




{kind=link}
This is a guest post from our friends at SAEGUS. Founded at the end of 2014, SAEGUS allies the innovation ability of a start-up and the service level of a consulting firm, to put digital and data valuation at the core of its customers’ strategy. In addition to the founders’ experience gained from working with major French companies comes a multidisciplinary team of talents able to speak all languages of data: from business strategy to AI adoption, through data science expertise, MLOps, and data analytics.
Data Science, From Enthusiastic Commitment to Frustrating Results
A growing interest in data science and artificial intelligence (AI) has been observed over the past decade, both in professional and private spheres. A variety of uses have appeared, such as selecting sitcom scenarios to gain viewers, writing articles for the press automatically, developing stronger-than-human AI for particularly difficult games, or creating smart chatbots to assist customers. Furthermore, numerous influential actors in the technology space demonstrate strong enthusiasm towards AI:
"AI is going to be the next big shift in technology." - Satya Nadella, Microsoft CEO
"It is a renaissance, it is a golden age." - Jeff Bezos, Amazon CEO
AI [...] is more profound than [...] fire or electricity." - Sundar Pichai, Google CEO
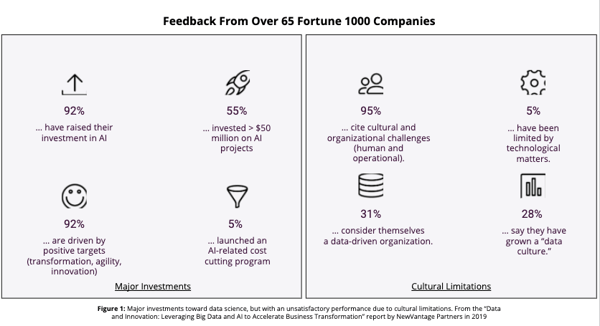
Beyond these promises, there are significant investments being made in data science and AI. Both retrospective and prospective figures are massive: the market was worth $20.7 billion in 2018 and the compound growth is expected to reach 33% by 2026, according to this study. The report “Data and Innovation: Leveraging Big Data and AI to Accelerate Business Transformation” by NewVantage Partners in 2019 showed that the majority of the 65 companies investigated react proactively and positively to data science and AI (see Figure 1 below, left panel).
Furthermore, numerous countries are investing significant resources to develop AI initiatives: the Digital Europe funding program dedicated 2.5 billion euros to AI research, the DARPA funding campaign raised two billion dollars to fund the next wave of AI technologies, and China declared its goal to lead the world in AI by 2030. Altogether, these observations argue that most stakeholders are aware of the importance of data science and AI, and commit to its development in their activities.
Despite these dynamic trends of investment and constructive attitudes from companies, there are also some alarming — sometimes even shocking — observations regarding the deployment of data science and AI. Indeed, the rate of data science projects which do not succeed may be as high as 85% or 87%. This low performance does not only affect young companies — it can also be observed within data-mature businesses.
The study “Artificial Intelligence Global Adoption Trends & Strategies” conducted by the IDC in 2019 among 2,473 organizations exploiting AI in their operations reported that one-fourth of them have a failure rate of AI projects higher than 50%, while another one-fourth of them consider having developed an AI strategy at scale.
The report of NewVantage Partners mentioned above has also studied the nature of the obstacles met by companies while deploying data science and AI programs: the main limitations appear to be cultural rather than technological (see Figure 1 above, right panel). In this sense, this study reports that 77.1% of consulted companies have identified AI adoption by business experts as a major challenge.
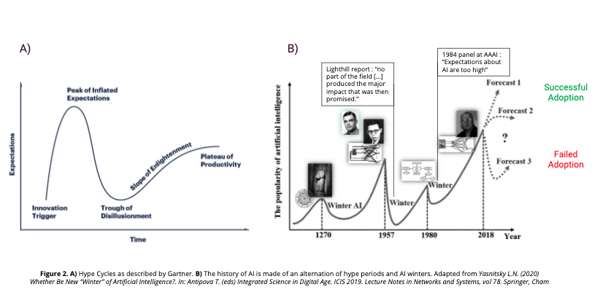
To sum up, many have high expectations for data science and AI, given the media coverage and the level of investment. However, in practice, its performance is low and restrained by cultural obstacles. This contradictory gap between expectations and the “reality” is not rare in the technology sector, and can lead to a “trough of disillusionment” as described by Gartner in “hype cycles” (see Figure 2 above, panel A). In fact, AI has already fluctuated between such highs and lows three times. In the history of AI, hype periods of intense investment and development were followed by an “AI winter”, with no activity in the field (see Figure 2 above, panel B).
