




{kind=link}
For those who do not know Dataiku DSS, it is a collaborative data science software platform for teams of data scientists, data analysts, and engineers to explore, prototype, build, and deliver data products more efficiently.
Dataiku DSS is mainly written in Java and — to simplify things — the server runs as a single process (Java Virtual Machine, or JVM) providing everything we need, including an embedded web server.
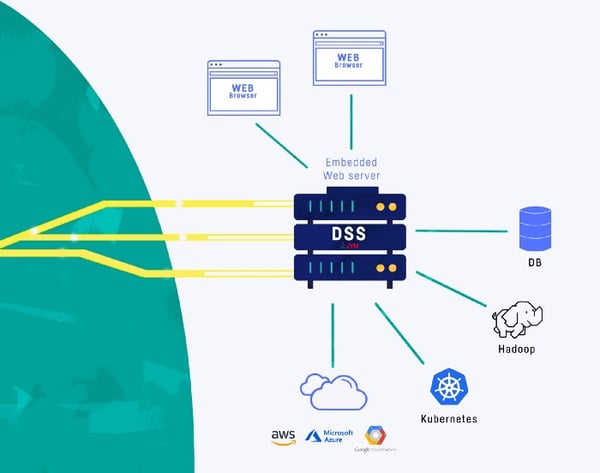 Dataiku DSS — simplified architecture
Dataiku DSS — simplified architecture
As data leveraged by Dataiku DSS users can be located in various different places, Dataiku DSS can connect to a wide range of data sources, some of them containing data that is up to hundreds of gigabytes.
The whole purpose of Dataiku DSS is to transform raw data into more actionable data through transformations as well as machine learning and deep learning models. Most of the transformation and model training is performed on compute clusters, but sometimes, some data processing ends up being done by Dataiku DSS itself.
So what happens if — as a Dataiku DSS user — you upload a large CSV file and try to run some memory-intensive data transformation on it? Well, you will likely run out of memory.
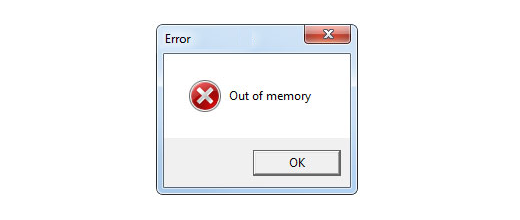
The best case scenario is that the JVM will throw an OutOfMemoryException right away, the Dataiku DSS server will quickly exit, and it will then be relaunched by our supervisor. In the worst case scenario, the garbage collector (GC) will continuously reclaim a few bytes of unused memory and the Dataiku DSS server will appear frozen, web pages will time out, and no users will be able to access the platform until it is restarted.
Future Execution Kernel
So what will save the day? Please help me welcome the Future Execution Kernel!
Instead of running those memory-intensive operations in the Dataiku DSS backend process, we run them in another JVM/process. We call this other JVM the Future Execution Kernel (FEK). The Dataiku DSS backend can submit tasks to a FutureService that will be executed on a FEK. So if some users trigger an operation that might generate an OutOfMemoryException, it is executed in a FEK and not on the Dataiku DSS backend.
This greatly improves the reliability of Dataiku DSS: if the operation does trigger an OutOfMemoryException, it kills the FEK, but the backend JVM is still alive and can notify the user that his operation tried to consume too much memory and was killed.
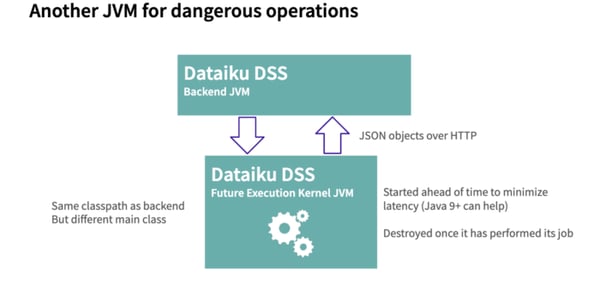
So how does it work under the hood? It's actually pretty straightforward. The FEK is the same Java application as the backend (same jars, same classpath) but invoked with a different main class. As a consequence, both JVMs host the same kind of Java objects.
