preferred by human trainers.
- OpenAI granted early access to a diverse group of alpha users, including organizations like Be My Eyes, which develops tools for visually impaired users. A pilot program conducted from March 2023 to August 2023 aimed to explore responsible deployment strategies for GPT-4V.
In our tests, we observed significant progress in both VQA and image captioning tasks. The model demonstrated impressive precision in VQA, accurately answering questions like, “How many cats are in the picture?” for Image (b) with responses such as “Four cats, all kittens, seen in a wooden basket outdoors.”
In image captioning, it provided structured descriptions for Image (a) like “Vintage Americana: A Colorful Depiction of a Mid-20th Century Main Street at Dusk, with Classic Cars Parked Alongside Period Architecture Under a Pastel Sunset Sky” contrary to IDEFICS. GPT-4V occasionally generated only brief titles without further details. While consistent in accurately describing image content, contextual information such as author, title, or year was not consistently provided.
Conclusion
The landscape of VQA and image captioning using M-LLMs is vibrant and rapidly evolving. With new models being released regularly, both in open-source and proprietary domains, the field is witnessing an unprecedented surge in innovation and experimentation. This dynamism underscores the immense potential and widespread interest in leveraging M-LLMs to advance multimodal understanding and AI applications.
Moreover, as the capabilities of M-LLMs continue to expand, we are now witnessing the emergence of an even more powerful and versatile system, such as Multimodal Retrieval-Augmented Generation (RAG). These models, exemplified by the Multimodal RAG framework, promise to revolutionize not only VQA and image captioning but also a wide range of other multimodal tasks by integrating retrieval-based methods with generation-based approaches. The integration of such innovative frameworks represents a promising direction for further advancing multimodal AI.
You can explore a practical demonstration of the discussed approaches in a project available on the Dataiku public gallery. This blog post was co-written with Camille Cochener.