Then, the next question we should ask ourselves is: are we about to live a fourth “AI winter” with a “data science bubble burst”, or will the field continue to flourish? The answer will depend on us, and we firmly believe that adoption will be a key ingredient in the success or the failure of AI in the coming decade. This article describes the different cultural obstacles to successful data science and AI, and, in light of this analysis, presents a systemic and organizational lever to address these obstacles and foster adoption at scale: a new position named the “Data Adoption Officer.”
The Cultural Pains of Data Science
In the following sections, we will look at a variety of cultural obstacles met during the deployment at scale of data science and AI. To simplify the complex landscape, the limitations listed below are grouped along four main dimensions: the data scientists, the resources, the hermeticism of data science and AI, and MLOps.
Pain 1 – Data Scientist, The Sexiest Trickiest Job of the 21st Century
While the data scientist has been advertised as the sexiest job of the 21st century by an article in the Harvard Business Review, it may also be one of the trickiest positions for many reasons described below, including skill shortages, heterogenous profiles, an ill-defined job description, and significant turnover.
Skill Shortages
In their study Artificial Intelligence Global Adoption Trends & Strategies, the IDC reports that skill shortages are identified by companies as a major cause of AI project failure. Although numerous graduate programs in data science and AI have appeared in the last few years, the need for skillful data scientists is not fulfilled. In August 2018, LinkedIn stated that there was a shortage of 151,000 data scientists in the U.S.
Aside from this quantitative shortage, there is also a qualitative one. Since the data science discipline is fairly young, most senior data scientists come from other fields. Thus, while there are more and more juniors arriving on the labor market, companies struggle to find experienced profiles to drive a dynamic vision and strategy and enable skill transfer.
Heterogeneous Profiles
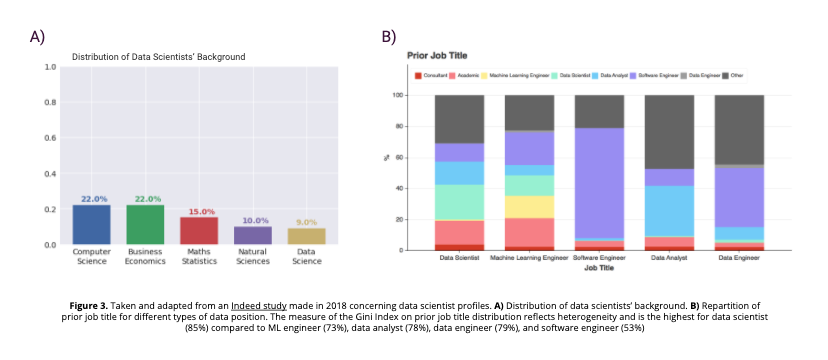
One of the consequences of having many reconverted data scientists on the labor market is the strong heterogeneity of profiles, both in terms of educational background (see Figure 3 below, panel A) and previous experience (see Figure 3 below, panel B). Every field has its own culture, made of distinct methodologies and knowledge bases. Similarly, the other job titles have their own roadmap, scope and goals.
Furthermore, a Kaggle poll showed that 66% of the participants learned data science on their own (likely overestimated due to selection bias), which contributes to the diverse nature of this discipline. Without a doubt, this diversity may generate interesting synergies and values. However, it also slows down the composition and acquisition of a common frame of reference. The data science community has a vital need of social cohesion to consolidate its unity.
Data Scientist, an Ill-Defined Position
Data scientists are expected to have numerous talents, from hard sciences to soft skills through business expertise. Altogether, the ideal data scientist endowed with all these abilities rather looks like a “five-legged sheep” (see Figure 4 below). Such a mix of objectives, roles, and functions makes it difficult for data scientists to handle all these aspects at once. And if data scientists are five-legged sheep, then a lead data scientist and a Chief Data Officer (CDO) may perhaps be a chimera. Indeed, NewVantage Partners reported in their 2019 study “Data and Innovation: Leveraging Big Data and AI to Accelerate Business Transformation” that the CDO’s role is changing gradually and is not well described, leaving the CDO rather helpless.
