




{kind=link}
In the realm of data preparation and business intelligence (BI), the collaboration between Dataiku (a Google Cloud Ready - Cloud SQL Partner) and Google Cloud SQL presents a transformative opportunity for organizations seeking to optimize their data workflows and glean actionable insights. Dataiku's data preparation capabilities and Google Cloud SQL's efficient data storage and retrieval come together to streamline data processing and elevate BI initiatives. This blog post delves into the data preparation challenges organizations commonly face and how to overcome them with Dataiku and Google Cloud SQL, resulting in improved operational efficiency.

Challenge 1 - Data Integration and Transform Complexity:
Integrating data from various sources, including databases, APIs, flat files, and streaming platforms — while maintaining data quality and consistency — can be complex. As the scale and diversity of data increase, so does the complexity of the transformation process. A significant challenge is ensuring smooth Extract, Transform, and Load (ETL) processes that handle different data formats, structures, and update frequencies.
Overcoming the Challenge
Dataiku is pivotal in simplifying data integration by offering comprehensive features and tools that streamline the process from raw data to analysis-ready datasets. Here's how Dataiku helps:
- Connect to Leading Data Sources Using Built-In Connectors: Dataiku provides pre-built connectors to dozens of leading data sources both on-premises and in the cloud, including APIs, Google Cloud Storage, SQL databases, NoSQL databases, Google Workspace Apps, etc., and supports a wide variety of file formats.
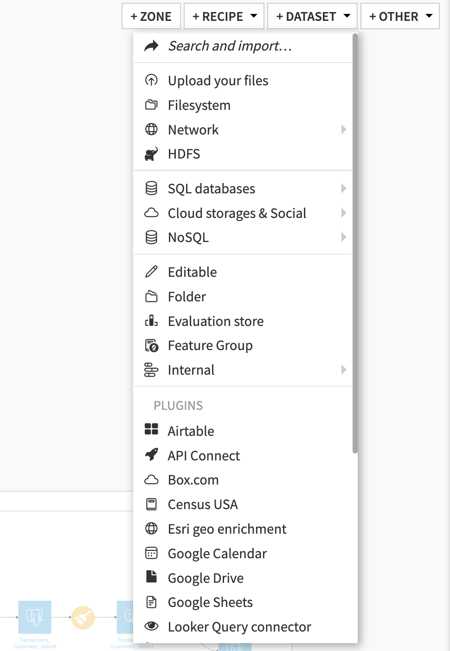
Figure 1 - The screenshot is captured by clicking the “+Dataset” icon in a Dataiku Project Flow. It shows different data sources that can be added in Dataiku using native connectors.
- Data Preparation and Enrichment: The Dataiku flow visually represents a project’s data pipeline. It’s the central space where coders and non-coders view and analyze data, add recipes to join and transform datasets, and build predictive models. Take advantage of CloudSQL scalable compute by running visual and SQL code recipes in the database.
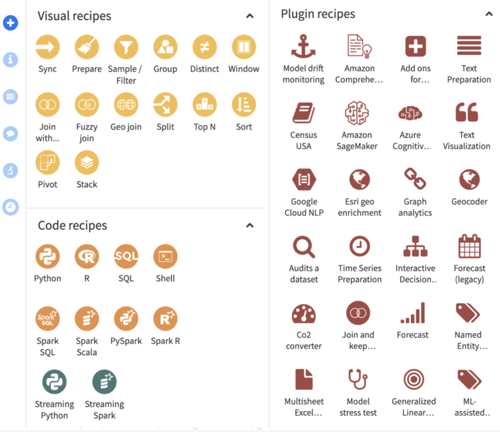
Figure 2 - Dataiku Flow Page with the list of different visual, code, and plugin recipes that can be applied to a dataset.
- 100 Built-In Data Transformers: The potent prepare recipe includes 100 built-in data transformers for common data manipulations like binning, concatenation and strings manipulation, currency and date conversions, geo-enrichment, and reshaping.
