




If you’ve heard about Docker and Kubernetes but haven’t used them yourself, this is the tutorial for you. I’m not a rocket scientist — nor a scientist at all. In high school, I struggled so much with math; I had to stay after class, causing me to be perpetually late for football practice. And if you had seen me play football in those days, brother, you’d know, I really couldn’t afford to miss practice...
Anyway, for years I put off digging into Docker and Kubernetes. I knew they were popular tools and important for making data science portable and reproducible, but frankly, I was just intimidated. I’d start a tutorial or book with a ton of enthusiasm, but that would quickly fizzle. It wasn’t until I actually got my hands dirty and started using them that I felt more comfortable.
So if that’s you, then today is the day you say, “Enough!” Today, you’ll train your first model on Kubernetes. We’ll take some basic code, throw it in a container, and run it on Kubernetes. It’s going to be a little ugly but very effective. It involves minimal theory, but is something that you can run in as little time as possible. And by the way, if you want to go even faster, I included some quick snippets at the end showing the same stuff in Dataiku.
As an aside, I recently read an excellent series by Luigi Petruno on his blog “ML In Production” and was specifically inspired by the article “Kubernetes Jobs for ML.” I highly recommend reading the entire series.
So let’s start with a basic Python example. We’ll use some stock code from scikit-learn to train a model. We’ll then build a container around that code and run the container locally. Finally, we’ll run the container on a Kubernetes cluster.
What You Need
- Python (I’ll be using Python3, you only need this for testing outside of Docker)
- Docker
- Kubernetes Command Line Tool
- A Running Kubernetes Cluster
- You can run these examples with minikube.
- More advanced users can try managed Kubernetes clusters from the various cloud providers.
Basic ML Training With Python
Let’s create a new working directory for our project. I’ll call mine k8s_basics. From my terminal, I’ll create that directory and cd into it.
mkdir k8s_basics
cd k8s_basics/
Next, let’s create a new Python virtual environment and install scikit-learn. We can do that as follows:
python3 -m venv envsource env/bin/activatepip install scikit-learn
Now let’s create our model training code. Use your favorite text editor (I prefer vim) to create a file called train.py.
vim train.py
I took the code directly from the scikit-learn introductory documentation and added in one print statement (“Model finished training...Hooray”). I’m not claiming that this is fancy or even remotely realistic ML — it’s a quick example so we can focus on Docker and Kubernetes.
from sklearn import svmfrom sklearn import datasetsfrom joblib import dump, loadclf = svm.SVC()X, y = datasets.load_iris(return_X_y=True)clf.fit(X, y)
print ("Model finished training...Hooray")
dump(clf, 'svc_model.model')
Now let’s test our code on our local machine. We’ll execute our script with Python as follows:
python train.py
If you see “Model finished training...Hooray” printed to the console, you have succeeded. Hot diggity — we’re training some ML. We’ve created a basic ML model and we’ve saved it. Now let’s dockerize it.
Basic ML Training With Docker
To use Docker, it’s helpful to define the term container. Let’s do that now.
Container = Shipping Container.
Imagine a shipping container. That’s it. Whether it is one of thousands on a big ocean cruiser or in stacks on a port, it doesn’t matter. We might say that shipping containers hold stuff, but the better analogy is that they isolate stuff. That is, they keep the things inside separate.
So if the Docker container is just a thing that isolates whatever you put inside of it, what are we going to put in there? In our case, that will be the Python code we ran above.
Now in order to load stuff into a shipping container, the container needs some sort of manifest or document that explains what goes inside of it. This manifest is just a list of stuff that tells the crew what to put in the container. For us, this manifest is called a Dockerfile.
We need to create a Dockerfile, so let’s do that now. In the same directory as our Python code, create a new file called Dockerfile. As before, I’ll use vim.
vim Dockerfile
Now we’ll add the following to our Dockerfile:
FROM jupyter/scipy-notebookCOPY train.py ./train.pyRUN python3 train.py
These three lines need explanation. The first line FROM jupyter/scipy-notebook provides us with a base image to use for our container. This means that rather than starting with an empty container (remember: think shipping container), we’re going to start with something that already has some stuff in it.
In our case, the jupyter/scipy-notebook image contains Python and a bunch of helpful libraries for machine learning. There are tons of other publicly available images we could have used, but you don’t need to worry about that now.