Significant Turnover
According to a study published in the Training Industry Quarterly, an employee needs one to two years to be fully productive when starting a new job. Given the numerous challenges that data scientists face in their duties, as presented earlier, this may rather be two years. A global poll realized by KDNuggets among data scientists revealed that half of the participants stayed at their previous role for less than 18 months. Such a turnover in data teams is a productivity killer. However, the participants stated that they were willing to stay longer in their current position.
Since KDNuggets’ survey, however, it seems that the length of a data scientist position has increased: the average tenure at a previous data science job is 2.6 years for data scientists who took part in a survey conducted by Burtch Works and who changed jobs in 2018 (representing 17.6% of the participants). Even if there is a clear improvement since 2015, the average tenure for a data scientist seems still neatly below those of other jobs in the US (4.6 years according to the Bureau of Labor Statistics). Below is a non-exhaustive list of some reasons that data scientists change jobs:
- Mismatch between expectation and reality
- Company politics
- Overloaded by data duties, which most of the time are not machine learning-related
- Working in isolation
- Lack of macroscopic vision concerning the roadmap
- Infrastructure and/or data not sufficiently mature (cold start in ML)
Losing an asset on which a company has invested negatively impacts a data team’s activity. Thus, retaining data scientists should be a major concern for companies. To help retain talent, companies may want to consider Happiness Management, which is closely related to adoption and the points listed above, since: “One is not happy because one succeeds, one succeeds because one is happy.”
Pain 2 – Suboptimal Usage of Resources
Resources have different origins, and can be split into three types: tools, data and humans. All of these resources suffer from suboptimal usages as described below.
A Multiplicity of Tools Penalizing Quality
The data lifecycle is not a long, quiet river and is, rather, composed of numerous stages. Each of them can be categorized into different perimeters, either functionally, technologically, or thematically. And for each perimeter of each stage, numerous solutions exist. Therefore, the data and AI landscape in 2019 in terms of tools was fairly crowded.

This multiplicity of tools obliges data teams to include in their pipeline a diversity of technologies, each of them having their own complex functioning. It requires a great discipline and expertise to consolidate the best practices across space and time for each technology to reach a utopian “generalized best practices.” The reality is often far from this, inducing decreased performance and even hazards.
The Data Management Bottleneck
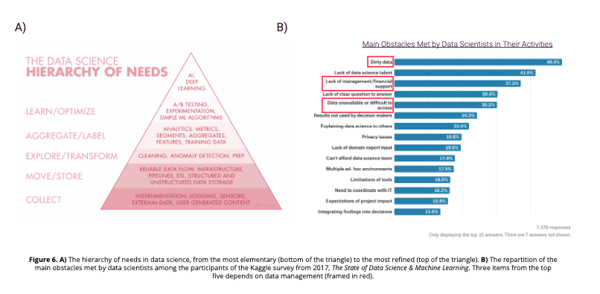
Greg Hanson from Informatica has a great (overstated) sentence which summarizes the following paragraph: “The hardest part of AI and analytics is not AI, it is data management.” As a matter of fact, data science and AI do not escape the GIGO constraint: Garbage In, Garbage Out. In other words, the quality of the information coming out cannot be better than the quality of information that went in. The inputs that AI models receive come from a long sequence of actions (see Figure 6 below, panel A), with possible alterations of quality at each step, justifying Greg Hanson’s slogan.
Data quality is precisely a great matter of concerns among data scientists. In the Kaggle survey from 2017 named "The State of Data Science & Machine Learning," three of the top five obstacles encountered by data scientists are related to data management (see Figure 6 below, panel B). Finally, data management can sometimes be overflowed by short-term compelling duties, blocking any attempt to develop a long-term vision/program to widen the data horizon. Since most of the work of a data scientist depends greatly on efficient data management, its inertia can be an import limitation.
Blindfold Human Resources
Knowing quantitatively what oneself knows is not easy and requires rare metacognitive skills. Therefore, knowing what a team knows, through its individuals and as a group is even more difficult. This is particularly true for data science, which involves a vast knowledge grounded in many fields (statistics, computer science, mathematics, machine learning, etc.) and completed by the need of a business expertise. Skills management may greatly benefit the data science activity of an entity.
