




{kind=link}
Introduced by OpenAI in 2021, CLIP is one of the essential elements of the ongoing AI art revolution. But CLIP, a joint text-image model, can do much more than help create beautiful images. In this blog post, I’ll show how CLIP can be leveraged to:
- Search through a collection of images;
- Classify images without training examples (zero-shot classification);
- Classify images with just a few training examples (few-shot classification);
- Help label images very quickly.
You’ll also be able to see these four capabilities in action through a reusable Dataiku demo presented in the last section.
What Are Joint Text-Image Models Like CLIP?
Joint text-image models are deep learning models that can encode pictures and texts so that the embeddings of an image and its text description are similar. It’s this ability to embed images and texts in a common vector space, combined with the astronomic size of the training datasets (e.g., 400 million captioned images for CLIP), that makes these models particularly powerful.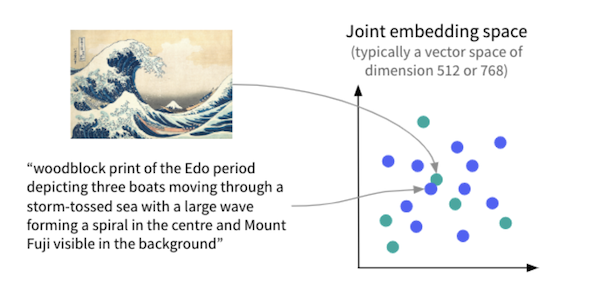
A Running Example
To be more concrete, let’s describe the running example we’ll use below and in the demo. The French National Library (BnF) makes almost 10 million digital documents (printed documents, manuscripts, images, audio recordings, maps, and plans) freely available through Gallica, its digital library. With such a rich collection, a key challenge for BnF is to enrich the documents with relevant metadata to help users (such as students or researchers) easily find the resources they need. Here, we’ll use 486 images from the Japanese prints collection and we’ll assume that BnF would like to classify them into four categories: illustrations, texts, blank pages, and covers.

