




In this series, we explore constructing a fantasy sports roster as an example use case of an organization having to optimally allocate resources. In the first part, we introduced the topic of optimization in enterprise contexts and began building an end-to-end solution with data exploration and predictive analytics. We are now ready to explore how to solve an optimization problem called the Knapsack Problem to construct a strong roster using our predictions.
As we covered in the first part, a common type of problem that comes up in enterprise data-driven projects is determining how to optimally allocate resources. These problems come up in a variety of industries, including logistics, manufacturing, retail, human resources, and — as we explore in this series — sports. Specifically, the use case we examine is how to build a fantasy basketball roster given a set of players with various salaries and abilities to produce in-game.
The goal of optimization is to maximize or minimize some objective function, and often these problems involve some constraints that must be adhered to. For our use case, the objective function we are looking to maximize is the number of fantasy points that our constructed team will score. Using the DraftKings daily fantasy ruleset, various point values are awarded or penalized based on a player’s in-game action, such as scoring points, rebounds, assists, turnovers, etc.
The constraints for our problem include a limit on salary, positions, and availability of certain players. Specifically, we must stay under a salary cap of $50,000, and the roster of players must consist of eight players who are playing on a given day: point guard (PG), shooting guard (SG), small forward (SF), power forward (PF), center (C), guard (PG or SG), forward (SF or PF), and utility player (Any Position).
The focus of the previous article was on building a data pipeline to predict performance of the players in question. Making these predictions is essential prior to optimizing a roster because we need some metric representing how many points our team will score in order to maximize our objective function. Since we do not know these values prior to the games, the predicted number of points generated by our model can be used as a proxy for player production.
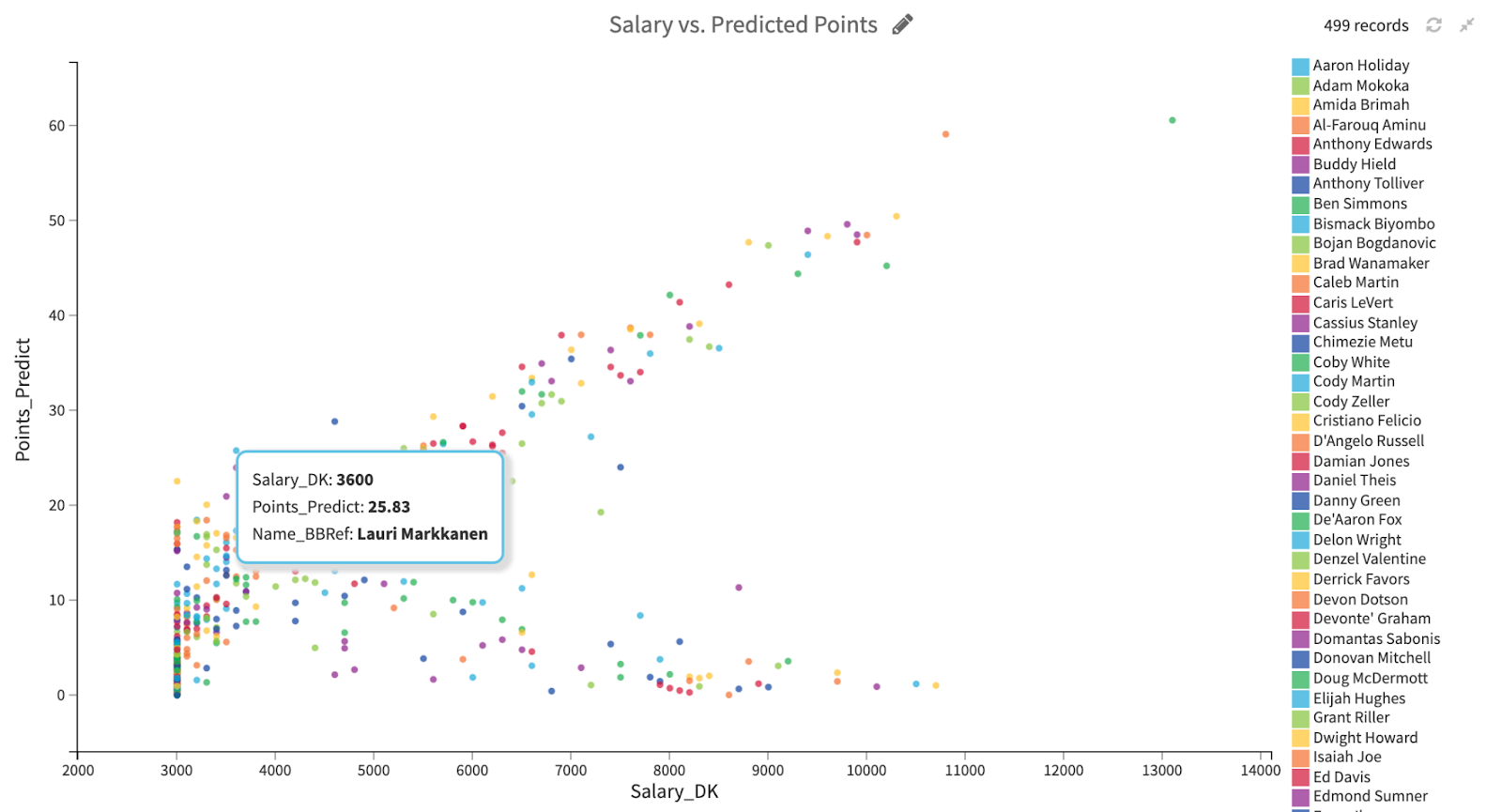
The above graph plots the number of points each player is predicted to score and their salary for the slate of games on May 16, 2021 (the last day of the 2020-21 NBA regular season). Plotting points versus salary gives us a sense of which players are likely to outperform or underperform their price.