To execute a task in the FEK, users submit an instance of a FutureThread object to the FutureService that is running on the JVM backend. The FutureService serializes this object into JSON and sends it to the FEK via a simple REST call.

Dataiku DSS service submitting an Export task
On the other side, the FEK receives the request, deserializes the JSON into a FutureThread object (which is possible because both the backend and the JEK have the same classpath), and calls the run method on it.
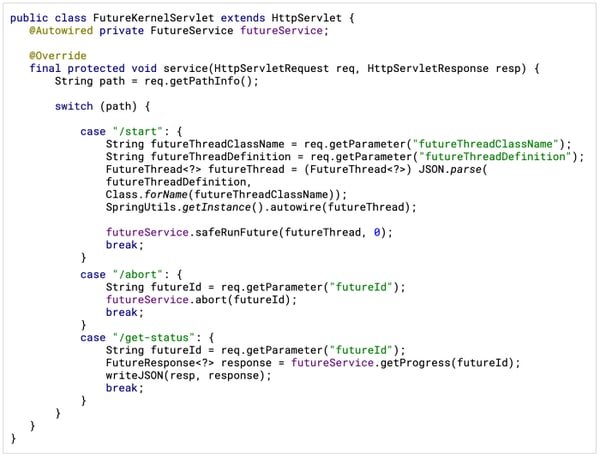 FEK servlet implementation
FEK servlet implementation
The backend will then regularly poll the FEK to retrieve the status of the task and the result when it has finished (using the same JSON over REST mechanism).
Let's Talk Latency & Concurrency
Up until recently, Java was not known for its amazingly fast startup time. Things have started to change lately with Java 9 (you can learn more in this very good article), but still, it requires some time to bootstrap a new JVM.
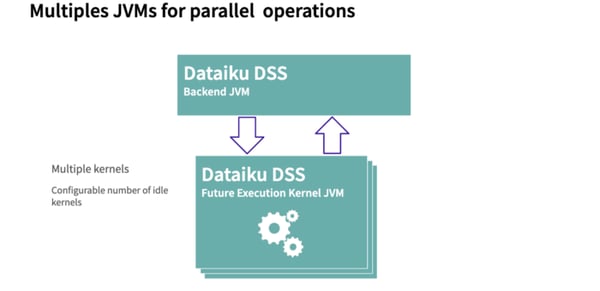
To avoid this pitfall, Dataiku DSS starts an FEK when it boots so that an FEK is already running whenever a task a submitted. Once a task has completed, its associated FEK is terminated, and a new FEK is started. This prevents subsequent tasks from run in a JVM that may be in bad shape.
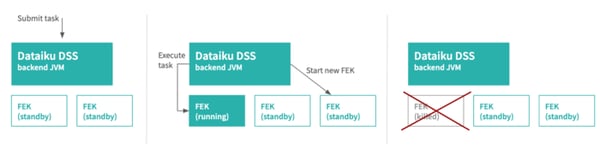
In real-life situations, however, multiple users may submit tasks simultaneously. To cope with it efficiently, Dataiku DSS actually uses a pool of FEKs. At boot time, it starts a configurable number of FEKs. When a task is submitted, it get handled by an FEK. Since this FEK is no longer considered available, Dataiku DSS immediately starts a new FEK in order to have enough FEKs in standby mode to handle incoming tasks.
 That's all folks! As you can see, this is not rocket science, and a few other companies have implemented similar patterns. I hope you enjoyed this little tour of the internal workings of Dataiku DSS!
That's all folks! As you can see, this is not rocket science, and a few other companies have implemented similar patterns. I hope you enjoyed this little tour of the internal workings of Dataiku DSS!