




One of the most exciting events in American sports is the NCAA March Madness tournament, where 68 college basketball teams battle it out in a single elimination format to decide the season’s champion. While COVID-19 resulted in its cancellation in 2020, this year we were fortunate enough to witness an exciting tournament.
In advance of the tournament, we tasked ourselves with using Dataiku to help us model outcomes of the tournament and generate bracket predictions. We presented our picks in a panel discussion with ESPN’s Bracketologist Joe Lunardi, who felt that our picks were strong. The actual results of the tournament corroborated the strength of our picks, with our bracket registering in the 99.8 percentile, selecting three out of four of the correct Final Four and correctly choosing Baylor over Gonzaga in the championship game. The fact that we were able to quickly build an intuitive data pipeline in Dataiku and achieve such strong results demonstrates the power of analytics and the strength of the tool in facilitating human-centered AI.
It’s no secret that sports analytics is now considered an essential tool for every sports organization’s playbook. Teams rely on analytics to stay competitive, make the best decisions, and recruit the best players for their franchise. Our approach involved incorporating key statistics and building a machine learning model to predict outcomes. While statistics can play a key role in decision-making, a plug-and-play approach is not sufficient. We used a human-in-the-loop approach where we constantly iterated on and modified our model until the methods and the accuracy were up to our standards. While we know the 2021 tournament is now in the past, we hope that this account of how we made our predictions might inspire you to make a data-backed bracket in 2022.
How We Did It
1. Find the right data.
The first step in our process of generating a bracket was to determine what data could help us predict outcomes. We began by scraping data from College Basketball Reference, which included game information, box score statistics, and outcomes pertaining to every college basketball game going back to 2010.
To supplement this data, we looked to a statistical archive called Ken Pom that included various advanced metrics, such as tempo, efficiency, experience, roster continuity, and more. This data would help us capture aspects of the game that pure box score numbers cannot and therefore help us truly differentiate which team was stronger in any given matchup.
2. Join our datasets.
Once we collected the data, we needed to think about how to build features to use in a predictive model. While having game-level data was a good starting point, these individual statistics on their own would not help us predict outcomes. We used visual recipes in Dataiku to help engineer our features, which primarily involved joins and aggregations. Performing a join was extremely intuitive in Dataiku: To marry our College Basketball Reference and Ken Pom datasets, we simply had to create a join recipe, select our join conditions, and run the step.
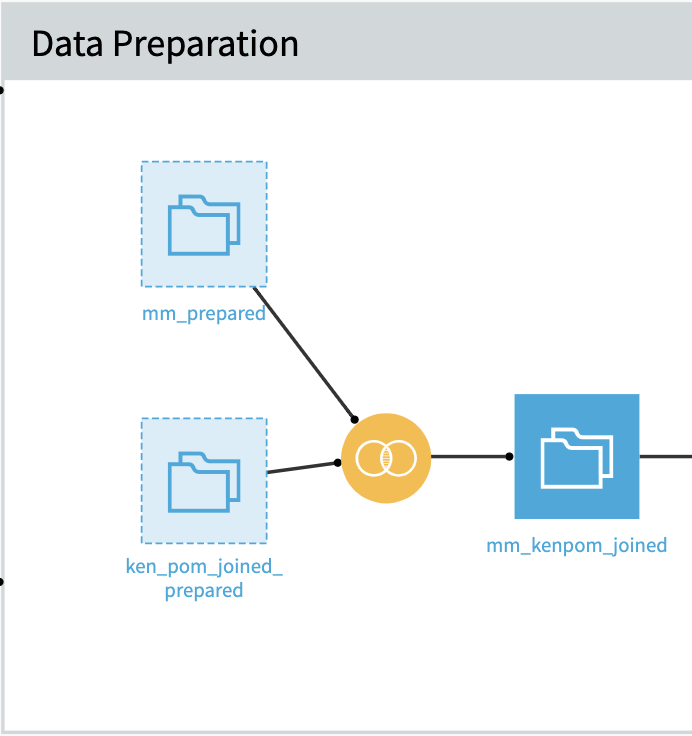
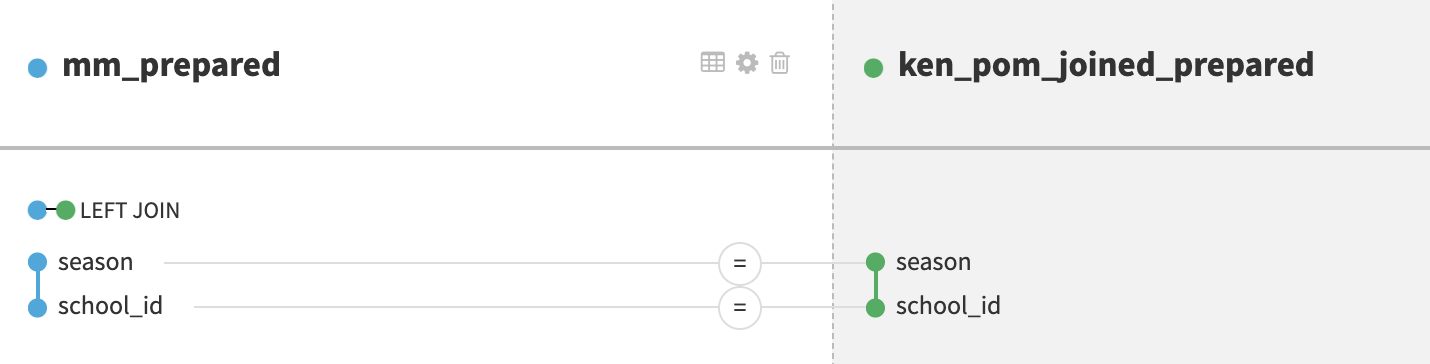
3. Aggregate our box score and advanced data (by team) across the season and the last five games.
Aggregating the data to get a sense of historical performance could be done by creating a window recipe. After joining our datasets, we wanted to aggregate our box score and advanced data for each team over two time windows: the entire season and the last five games. This would allow us to get a sense of the season-long performance as well as recent performance of each team in a given matchup.
The window recipe in Dataiku allowed us to select our desired time windows as well as the stats we wished to aggregate over these windows. We also had to make sure not to include the current row in the aggregation to avoid data leakage. In other words, we cannot use statistics from a game to predict that same game; rather, we have to look at previous statistics.