I’ve used the term image several times without defining it. Let’s define it now. For us, an image is just a stationary form of our container. It’s the stuff all packaged up, waiting to get put onto a truck or a ship. So what we actually run is the container, but all of our containers come from images.
So in our case, we’re starting from an existing image with lots of goodies, and then we just use COPY train.py ./train.py to copy in our code. The COPY statement copies our train.py file from our local directory into the image.
Finally, we add RUN python3 train.py. This just tells Docker what command to execute when we run this container. Just like we ran python3 train.py to test our script, we want Docker to do the same thing.
So our Docker file does three things:
- Tells Docker to start with an existing set of tools
- Copies our Python script
- Runs the Python script
In order to actually run our code in Docker, we need to build a custom image. And as mentioned, we do this with our Dockerfile.
Command to build our Dockerfile:
docker build -t train-sklearn:0.1 .
A few notes on the command above. docker build tells docker that we are going to build an image. The “-t” flag stands for tag and this tells Docker that we want to give our image a name. I chose the name “train-sklearn” and, per docker convention, I used a “:” to add a version number, “0.1.” This is arbitrary and you could do something totally different, like the below:
docker build -t madeupname:17.1 .
The final note about this is “.” at the end. This just tells Docker where to look for our Dockerfile (remember: shipping container manifest). And in our case, it is in our current working directory, which the “.” signifies.
In summary, this command builds an image and stores it on our local machine. Excellent. Our next step is to create a container from this image and run the container.
Run the Container
Now let’s run the thing. I’m going to be a little sloppy here and I don’t care. I want this to be useful rather than completely correct. So now we’ll execute the command below:
docker run -it train-sklearn:0.1 /bin/bash
This command builds a container from our image (“train-sklearn:0.1”). It does this in interactive mode (“-it”), which means we’ll get a running shell. Finally, we’ll pass a command to the container “/bin/bash” so that we’ll get access to that running shell.
When I execute this command, per our Dockerfile, Docker runs our script (“python3 train.py”) automatically. This trains our model and saves it. If you haven’t executed the command, do so now. Your command prompt should now be a running shell within the container.
From within the running container shell, I’ll use the “ls” command to list the files in my working directory. And lo and behold, there is our model (below are the commands to both execute the container and then list the directory):
$ docker run -it train-sklearn:0.1 /bin/bash(base) jovyan@7a1e326f4c15:~$ lssvc_model.model train.py work
To be clear, we didn’t need to open a shell into the container to check that our script ran, but I think it is useful to see at this stage.
So, to recap — congratulations! You have now built a Docker image and run your first ML training task in a container. Sure, it was a trivial example, but you now have some of the foundational skills for doing more advanced stuff. So good on ‘ya!
But we’re not done yet, of course. This tutorial is both Docker and Kubernetes. Time to go to Kubernetes.
Basic ML Training With Kubernetes
Here is your one sentence definition of Kubernetes. Kubernetes is a tool that runs containers.
Let’s go back to our shipping container analogy. Docker gives us the actual shipping container. Kubernetes is the crane that moves it around. That’s it. You’ll hear people say that Kubernetes is an orchestration tool. Orchestration is just a fancy way of saying moving containers around. So far so good? Great.
To use Kubernetes for training our model, you need to be aware of a few concepts: clusters, nodes, pods, and jobs. Just as before, we’ll introduce them one at a time as we move through the example. A cluster is a collection of nodes. Nodes can be separate machines, as in separate physical or virtual servers. Let’s start our Kubernetes cluster with minikube so that you can see what it is before we explain more.
Start Minikube
We can start our minikube cluster as follows:
$ minikube start
It takes a minute or two to start. Patience is a virtue. Once the cluster is running, we can view the cluster nodes. To see the nodes in our cluster, run:
$ kubectl get nodesNAME STATUS ROLES AGE VERSIONminikube Ready master 180d v1.18.3
If you’re using minikube like me, what you see is a single node (that is actually running on your local machine). So our cluster really isn't a cluster at all (just one node), but that’s okay. We can still get down with that just fine. Hey — minikube is running, great job!