Image Search
Before tackling this classification task, let’s first see how our collection of images can be explored. By design of the joint text-image models, the semantic similarity of a text and an image can be estimated through the proximity of their embeddings. It is then straightforward to search through a collection of images with a natural language query:
- Compute all of the image embeddings (once and for all) with the image encoder;
- Compute the embedding of a natural language query with the text encoder;
- Look for the image embeddings most similar to the query’s embedding;
- Return the corresponding images as results of the search.
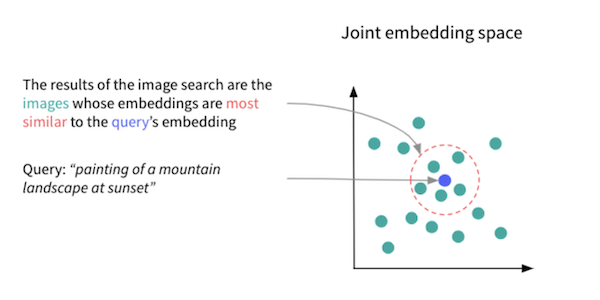
This approach is both powerful and accessible: it doesn’t require any image metadata or label, while the queries can be very specific. The screen capture below shows the results retrieved for a few queries with our images.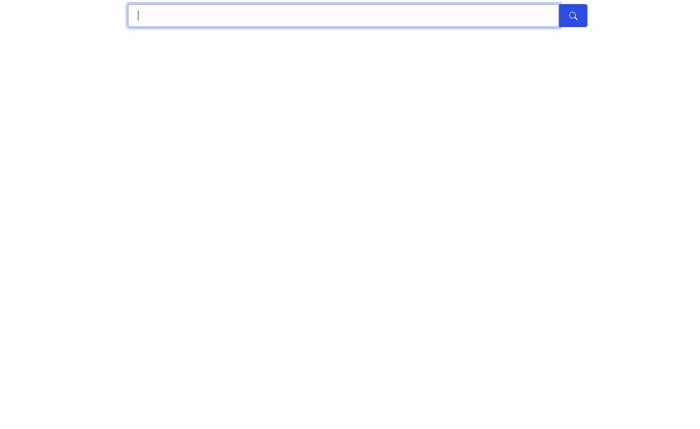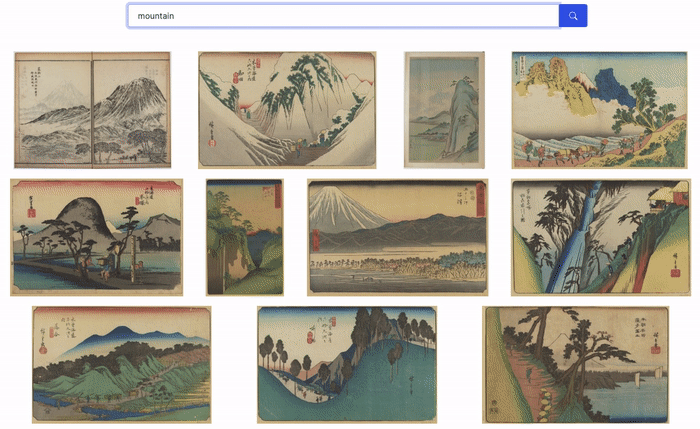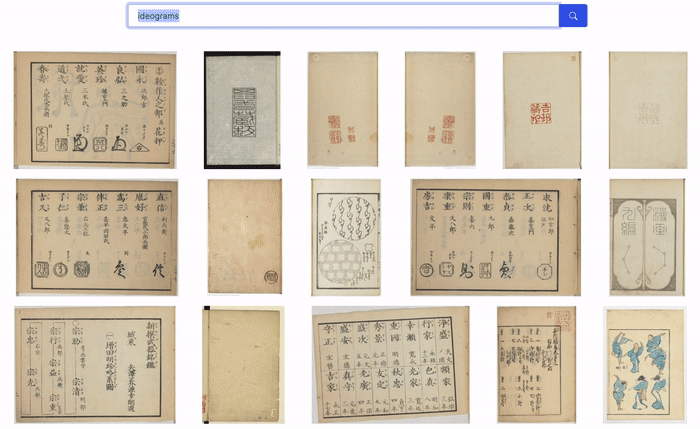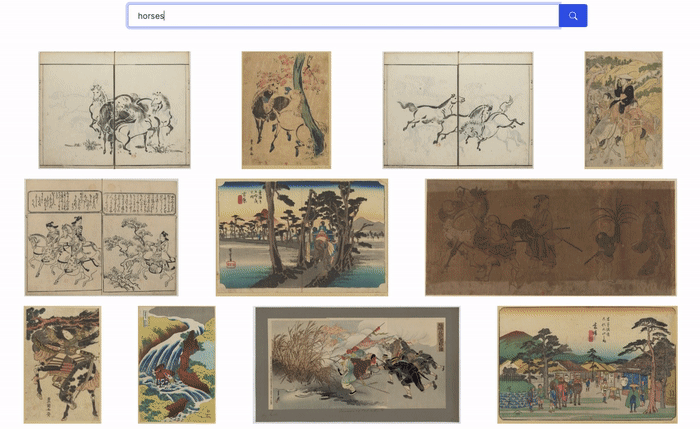
Zero-Shot Image Classification
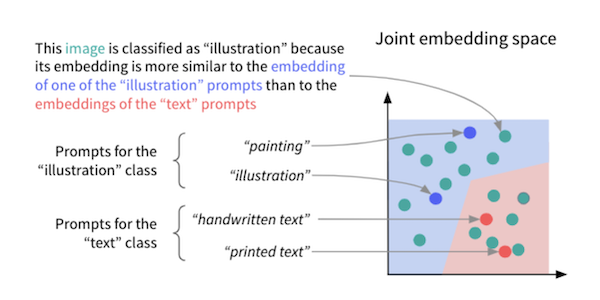
Let’s now turn to the problem of classifying the images, first in a zero-shot classification setting. Zero-shot classification consists in using a pre-trained machine learning model to categorize observations in new classes, without providing any training examples.
It seems magical, but it’s actually very simple with joint text-image models. For each of these new classes, we define one or several prompts, i.e., natural language descriptions of what this class entails. For each image, we then find the prompt whose embedding is most similar to the image’s embedding and we assign the corresponding class to the image.