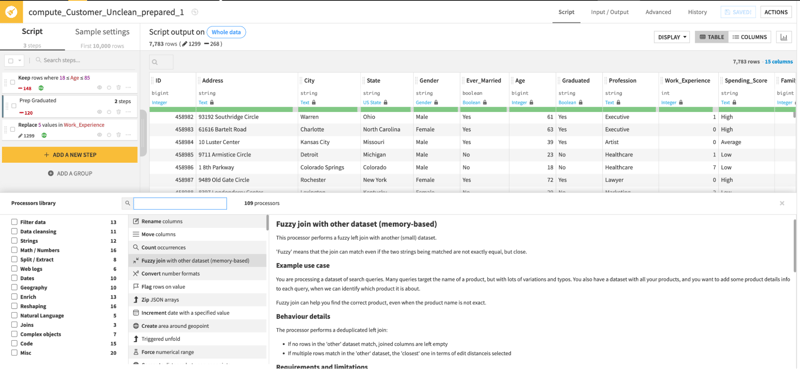
Figure 3 - Dataiku prepare recipe configuration page showing the list of transformers that can be used for data preparation
- Dataiku AI Prepare (coming soon): Preparing data has traditionally been the domain of data analysts, but with new Dataiku AI Prepare, analysts and business users describe the preparation steps they want, and the system automatically creates those steps as part of visual recipes. The results are easy to review for everyone using the data preparation job.
Challenge 2 - Data Quality and Cleansing:
Ensuring data accuracy, completeness, and reliability is a constant struggle. As teams automate data pipelines, they are exposed to risks, such as ingesting poor-quality data without knowing it, which could affect output datasets, apps, and dashboards.
Overcoming the Challenge
In Dataiku, data quality can be ensured visually with a combination of metrics and checks. You first use metrics to measure your data, then use checks to ensure those measurements meet some expectations about the data. Dataiku metrics and checks offer valuable capabilities to enhance data quality, accuracy, and monitoring within the Dataiku platform.
- Data Quality Assurance: Dataiku metrics and checks enable you to define and implement data quality metrics and validation rules for your datasets. This helps ensure that your data adheres to predefined standards and quality benchmarks. By setting up checks for completeness, accuracy, consistency, and other data quality dimensions, you can identify and rectify issues early in the data pipeline, leading to more reliable and trustworthy insights.
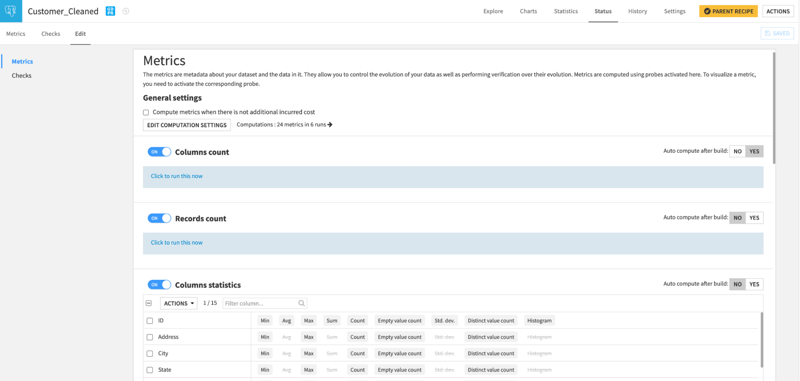
Figure 4 - Dataiku dataset metric configuration page. Users can use multiple pre-built visual metrics and/or create a custom one using SQL or Python.
- Automated Monitoring and Alerting: Dataiku metrics and checks, combined with Dataiku Scenarios, can establish automated monitoring processes that continuously assess data quality in real-time or on a schedule. The platform can automatically trigger alerts or notifications when data quality thresholds are unmet, allowing you to address issues and maintain high-quality data promptly. This proactive approach helps prevent downstream errors and supports timely decision-making.