Now let’s talk about pods. When we run stuff (containers) in Kubernetes, Kubernetes runs those containers inside of something called a pod (and pods run on nodes). Let’s break this down a bit.
Pods are the basic scheduling unit in Kubernetes. We don’t create them directly, which is nice. Instead, we tell Kubernetes what we want to do. We’ll say things like “run this one-off task” (as in the Kubernetes job we’ll create later) or “run this task until I tell you stop” (like the Kubernetes deployment we’ll create after that). Kubernetes will, in turn, create the pods for these tasks. Let’s have a look.
For example, let’s check out the current running pods. We haven’t started our Kubernetes job yet, so none of these are ours, but we can still take a peak.
You can do that by running kubectl get pods -A
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-66bff467f8-5lvpb 1/1 Running 2 179d
kube-system coredns-66bff467f8-nm4s7 1/1 Running 2 179d
kube-system etcd-minikube 1/1 Running 2 179d
kube-system kube-apiserver-minikube 1/1 Running 2 179d
kube-system kube-controller-manager-minikube 1/1 Running 3 179d
kube-system kube-proxy-64dst 1/1 Running 2 179d
kube-system kube-scheduler-minikube 1/1 Running 2 179d
kube-system storage-provisioner 1/1 Running 4
On my minikube cluster, I can see the pods above representing core services of Kubernetes. While it might be forcing my crane analogy a bit, we can consider these pods to be the crew operating the crane itself.
Image Registry
Join me in another bad analogy. If Docker is our container and Kubernetes is the crane that moves our containers around, we need to put our containers in a warehouse that the crane (Kubernetes) can find. When we ran our model training in Docker (see the previous section), we used an image stored on our local machine. Technically, we could do the same thing with our minikube cluster, but this would NOT serve you well when you moved on to a real Kubernetes cluster AND the configuration is more confusing (I personally think) than just doing the right thing.
So let’s do the right thing. This means we need to put our Docker images in a warehouse that our Kubernetes crane can access. This warehouse is called a container repository.
Now there are lots of options for container repositories. Each of the major cloud vendors have their own, for example. But I recommend you get started with Docker Hub. It’s free, fast, and works with the version of Docker you already installed. What’s not to like? So go to Docker Hub now and create an account. Meet me back here once you’ve done that.
With our newly created Docker Hub account, we now need to store our image in it. To put our Docker image in the Docker Hub warehouse, we need to follow a few easy steps.
Login to Docker Hub
We login to Docker Hub from our command line. Just type Docker login. You’ll be prompted to enter your username and password. You should use the same information as what you used to create your Docker Hub account on their website.
docker login
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
Username: gcav66
Password:
Login Succeeded
If you see a “Login Succeeded” message like mine above, that means your login worked.
Now before we push our image to this repository, we need to give it a new name. This way Docker Hub knows which warehouse to send it. We give our image a new name by creating a tag. This creates essentially a copy of our image.
Tag Your Existing Image
docker tag train-sklearn:0.1 gcav66/train-sklearn:0.1
The syntax here is Docker tag <existing image name:version> <your repo/image name:version>. So in my case, my Docker Hub repo is gcav66. I add that in front of my image name and separate them with a slash. This will let Docker Hub know which repo (gcav66) to send my Docker image (train-sklearn:0.1). Not too bad, right? Excellent.
Now that we’ve tagged the image, it’s time to push it to our repository.
Push Your New Image to Your Repository
docker push gcav66/train-sklearn:0.1
This command is very simple: docker push <repo/image-name:version> per what we created above. Make sure you replace your new image name with the naming convention I have above.
Kubernetes YAML File: Instructions for the Crane Operator
Just as our Docker image had a manifest to tell the workers what to put in the container, we need to give our crane operator some instructions on where to put our container. We do that in a configuration file with the extension yaml. Now don’t be scared by this, we’re just going to enter some quick text.
Create a new file with your text editor called train.yaml. Add the following:
apiVersion: batch/v1kind: Jobmetadata: name: train-ml-k8sspec: template: spec: containers: - name: train-ml-k8s imagePullPolicy: Always image: gcav66/train-sklearn:0.1 command: ["python3", "train.py"] restartPolicy: Never backoffLimit: 0
Let’s break this down a bit.
kind: Job
We’ll now introduce the concepts of Kubernetes jobs. Per the docs, “A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate.” The key idea here is retry...until...successfully terminate.