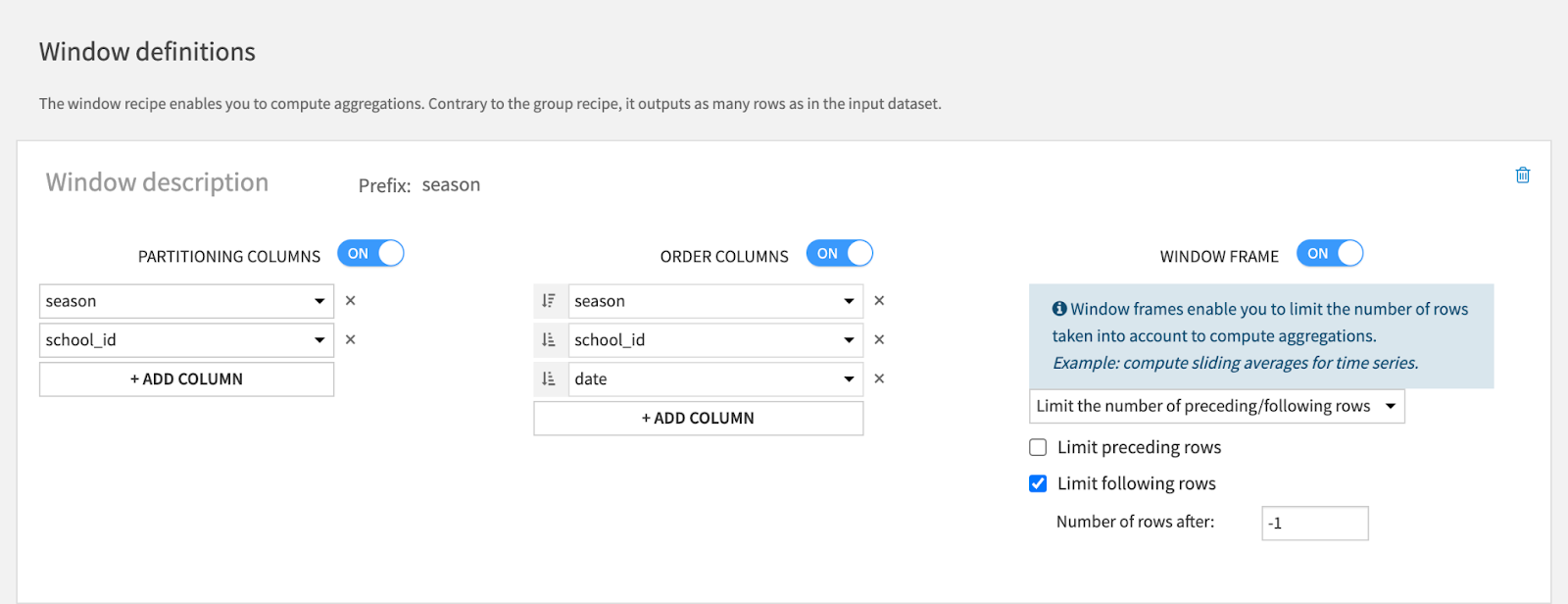
4. Build our predictive model.
Once our aggregated features were ready, it was time to put together a predictive model. Using visual AutoML in Dataiku, we started by generating a classification model to determine which team would win any given matchup. The first iteration of our model, a random forest, had a validation accuracy of 72%. This accuracy in the realm of sports is not weak per se, but we felt that we could improve the model in a number of ways.
5. Make improvements.
We began by modifying our training / validation / testing split to include more data in the training set. The hope was that the additional games to train on would improve the model’s predictive power. When examining the model output, we also noticed that the model favored teams like Colgate that we intuitively knew were weak and unlikely to advance deep into the tournament.
Looking at the feature importances, we saw that a team’s win percentage over the course of the season was far and away the most important factor in the model. While win percentage can give a good indication that a team is strong (e.g., Gonzaga had an undefeated record and was clearly poised to make a deep run), this feature does not capture the quality of wins.
Colgate, coming into the tournament with a strong 11-1 record, hails from the Patriot League conference, which is much weaker than conferences like the Big 12, Big Ten, Big East, and ACC. Examining our approach, we decided to use a team’s conference win / loss percentage and also to use conference as a one-hot encoded (binary) feature itself.
These modifications would help capture the difference in conference strength and hopefully suppress those teams with artificially high win / loss percentages. The result of our modifications to the features and model-building approach resulted in a much-improved accuracy of 82%, which we achieved using a logistic regression.
{kind=link}
6. Put our model to the test.
The final step in our process was to use our model to predict the outcome of the 2021 March Madness tournament. Going into the tournament, we of course only knew the matchups going into the first round of the tournament, so predicting the overall bracket result was not as simple as predicting the outcomes of these games. We needed an iterative process to predict each round result and infer the matchups going into the following round.