Our goal is not just to identify players who will score a lot of points. Rather, striking a balance of low salary with high production by selecting players like Lauri Markkanen is the objective. Solving our optimization problem — which can be framed as the classic Knapsack Problem — will help us identify the best roster of players that will give us the best bang for our buck.
The Knapsack Problem
The problem we are attempting to solve — selecting a high-scoring roster of players while adhering to constraints — is a modified version of an optimization scenario called the Knapsack Problem. Imagine a robber breaks into a home with a knapsack. The items in the house have various different values and also weigh different amounts. The robber has to grab the most valuable items while also noting the limitations of how much weight he can carry in his knapsack.
This framing of the problem translates directly to optimization problems in many enterprise contexts. Employment decisions, supply chain, and, in our case, building a fantasy basketball roster all share the objective of trying to get the most value (choosing more valuable players) while adhering to a constraint (a limit on salary). These problems can of course modify the classic Knapsack Problem and introduce further constraints, as is the case with the positional and availability constraints in our fantasy basketball problem.
So how do we solve the Knapsack Problem problem, and how do we modify it to fit our specific problem? There are many potential approaches, including programmatic solutions such as greedy search or dynamic programming. Instead of tackling the problem in these ways, we will use an optimization approach. A special case of optimization is linear programming (LP), which requires the objective function and any constraints to be linear equalities or inequalities. Luckily, our objective and all of our constraints can be refactored as linear expressions, so to solve our problem we can use Python libraries that are commonly used for LP problems such as cvxpy and cvxopt.
Solving Knapsack With Python
Let’s examine some key code snippets used to solve the Knapsack Problem step by step. First, we import necessary libraries.
import dataikuimport pandas as pd, numpy as npimport cvxpy
Next, we read the input dataset as a dataframe. This dataset will be the output of the predictive analytics pipeline we built in the first part of this series and will include columns for the date of each slate of games (“Date”) along with each player’s name (“Name_BBRef”), salary (“Salary_DK”), predicted points (“Points_Predict”), and actual points (“Points_Actual”). For the purposes of this article, we will look at the games for the last week of the 2020-21 NBA regular season (May 10, 2021 - May 16, 2021).
nba_knapsack_prep = dataiku.Dataset("nba_knapsack")knapsack_df = nba_knapsack_prep.get_dataframe()
Now we define parameters for the problem. We want to keep these parameters configurable so that they can be modified when applying this code to accept different datasets and solve different objective functions and constraints.
agg_col = 'Date'label_col = 'Name_BBRef'cost_col = 'Salary_DK'value_col = 'Points_Predict'actual_col = 'Points_Actual'cap = 50000selection_n = 8
The first five parameters represent columns in the input dataset mentioned above. The cap represents the limitation on salary for our roster, and selection_n represents how many players we wish to select.
Now we are ready to set up and solve the knapsack problem in four steps:
1. Gather player costs and values, and initialize the optimization variables.
costs = np.array(df[cost_col])values = np.array(df[value_col])selection = cvxpy.Variable(len(costs), boolean=True)
2. Define objective function to maximize.
total_value = values @ selection
3. Define cap and positional constraints.
cost_constraint = costs @ selection <= caproster_constraint = np.ones(len(costs)) @ selection == selection_npg_constraint = pg @ selection >= 1sg_constraint = sg @ selection >= 1sf_constraint = sf @ selection >= 1pf_constraint = pf @ selection >= 1c_constraint = c @ selection >= 1g_constraint = (pg + sg) @ selection >= 3f_constraint = (sf + pf) @ selection >= 3
4. Define and solve the Knapsack Problem.
knapsack_problem = cvxpy.Problem(cvxpy.Maximize(total_value), [cost_constraint, roster_constraint, max_constraint,pg_constraint, sg_constraint, sf_constraint, pf_constraint, c_constraint, g_constraint, f_constraint])value_opt = knapsack_problem.solve(solver=cvxpy.GLPK_MI)
We can perform the above steps in a loop to solve for the three most optimal rosters on each date. Finally, we save the rosters into an output dataset.