Let’s take our ML training script as an example. We don’t want this to run forever. We want it to run long enough to train and save our model. Once that has been completed, the job should end (and in turn the pod(s) should be destroyed). Later, we’ll walk through serving our model as a REST API on Kubernetes, and then we’ll want those containers to run forever (or until we say stop). But for now, we just want this thing to run and then clean up after itself when it finishes.
image: gcav66/train-sklearn:0.1
command: ["python3", "train.py"]
If you want to use your own image (and not mine) change the value after image: to whatever your repo/image-name:version is. So replace image: gcav66/train-sklearn:0.1 with your specific information.
Run This Job on Kubernetes
I appreciate you sticking with me this far. The moment is finally here. Let’s run this thing. We’ll do this by using the apply command with kubectl, passing in the train.yaml file we just created. The syntax looks like kubectl apply -f train.yaml
Now when you execute that command, you’ll just see that a job was created.
In order to check the status of our job, we need to look at the pods. Remember the command we used to do that? Great, run kubectl get pods -A as I do below.
kubectl apply -f train.yamljob.batch/train-ml-k8s created(env) guss-mbp-2:k8s_basics gcavanaugh$ kubectl get pods -ANAMESPACE NAME READY STATUS RESTARTS AGEdefault train-ml-k8s-pksnk 0/1 ContainerCreating 0 5skube-system coredns-66bff467f8-5lvpb 1/1 Running 2 179dkube-system coredns-66bff467f8-nm4s7 1/1 Running 2 179dkube-system etcd-minikube 1/1 Running 2 179dkube-system kube-apiserver-minikube 1/1 Running 2 179dkube-system kube-controller-manager-minikube 1/1 Running 3 179dkube-system kube-proxy-64dst 1/1 Running 2 179dkube-system kube-scheduler-minikube 1/1 Running 2 179dkube-system storage-provisioner 1/1 Running 4 179d(env) guss-mbp-2:k8s_basics gcavanaugh$ kubectl logs train-ml-k8s-pksnkModel finished training...Hooray
What we can see is that our job “train-ml-k8s-something” is starting to run. Super. Now let’s check the logs from our pod to see if our success message has been printed (“Model finished training...Hooray”).
We do that by typing:
$ kubectl logs train-ml-k8s-pksnkModel finished training...Hooray
If you see “Model finished training...Hooray” then I want to pass on my heartfelt congratulations. You have now trained your first model on Kubernetes. You badass, you!
What Next
There are many things we haven’t covered. Here are just a few:
- How to do batch scoring so we can get loads of predictions from our models
- How to do real-time scoring (serve a REST API) so our web developer buddies can use our cool model
- How to let our friends help us with development so we can like, collaborate, and stuff
- How to connect to real data sources and not just use the built-in dataset like in this example
We’ll cover the first two bullets below, so keep reading if you’re interested.
How to Train Models on Kubernetes With Dataiku DSS Right Now
Instead of creating those code environments, Docker images, and wading through yaml files, you could just write your code and click two buttons.
And I’ll do you one better, if you want to train some models with open-source packages like scikit-learn without having to write any code, you can do that as well. Not bad, right?
Does that sound too easy? Let me show you how it works. Let’s run our exact same code on Docker and Kubernetes with Dataiku DSS. From my Dataiku DSS instance, I just need to:
1. Open up a Python script.
Dataiku DSS supports Python (as well as other languages for data science). And Dataiku DSS is a web application, so I just login via a web browser. So instead of installing stuff on my local machine, messing around with different versions of languages and packages, and getting frustrated when I run out of disk and RAM, I can just go to Dataiku DSS and let it handle all that for me.

2. Paste in our code.
Next, we’ll paste our code into a Dataiku DSS code editor. You don’t have to use this, so don’t freak out if you have a favorite IDE. I could have used a built-in Jupyter notebook or an IDE on my local workstation. I just want to show you how quickly we can knock out this same workflow in Dataiku DSS.