Besides, it is echoing the observations of section A with regards to happiness management, since it may facilitate and optimize the upskilling track of each data scientist. It may also stimulate the R&D activities by identifying blind spots to investigate, improve recruitment by matching candidates with existing assets, and identify the priority needs in terms of external services providers (consulting, expertise, etc.).
Pain 3 – A Hermetic Field Preventing Global Adoption
Since data science and AI are complex subjects, there is a risk of rejection by the population and business experts. This hermetic field may either generate fears or a disinterested posture. Sometimes, it is the structure of companies made of silos which slow down collaboration possibilities. Because of this, it is important that the data community tries to include everyone in its activity, to prevent any inequalities enhancement. These ideas are discussed below.
Fear of the Unknown
Change can be frightening, a fortiori when it is not intelligible. Because AI is complex, and sometimes suffers from a black-box effect, the related new technologies generate fear as observed in a survey ordered by Saegus, in which 60% of the participants reported such worries. Beyond the “unknown” factor, many other characteristics may create anxiety in the population. For instance, people dread robots which may replace them at work, similarly to the mechanization of agriculture (50% of the working force was working in agriculture in 1870, when it is 2% nowadays). This is not just a delusion: 47% of jobs may potentially be replaced (or augmented) by AI in the U.S. according to this report.
Another source of fear is related to possible dysfunctional AI, as advertised by numerous bad buzz: an autonomous vehicle that kills a pedestrian in Arizona in 2018, the inability of almost all the models to predict the victory of France at the soccer World Cup in 2018, some smart speakers which get activated loudly in the middle of the night, etc. In addition, when AI models are not dysfunctional, they might just escape our control: biased algorithms favoring male candidates in Amazon’s recruitment process, two chatbots collaborating to trade goods which build their own non-human language, or Microsoft’s chatbot Tay which published violent content on Twitter.
If the models survive also these downsides, another risk is the misuse of these technologies: autonomous weapons such as the Google’s Maven project, social manipulation during elections, mass surveillance and privacy violation, etc. Some of these concerns are legitimate, and many scientists have shared them, such as when Stephen Hawking said, “Success in creating effective AI could be the biggest event in the history of our civilization. Or the worst.”
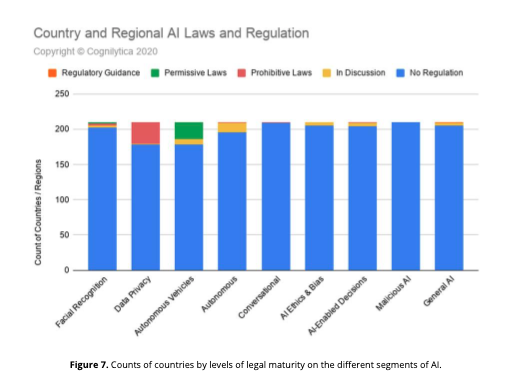
There is still a lot of progress to be made to protect users and people from these risks since there is a legal vacuum on most of the related topics (see Figure 7 below). It is a duty of the data community to take part in the legal framing of AI. The corresponding protection may facilitate the global adoption of AI.
The Clash of Cultures
It is essential that data teams and business experts collaborate fluidly, which is currently not always the case. A survey by Spiceworks showed that seven in ten IT professionals considered collaboration as a major priority. In the worst-case scenario, data scientists miss the ability to take advice from business experts while the former does not take into consideration data-driven elements provided by the latter to take a decision (see Figure 8 below, Panel A).
Most of the time, there is some good will from both sides, but the difficulties to collaborate can still emerge from existing silos in the company which is often the case. Statistics and consequences are presented in the panel B of Figure 8 below: silos are often harmful for developing at scale AI solution. Breaking these silos is the main solution to this constraint.

Data Science and Inequalities
Digital inequalities tend to replicate social inequality in terms of socio-economic status (education, gender, age, place of residence, professional situation, etc.). For instance, in France, the Insee reports in a study that:
- 15% of the active population has had no connection to internet in a year.
- 38% of users lack at least one digital skill (search, communication, software manipulation, problem solving).