In our example, we get an 88% accuracy over a hold-out test set of 89 images with the following prompts, which is quite satisfying given the imbalance of the dataset and the fact that no training example was needed:
- Prompt for “illustration”: “traditional Japanese illustration”
- Prompts for “text”: “cursive Japanese ideograms,” “cursive Chinese ideograms,” “printed text”
- Prompts for “blank page”: “light yellow empty page, old book, old paper,” “light yellow empty page, old book, old paper”
- Prompts for “cover”: “book cover,” “book binding”
Of course, a good way to create effective prompts by trial and error is to interactively search through the collection of images with various potential prompts, as described in the previous section.
Few-Shot Image Classification
Joint text-image models can also be used in the few-shot classification setting, i.e., when only a few training examples are available. In this case, we can simply use the image encoder as a feature extractor and run a simple tabular machine learning algorithm, such as a logistic regression or a random forest. In this way, we take advantage of the rich representation offered by the image encoder at little computational cost, compared to the fine-tuning of a computer vision neural network.
The chart below shows the embeddings of the 486 images after dimensionality reduction. With only two dimensions left, the features extracted by CLIP still seem very relevant to discriminate between the four classes.
The table below summarizes the error rate of the zero-shot and few-shot approaches and a baseline approach consisting in fine-tuning a pre-trained EfficientNet B4 model. Strikingly, using CLIP gives close or better results than the baseline with far fewer training examples.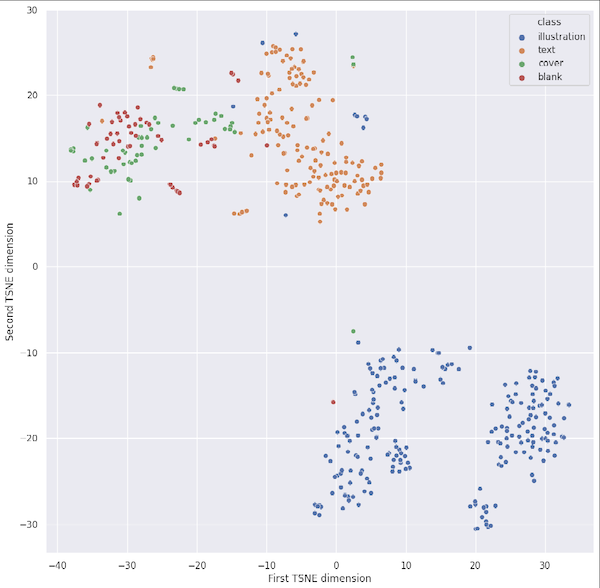

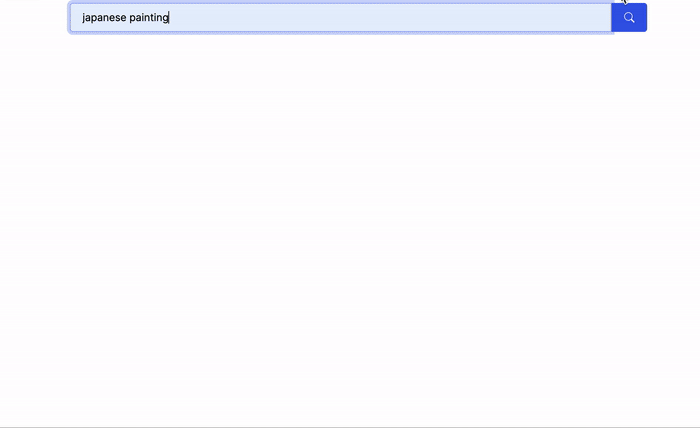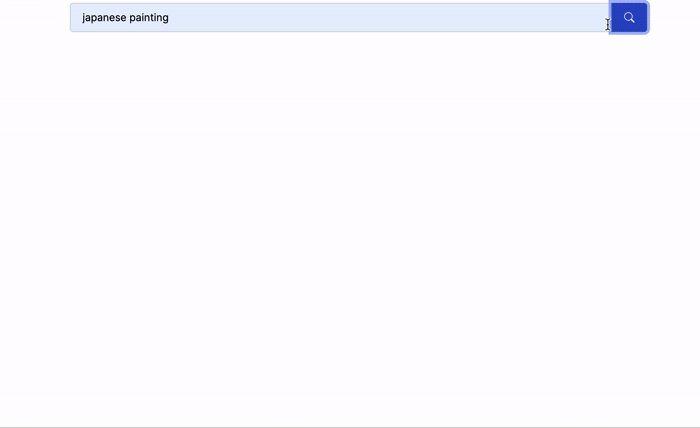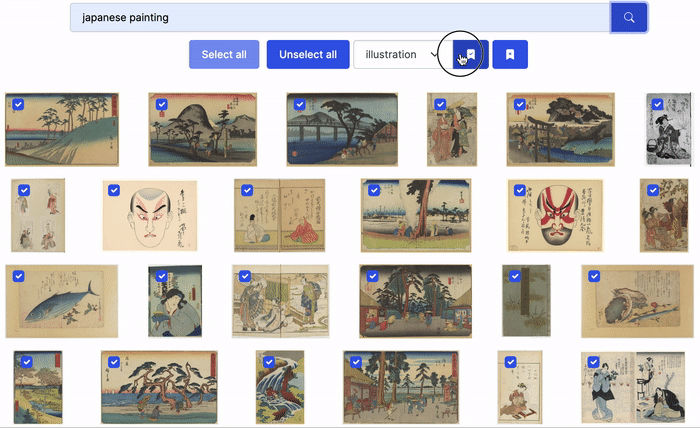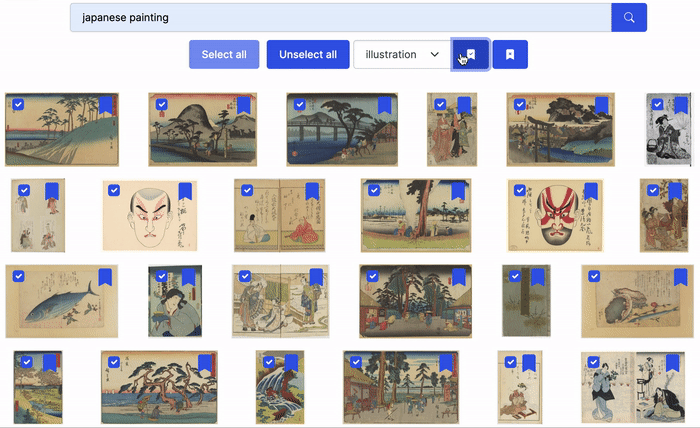
Mass Image Labeling