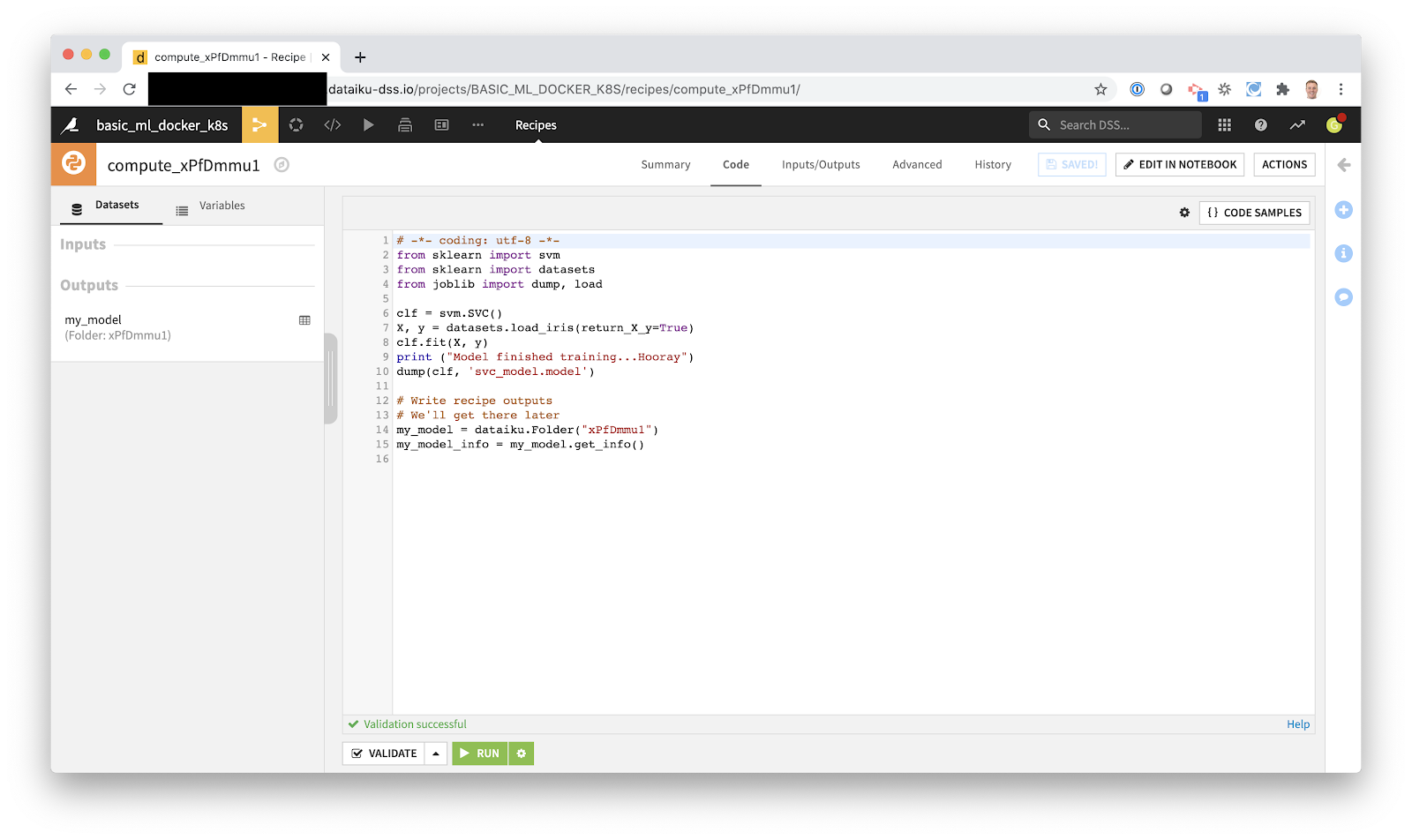
3. Choose our Kubernetes cluster.
We spent most of our time in the tutorial using Docker and Kubernetes. We had to install Docker, kubectl, create a Kubernetes cluster, build a docker image, push it to a repository, and then create and run our Kubernetes job. In Dataiku DSS, you can just select a preconfigured container configuration. That’s it. I don’t need to know anything about Docker or Kubernetes.