nba_knapsack_output = dataiku.Dataset("nba_knapsack_output")nba_knapsack_output.write_with_schema(nba_knapsack_output_df)
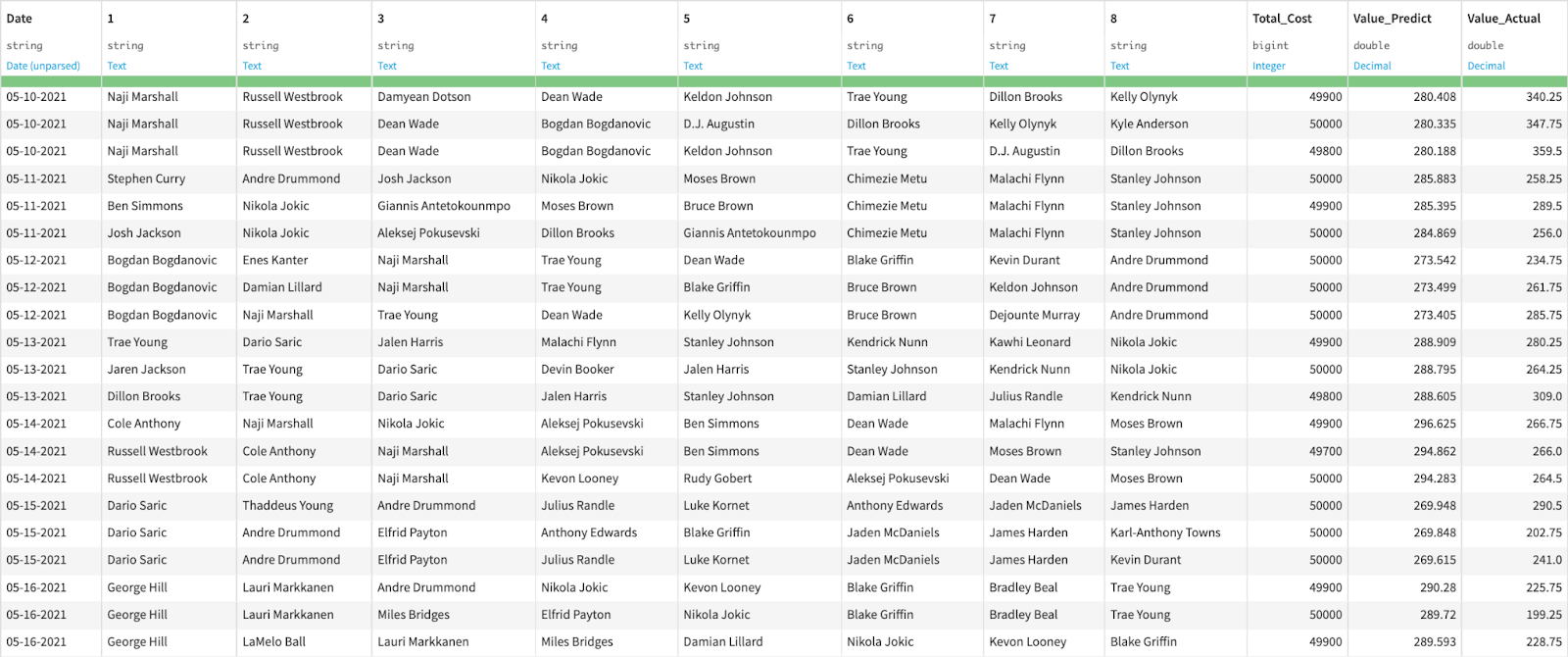
The output dataset, shown below, consists of each of the optimal rosters including the names of the eight players, the total salary of the roster, the predicted total points, and the actual total points.
{kind=link}
The lineups generated by the optimizer all have a total cost very close to $50,000, which is what we expect since it makes sense to try to utilize as much of the salary cap that is available to us as possible. The prediction for the total number of points the team will score lines up reasonably well with how many points the team actually scored, and the constructed lineup even occasionally outperforms projections (e.g. May 10).
The solution we have built is effective at assembling a roster of NBA players given the objective and constraints discussed. However, what if we wanted to tackle other similar optimization problems or wanted to modify our constraints? What if we want to share this solver with users or colleagues who may not be well-versed in Python? Stay tuned for the final part of this series, where we will cover how to make this optimization solver configurable and user-friendly by developing a custom plugin.