Even if zero-shot or few-shot image classification yield impressive results, their predictive performance may not be enough for a real-life use case. In this case, joint text-image models can be leveraged to suggest rather than assign classes. The workflow is then the following:
- Formulate a natural language query that should return mostly images of a certain class;
- Visually inspect the search results and unselect those that are irrelevant;
- Assign the targeted class to images that haven’t been unselected;
- Restart from 1. either with the next results of the same query or with a new query.
This approach can speed up labeling efforts, especially in cases where human annotators can determine the classes of small images at a glance.
Seeing CLIP in Action With Dataiku
An online Dataiku demo shows how to encode texts and images and perform zero-shot or few-shot classification. It also includes simple web applications to search images and quickly annotate them in batches. You can download the project, replace the existing images with your own images and simply re-run the Flow to get similar results. Check out the documentation of the project for more details.
If you use CLIP for real-life use cases, please note, however, that such joint text-image models are trained on massive datasets from a wide variety of internet sources and, as a result, incorporate biases and errors. They should then be used with caution. For example, OpenAI warns against untested and unconstrained deployment of CLIP in the model card and opposes any surveillance or facial recognition applications.
Conclusion
Joint text-image models are powerful additions to the computer vision toolbox. In particular, they offer promising alternatives to the standard image classification approach based on fine-tuning pre-trained models. They are particularly well suited for the situation when no or few labels are available.
Since unlabeled images are enough to experiment with CLIP, the barrier to entry is low. Furthermore, if you are a Dataiku user, you can get started in no time with the reusable Dataiku demo presented above.