4. Run our code.
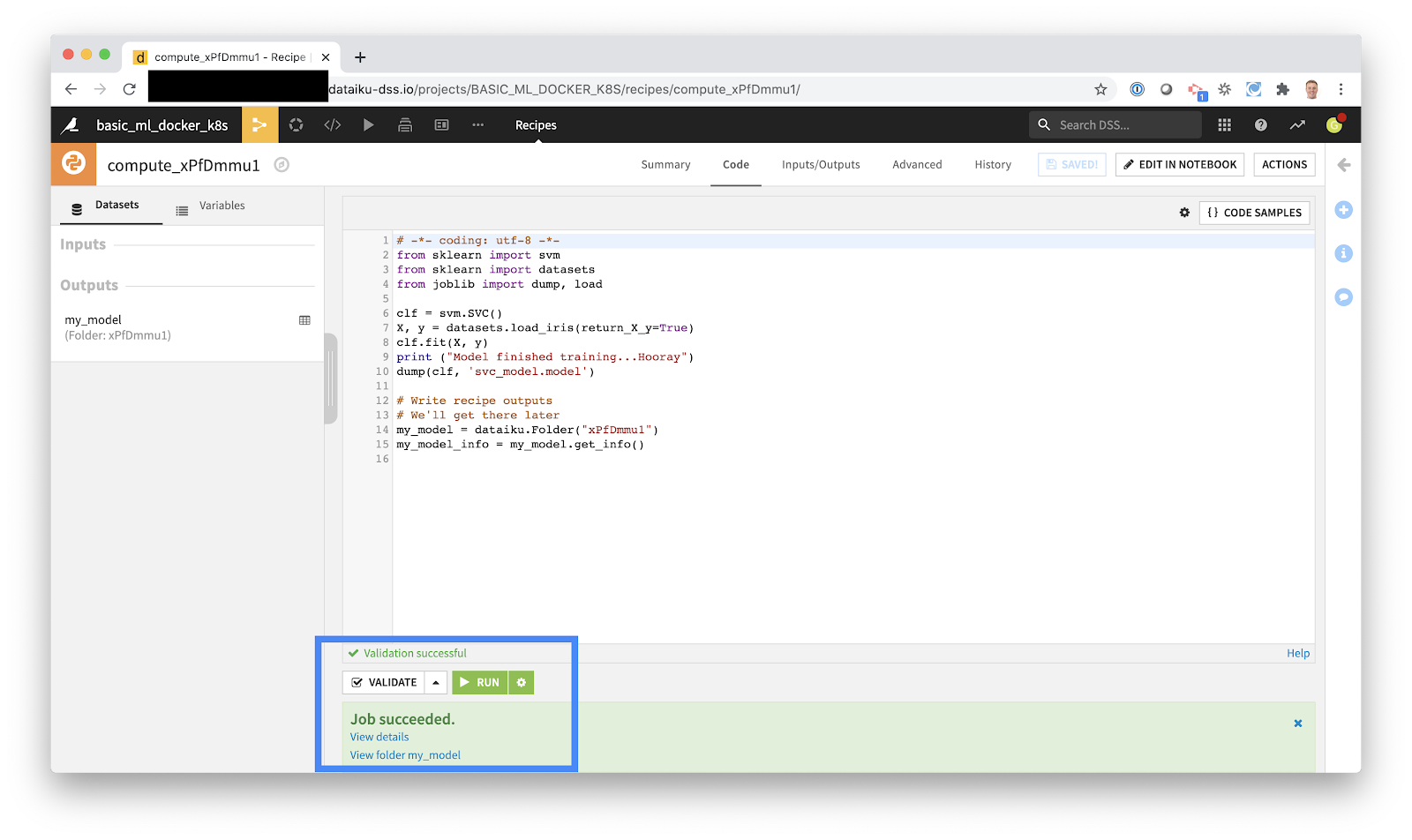
{kind=link}
In order to run this job on Kubernetes, I just need to push Run. Dataiku DSS takes care of all of that Docker and Kubernetes stuff above.. No kubectl or Docker required.
While we could discuss how Dataiku DSS does this for hours, as a user, you don’t have to care. You can just focus on writing your code, analyzing your data, and building your models. And really, that’s where the value is. You shouldn’t get bogged down with infrastructure — you should be able to focus on where you want to go. If that sounds interesting, drop us a line and say hello. And if not, that’s cool too.
A big thank you goes to Harizo Rajaona for the detailed edits. The good metaphors are his and the confusing ones are mine.