




Imagine that you’re just about to buy a new shirt at your local big box retailer. “Do you have an account with us?” asks the cashier. You think you may have signed up before, but can’t really remember.
“Okay, we can look it up! I just need your phone number,” they say.

You call out your number, the cashier enters it, and discovers your number is not yet associated with a loyalty account. You decide that you’ll go ahead and set one up. Turns out you already had a loyalty account, but the cashier entered your phone number incorrectly — he switched around a two and a five.
Now this duplicate data is sitting in a customer database somewhere alongside thousands of other similarly inaccurate entries.
As any data analyst will tell you, these types of data inaccuracies are commonplace. Along with phone numbers off by a couple of digits, other common data mismatches might include variations on spelling a name or address, general typos, case differences, or differences in numeric precision.
Joining datasets is one of the most common data preparation and analysis tasks, but with these types of data errors you may end up with columns of missing values for records where the keys were not exactly the same. Cleaning and transforming entries can take countless hours to complete. In fact, data scientists are still spending nearly half of their time on data preparation tasks. Executing a fuzzy join with a fuzzy matching algorithm can get data prep work done faster.
What Is a Fuzzy Matching Algorithm?
A fuzzy matching algorithm uses approximate string matching to execute a fuzzy join between two datasets. With a fuzzy join, it’s possible to join data that has an inexact match. This can be incredibly useful and timesaving when you want to quickly join data without performing data prep that would force the keys to match.
Fuzzy matching algorithms use the distance threshold between values in a dataset — distance basically being defined as the variation between two values — along the characteristics of the value (text, numeric, geopoint, etc.).
For example, when joining text columns, you could use the following types of distance in a fuzzy matching algorithm:
- Damerau–Levenshtein - The Damerau–Levenshtein distance between two words is the minimum number of operations (consisting of insertions, deletions, or substitutions of a single character, or transposition of two adjacent characters) required to change one word into the other.
- Hamming - A distance between two strings of equal length is the number of positions at which the corresponding symbols are different.
- Jaccard - A distance, which measures dissimilarity between sample sets of characters from joined strings. Calculated as a size of a set containing common characters divided by a size of a set containing all characters from both strings.
- Cosine - A distance is measured by converting strings into vectors by counting characters appearing in both strings and then calculating a dot product of two vectors.