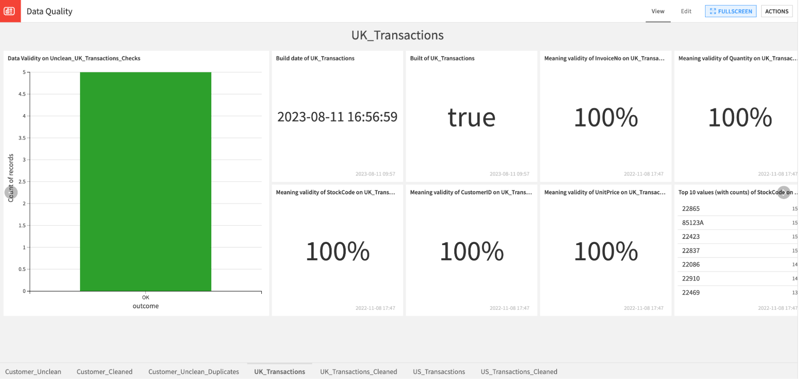
Figure 5 - Dataiku dashboard displaying data quality metrics and checks. Users can store datasets metrics and checks as separate datasets to maintain data quality history and build charts and dashboards for monitoring.
- Enhanced Data Governance: Dataiku metrics and checks contribute to a more robust data governance framework by providing visibility into the quality and health of your data assets. You can create data quality dashboards and reports that offer insights into the status of your data, making it easier to track improvements, measure compliance, and communicate data quality metrics to stakeholders. This transparency promotes accountability and supports data-driven decision-making across the organization.
Incorporating Dataiku metrics and checks into your data workflows can improve data quality, reduce errors, and create more efficient data management processes, ultimately bolstering the reliability and effectiveness of your analytics and decision-making endeavors.
Challenge 3 - Scalability and Performance:
Data preparation systems must scale seamlessly to handle the load as data volumes and processing demands increase. Maintaining high-performance data transformation processes and optimizing data pipelines to handle large datasets and complex transformations can be daunting.
Overcoming the Challenge
Google Cloud SQL offers several advantages regarding scalability and performance for data preparation and database management. Dataiku’s integration with CloudSQL enables users to use in-database, including but not limited to SQL recipes, visual recipes, chart and dashboard live engines, metrics, and checks. Here are two key pros of using Cloud SQL in this context:
- Horizontal and Vertical Scalability: Cloud SQL provides horizontal and vertical scalability options. Vertical scalability involves increasing your database instance's computing power and resources, allowing you to handle higher workloads without significant changes to your application code. On the other hand, horizontal scalability will enable you to add read replicas to distribute read operations across multiple instances, improving performance for read-intensive workloads. This flexibility ensures that your database can scale effectively to accommodate growing demands.
- High Performance and Availability: Google Cloud SQL is built on Google's high-performance infrastructure, providing low-latency access to your data. The service uses advanced storage solutions, such as SSD-backed storage and in-memory caching, to deliver fast read and write operations. Cloud SQL offers features like automatic failover and built-in replication, which enhance availability and minimize downtime. These capabilities ensure that your applications can deliver responsive user experiences even during peak usage.
Putting It All Together
By harnessing the strengths of Dataiku and Google Cloud SQL, organizations can unlock the true potential of their data assets, driving innovation and achieving data-powered success in an ever-evolving digital landscape. The path to data intelligence has never been more apparent, and with Dataiku and Google Cloud SQL as your guiding lights, the possibilities are limitless.
How to Connect CloudSQL(PostgreSQL) to Dataiku?
Follow the steps here to set up the Cloud SQL Postgres Database in Dataiku.
Dataiku supports the full range of features on Cloud SQL:
- Reading and writing datasets
- Executing visual and SQL recipes in-database
- Using as live engines for charts and dashboards
- Using as probe engines for metrics and checks
- Restricting access to connections at individual users or user groups level