To accomplish this, we wrote a Python script where we imported the logistic regression model we built using visual AutoML in Dataiku, and then we built a loop for using the model to predict matchups for a given round and generating matchups for the following round.
Code snippet 1 (importing the model):
import dataiku
# Read recipe inputs
model = dataiku.Model("I6gfnesP")
mm_model = model.get_predictor()
Code snippet 2 (building the loop):
# Generate Matchups and Make Predictions for Rounds 1-6
for tourney_round in range(1, 7):
bracket_df = generate_matchups(matchup_df, bracket_df, school_info_df, matchups, tourney_round)
matchup_df = predict_matchups(bracket_df, tourney_round, mm_model)
Key Statistics and Limitations
Rather than simply generating predictions through a black box, it is important to see why the model “thinks” a given outcome will occur. By using a scoring recipe to generate Shapley values for each game prediction, we were able to infer why the model predicted individual outcomes. The three most important features our model gave as predictors of success were:
- Effective field goal percentage: When a team can limit the opposition’s ability to score and can put the ball through the hoop
- Conference win / loss percentage: The closest feature we could get to creating a “strength of schedule”
- Turnover percentage: The ability of a team to take care of the ball and force turnovers from the opposition
Another important consideration when building a model is to think about blind spots. It is always important to think about what types of features the model cannot capture and to either try to incorporate these into the model or attribute variation in predictive success to these factors. Some of the model limitations that we acknowledged were:
- Players’ mental state (there’s no way to incorporate confidence and what goes on in the brain)
- Bubble performance (unusual circumstance during Covid where players had to remain in specific areas and play every game in Indianapolis with limited fans)
- Potential Covid exposure (VCU forfeited because of Covid complications)
- Player tracking data unavailable
While the process of generating bracket predictions was certainly fun and engaging, having a good bracket for The Big Dance doesn’t stop at bragging rights. The exercise demonstrated the power of Dataiku (as the centralized, collaborative platform for data efforts across an organization) and the massive potential for human-centered AI in predicting outcomes.
Check out the video below for a visual walk-through of the project: