




{kind=link}
Edge computing is becoming a hot topic these days, and Dataiku is working hard to provide solutions to deploy models on all varieties of machines and environments. This article is for MLOps engineers who are looking for easy ways of deploying models in constrained environments. At the end of this article, readers will understand how they can deploy their models trained on Keras in Dataiku DSS with ONNX runtime.
Why Does One Need Models on the Edge?
Edge computing is about putting the information processing closer to the people producing and consuming it. It has gained traction recently with the ability to deploy powerful machine learning models on many cheap and constrained devices.
For connectivity, speed, cost, and privacy reasons, more and more use cases require putting the model, the sensor, and the data on the same small devices like smartphones or embarked processing units. Calling a centralized server that is responsible for the inference of all the requests of every device requires high scalability, high availability, and low latency.
Take offline or low connectivity / big latency setups — think about offshore platforms, underground parking lots, rural factories, etc. In these cases, calling a remote server is often not a viable option.
For example, let’s assume you are managing a couple of factories. You will need:
- High scalability, because you might have thousands of devices that need to infer at the same time.
- High availability, because your anomaly detection system has to run day and night.
- Low latency, because you want to deliver the anomaly alert as soon as it is detected.
While cloud providers offer such services, they might be very expensive and they come at the cost of privacy and latency. This is where ONNX can help.
Whether you want to perform object detection on a drone, anomaly detection on a factory production line, or fast offline recommendation on a phone, choosing the right deployment solution is key, as there are many obstacles along the way.
Edge Computing + Machine Learning: Why Is It hard?
Deploying machine learning algorithms on the edge is quite difficult. There are too many challenges of model deployment to cover in a single article, but here are a few of the hardest problems to solve (and here's a nice article if you want to dive deeper into the challenges):
- Memory requirements and long inference times. We can mention the difficult requirements of deep learning algorithms in general, and the newest models in particular. In recent years, in order to increase performance, researchers have trained deep learning models on larger datasets, requiring huge memory and long inference times, which is not compatible with constrained environments.
- Coping with different architectures between design and deployment. Another difficulty resides in the variety of development frameworks and the many dependencies that PyTorch, TensorFlow or caffe models can have. Tracking every used package and adapting the release strategy while covering as many devices and environments can become a nightmare.
- Portability between edge devices. The last challenge we will mention is portability. If you are inferring on different types of sensors or imagine changing at some point. Some sensors may support Java Virtual Machines while others might have limited memory and instructions sets or architectures requiring reduced development kit. Starting a new model development cycle only to cope with a different environment is extremely costly.
All these obstacles can seem overwhelming, but bear with me.
By the end of the article, you will know how to infer a model that can run in a minimal setup with only one Python package dependency. We will train a simple model on Keras, convert it in the ONNX format, and infer it in Python. We will also showcase how our new plugin can simplify the whole machine learning cycle on Dataiku DSS. But first, let’s look at what ONNX is.
What Is ONNX?
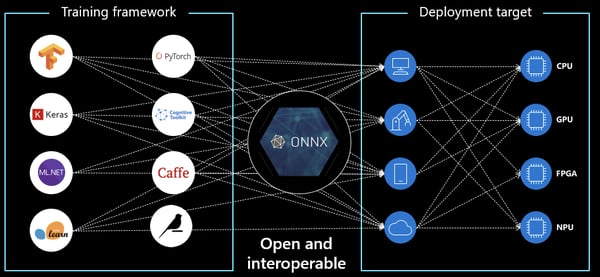
Graphic adapted from this source
“ONNX is an open format built to represent machine learning models. ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers”. [Source]
Concretely, after converting your model to a .onnx file, you will only need one dependency to run inference : the ONNX runtime.
ONNX was created in 2017 by Facebook and Microsoft to enable interoperability between common deep learning frameworks. Microsoft actively develops the ONNX runtime with the ambition that all supported models should run faster on the ONNX runtime than in their origin framework. You can infer in python, C++, Java, C#, Javascript, etc.
Other specific runtimes exist. For instance, one could use the Qualcomm SDK for mobile chips or OpenVino for intel powered hardware. You can also infer faster on GPU’s thanks to hardware accelerations like tensorRT.
Learn About:
How Can ONNX Help?
As so much research is being done on deep learning, many frameworks have emerged in the past few years, and there is no consensus among data scientists on which one should prevail. When researchers release the code along with their paper, they usually open source a version compatible with a single framework. Therefore, data scientists have to switch between frameworks, setups, CPUs and GPUs, local and cloud... But then comes the time to deploy on constrained environments — this is when a unified format can help.
Being able to translate many framework formats to a single format while having a limited and fixed set of dependencies allows data scientists to have the liberty to experiment widely while guaranteeing MLOps that they will not struggle to deploy the models.
In this tutorial, we will start with a model trained on Keras, but most frameworks (Tensorflow, Pytorch, Caffee) have conversion to ONNX libraries, and while the code would be different, the process would be very similar.
We will work with a model trained for binary classification on the famous dog breed Kaggle classification challenge. Again, the code would be very similar if you choose another Keras model. Let’s first look at how we can convert this Keras model.