- 25% of the population does not know how to get information online.
With such skills gaps on digital basics, the risk that AI will strengthen inequalities is real. Having two “parallel worlds”, with data-aware people on one side, and the others on the other one, can only be detrimental to data science. AI inequalities would be particularly strong on the following dimensions:
- Level of education
- Access to work
- Access to information
- Access to technologies
- Biased AI favoring a ruling minority
In business, such inequality may appear with regards to transgenerational issues, as young people become more fluent in these technologies. Generally speaking, it is critical to advocate for an inclusive data science, serving everyone, with no one left behind.
Pain 4 – The Long Path Full of Risks Towards Value Generation Along Project’s Lifecycle
The integration of the DevOps culture into data science and AI projects definitely deserves to be briefly mentioned here, but the gigantic technical aspect of MLOps will not be explicitly covered. Below, only general and cultural factors constraining data science from blooming and associated with MLOps are presented: the peculiarities of machine learning which render DevOps adaptation to AI not that simple, the youthfulness of the MLOps tools, and the difficult cohabitation of agile methodologies and data science.
Machine Learning and DevOps
As mentioned previously, an AI project is a succession of numerous stages, from ideation to industrialization through POC. It is beneficial to manage systematically and automatically projects throughout its entire lifecycle, and in this line of idea, DevOps may be inspiring. However, the specificities of machine learning complicate the application of DevOps principles in an AI project. The peculiarities of ML with regards to DevOps are presented in the table below (see Figure 9 below).

MLOps Tools on Track of Development Paths
Because of the AI and ML specificities presented in the previous paragraph, dedicated methodologies and tools are needed, called MLOps. This discipline is even younger than data science. As a consequence, the existing MLOps tools — even if really promising — are still on track of development paths. For instance, corresponding tools may be notable: ModelDB, Kubeflow, MLflow, Pachyderm, DVC.
Because of their youthfulness, they would benefit from longer-term testing. From a general point of view, most of these tools were the results of local initiatives (sometimes redundant). Up until now, no methodological standards have been agreed upon in the community. One effect is that there is often a lack of interoperability between these technologies.
Agile Methodology and “Clumsy” Data Science
Agile methodologies are essential in many cases to facilitate collaboration, to converge to a solution satisfying everybody, while improving the productivity of the team. They are particularly used in the IT sector. However, some data scientists consider their work as incompatible with the methods. Indeed, in addition to the specificities of AI and ML presented previously, it is often really difficult to estimate the duration of some tasks — such as data wrangling — and consequently may inactivate the concept of sprint.
Furthermore, some intermediate results that cannot be anticipated may be central to a Go/No-Go decision which may abruptly interrupt a project. Whatever the reasons leading to a non-agile methodology (if any) within a data team, beyond a possible suboptimal way of working, it may impact negatively any attempts to collaborate with other departments.
Conclusion
To sum up, while significant investments are made to develop data science and AI in most business sectors, the rate of successful AI projects is unacceptable. The difficulties met by companies to deploy AI at scale are mainly cultural and can be described along four dimensions.
The first dimension is related to the data scientist population, which is not easy to handle: skill shortages on the labor market, heterogeneous profiles, overly ambitious job descriptions, and high turnover. The second dimension is associated with the suboptimal usage of resources, including tools, data and talent.
The third dimension corresponds to the siloed nature of data science and AI, which generates fears, cultural clashes and inequality, stifling collective data adoption. Finally, the fourth dimension is represented by MLOps issues: the specificities of AI that complicate the application of DevOps principles, young dedicated tools that are still in development, and, sometimes, a lack of agility in AI projects.
This diagnostic is absolutely necessary to anticipate any actions to overcome cultural obstacles. One may employ a specific and stand-alone solution for each obstacle, but this may not be the most efficient approach — low accountability, unbalanced agenda, lack of coordination, etc. This is why at Saegus, we have developed a holistic solution: an ingrained and organizational lever addressing every obstacle and fostering adoption at scale. This is a new job named the “Data Adoption Officer.” Our motto concerning data adoption is “Technological evolution must be complemented by cultural progress. Adoption is a major issue, so for individual and collective fulfillment and deployment at scale teams need an efficient, fruitful, inclusive, and humanistic data science practice.”