When joining numeric columns:
- Euclidean - also called Pythagorean distance or the difference between Cartesian coordinates
When joining geopoint data:
- Geospatial - the geographical distance between any two points
The creation and execution of fuzzy matching algorithms typically involves coding — which can be time consuming and requires an advanced skill set to execute.
Dataiku Features Built-In Fuzzy Join Recipes That Make It Easy to Join Columns Without the Need for Coding
Dataiku recently introduced some really powerful fuzzy matching algorithms to remove the hassle from your data pipelines. With visual recipes, you can clean, wrangle, and transform data quickly, without the need for code. The “fuzzy join” recipe uses a fuzzy matching algorithm to calculate a distance chosen by the user and then comparing it to a threshold. With this recipe, you can execute inner, left, right, or outer joins. You can also select normalization parameters like removing punctuation and spaces, or case sensitivity.
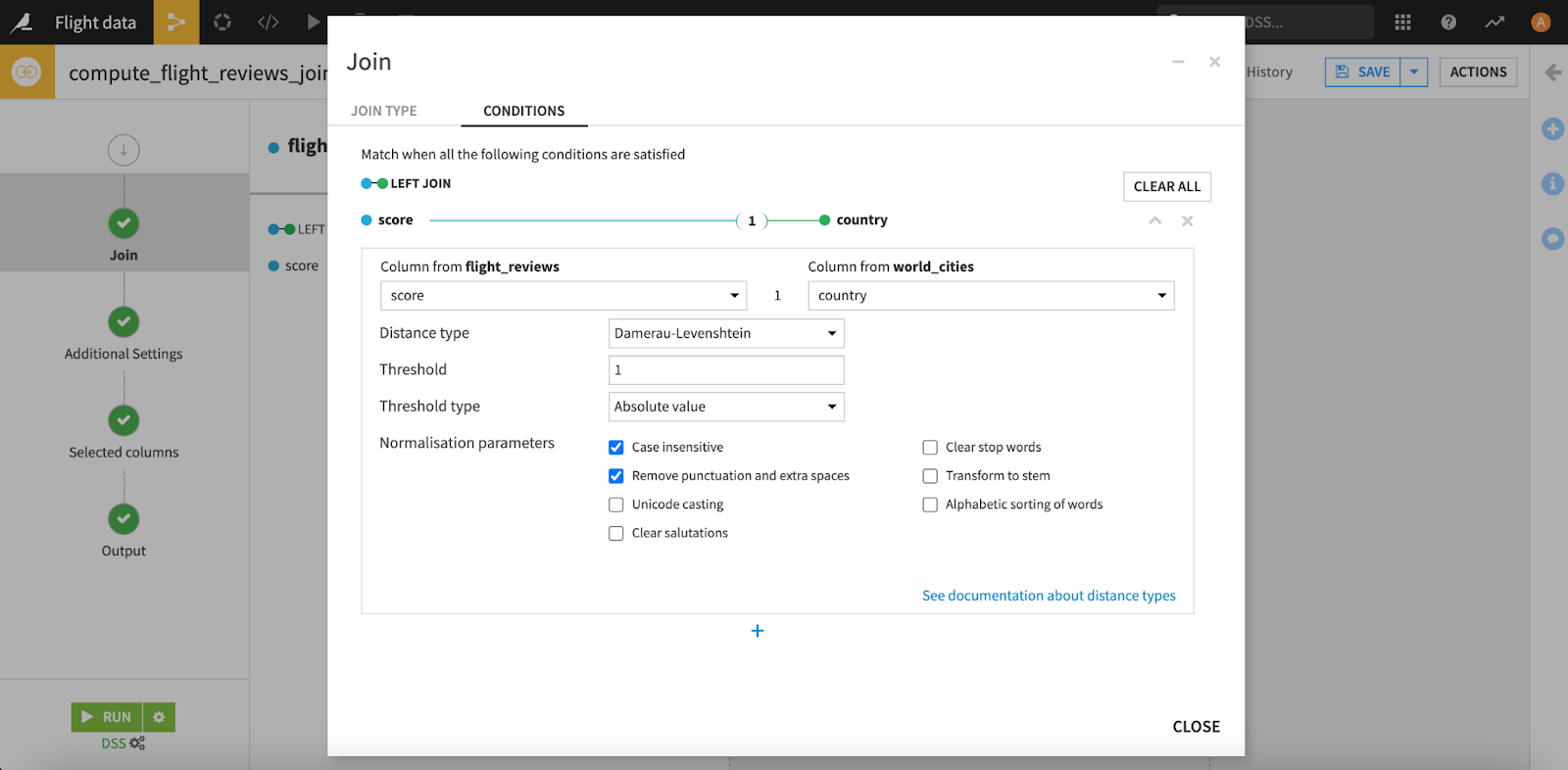
You also have the option to create additional columns in debug mode that allow you to perform further analysis on the matching details for the new merged dataset.
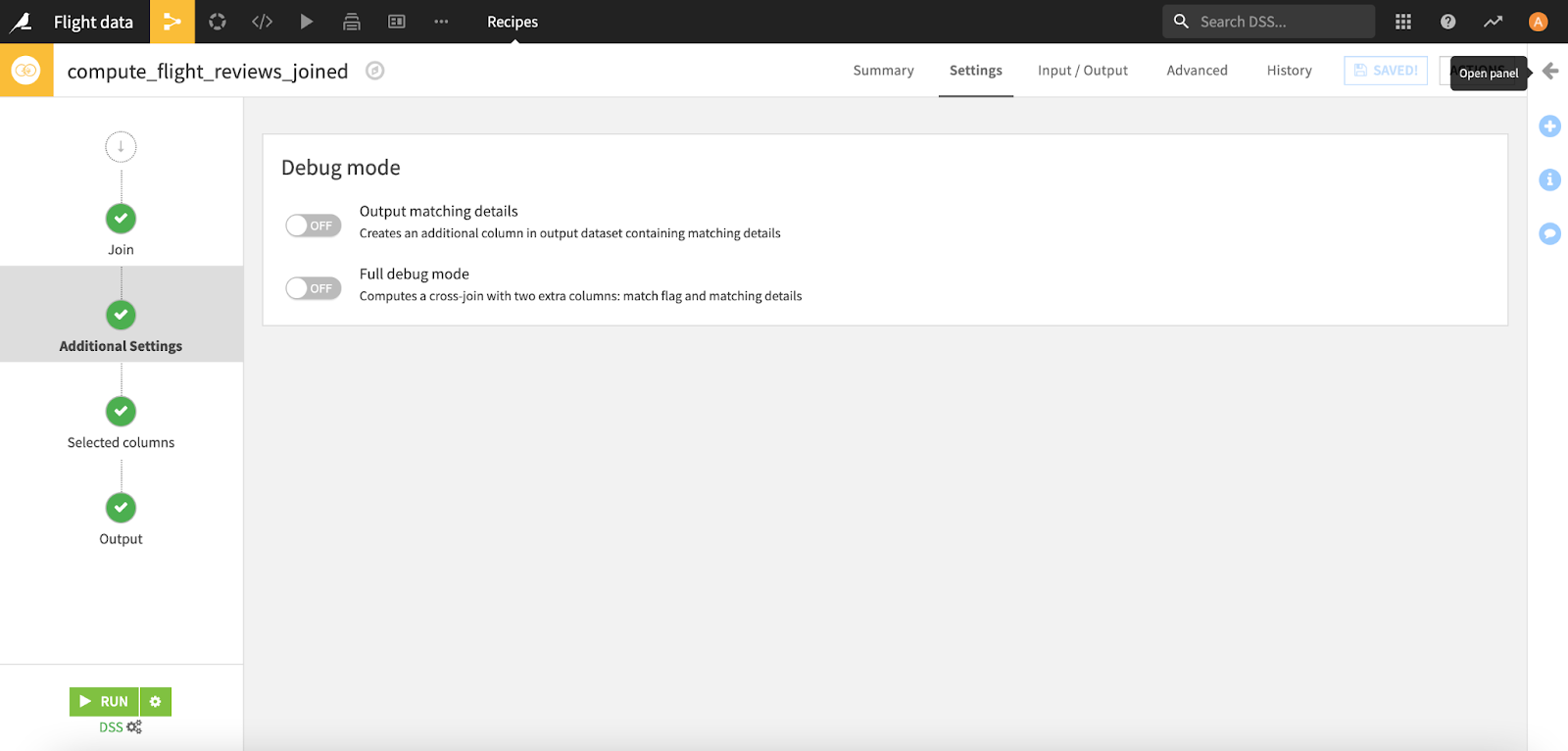
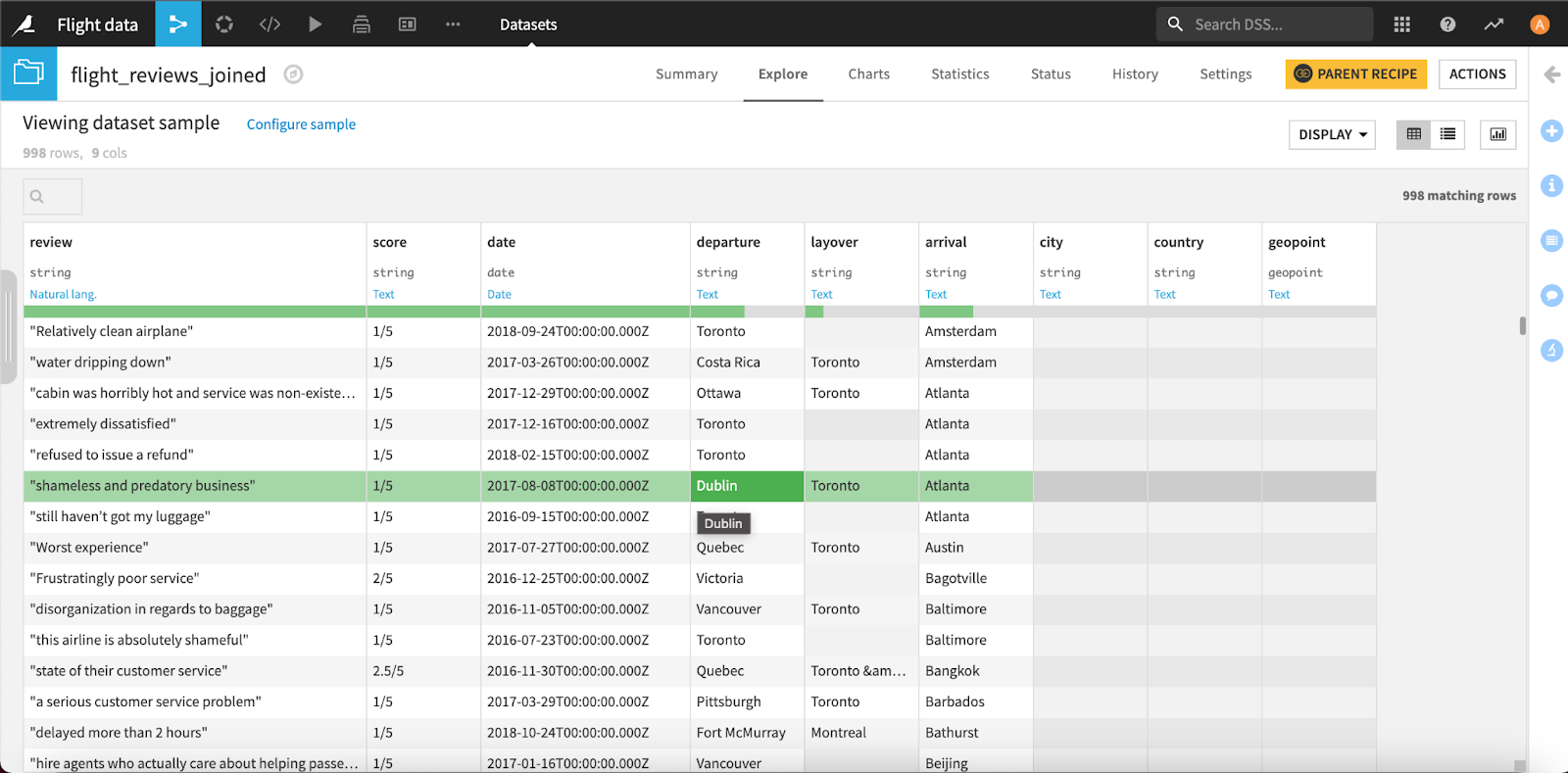
And there, in just a few clicks, your data is merged and ready for whatever comes next.
{kind=link}