If you want to know more about training deep learning models in the Dataiku DSS user interface you can have a look at this tutorial.
If you want a good example of Keras model trained for this challenge you can have a look at this notebook.
How to Convert a Keras Model to ONNX?
Conversion of Keras models to ONNX is very easy thanks to the keras2onnx library. It supports every standard layer and even custom and lambda layers thanks to bindings with the tensorflow-onnx library.
Starting from :
- a keras model that was saved into a "model.h5" file with keras model.save() method.
- an output path : "output_path" where to store the onnx model
The code is the following :
from keras2onnx import convert_kerasfrom keras.models import load_modelkeras_model = load_model("model.h5")onnx_model = convert_keras(keras_model)with open(output_path) as f: f.write(onnx_model.SerializeToString())tensorflow>=1.5.0,<2.0.0
keras>=2.1.6, <=2.3.1
keras2onnx==1.6.1
onnx==1.6.0
There are many possible runtimes, implemented in different languages. You can find, for instance, an example for C++.
After converting your model the last thing needed is to actually infer.
How to Infer on ONNX Runtime
After installing onnxruntime on your device (which is the difficult part), writing your scoring engine will seem very easy.
Starting from :
- A csv file with your input at path "input.csv" that is in float32 format
- Your converted model at path "model.onnx"
- The name of your model’s input : "main"
The code is the following :
from onnxruntime import InferenceSessionimport pandas as pddf = pd.read_csv("input.csv")sess = InferenceSession("model.onnx")outputs = sess.run(None, {"main": df.astype("float32")})[0]It is as simple as that. You can run this code on many architectures (x64, x86, ARM32, ARM64) on various OS, and you can even expect faster inference for non-batch predictions.
How Can the Dataiku ONNX Plugin Help?
If you trained your deep learning model on Dataiku DSS, conversion can be even easier with the release of our ONNX exporter plugin (released with version 8.0). You only need to click on the saved model and then on Export to ONNX in the right sidebar. Choose the output folder, the output model path, and run the macro:
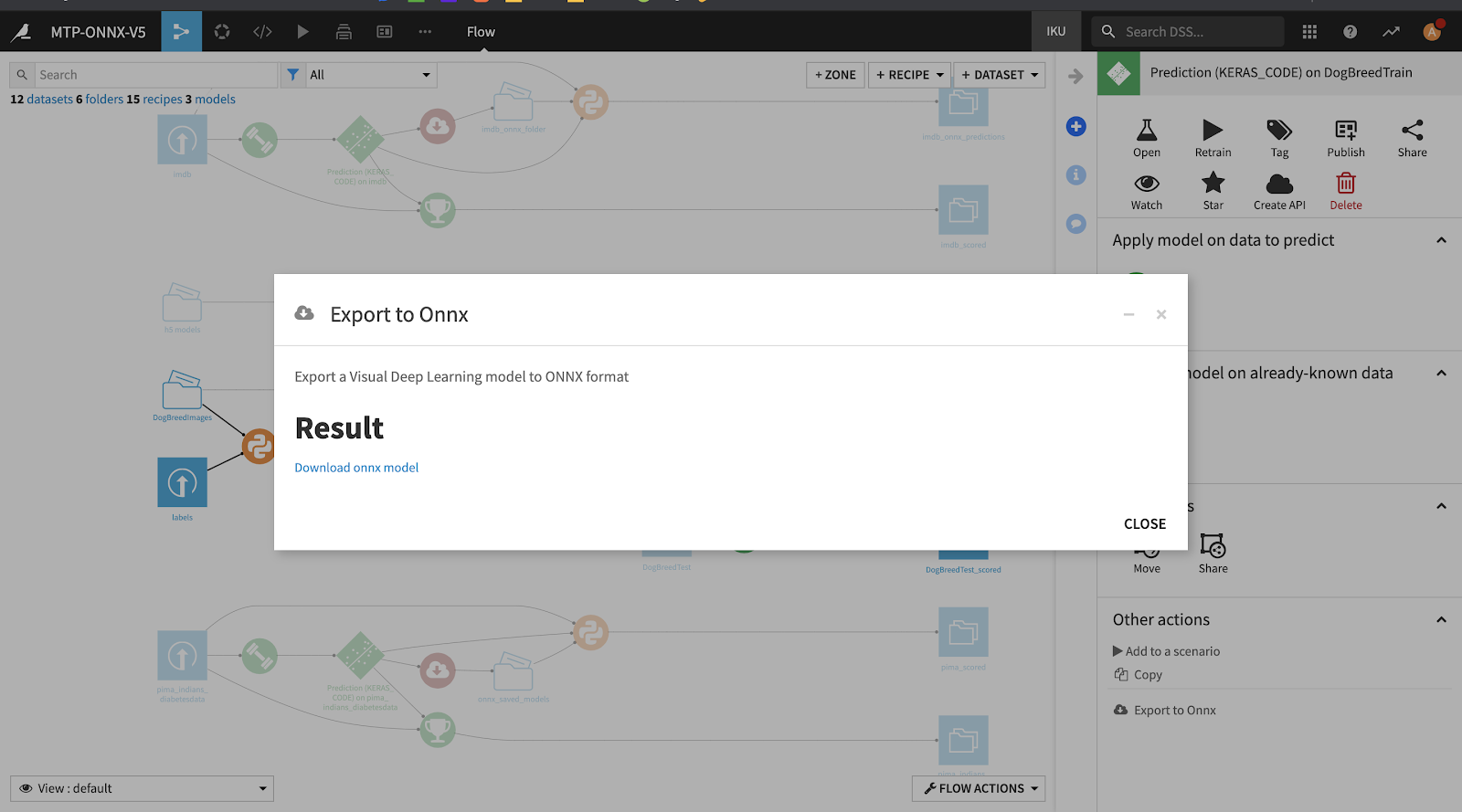
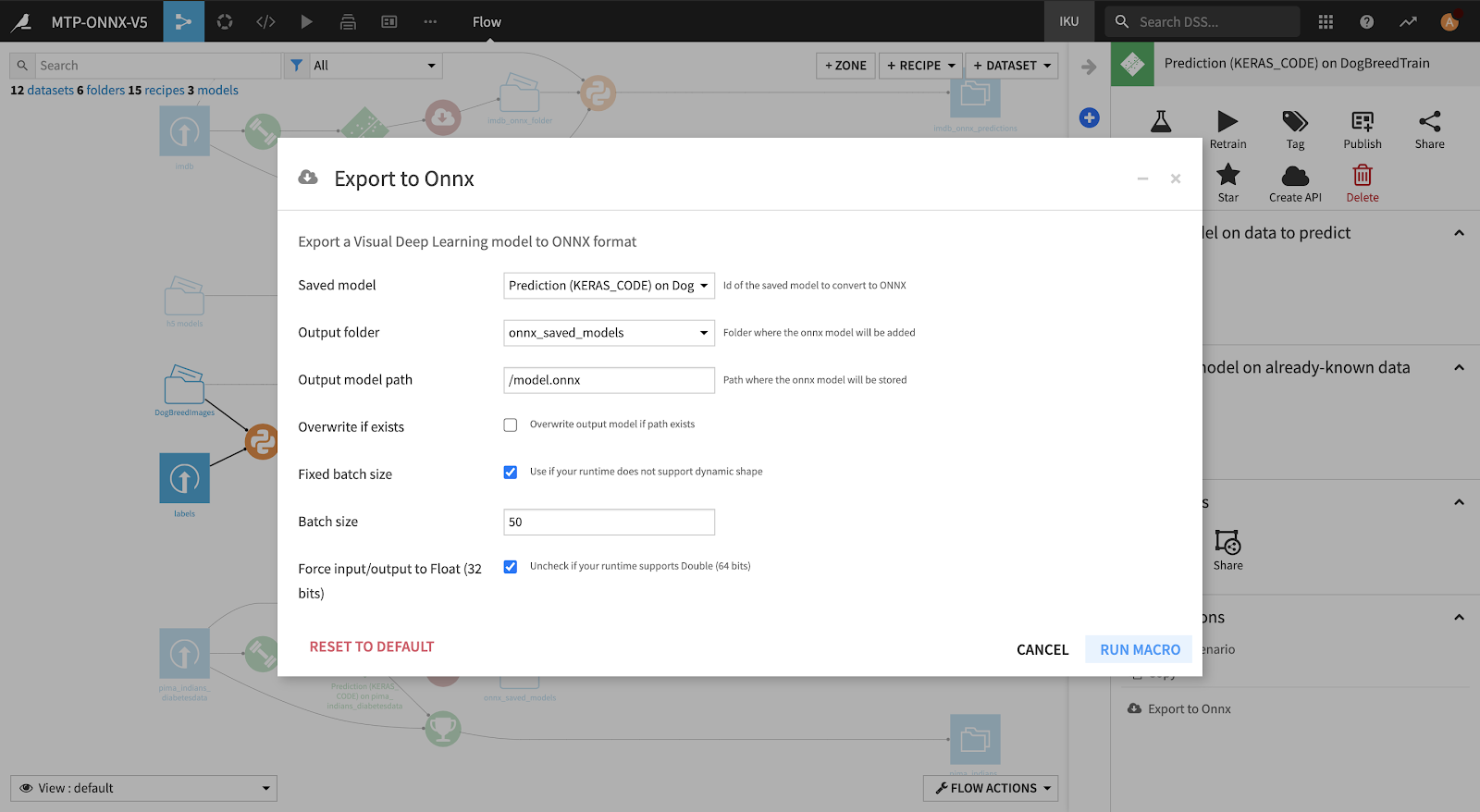 It produces a link to download the model in ONNX format:
It produces a link to download the model in ONNX format:
Conclusion
Thanks to all the readers that read that far. I hope that this article gave you a first overview of how ONNX can help you deploy models on the edge. Don’t hesitate to reach out if you want to know more about how Dataiku can help for your particular deployments.