




Effectively managing and scaling multiple applications leveraging Large Language Models (LLMs) demands more than a mere notebook approach. At Everyday AI New York Tech Day 2023, Dataiku’s Amanda Milberg gave one of the most popular talks of the day. Want to learn how to build LLM applications for production? Watch the full 20-minute talk on how to operationalize LLMs, or read on for the highlights.

At this point, most people have played around with Generative AI or LLM applications. If you’ve developed something lightweight, your stack probably looked a little something like this:
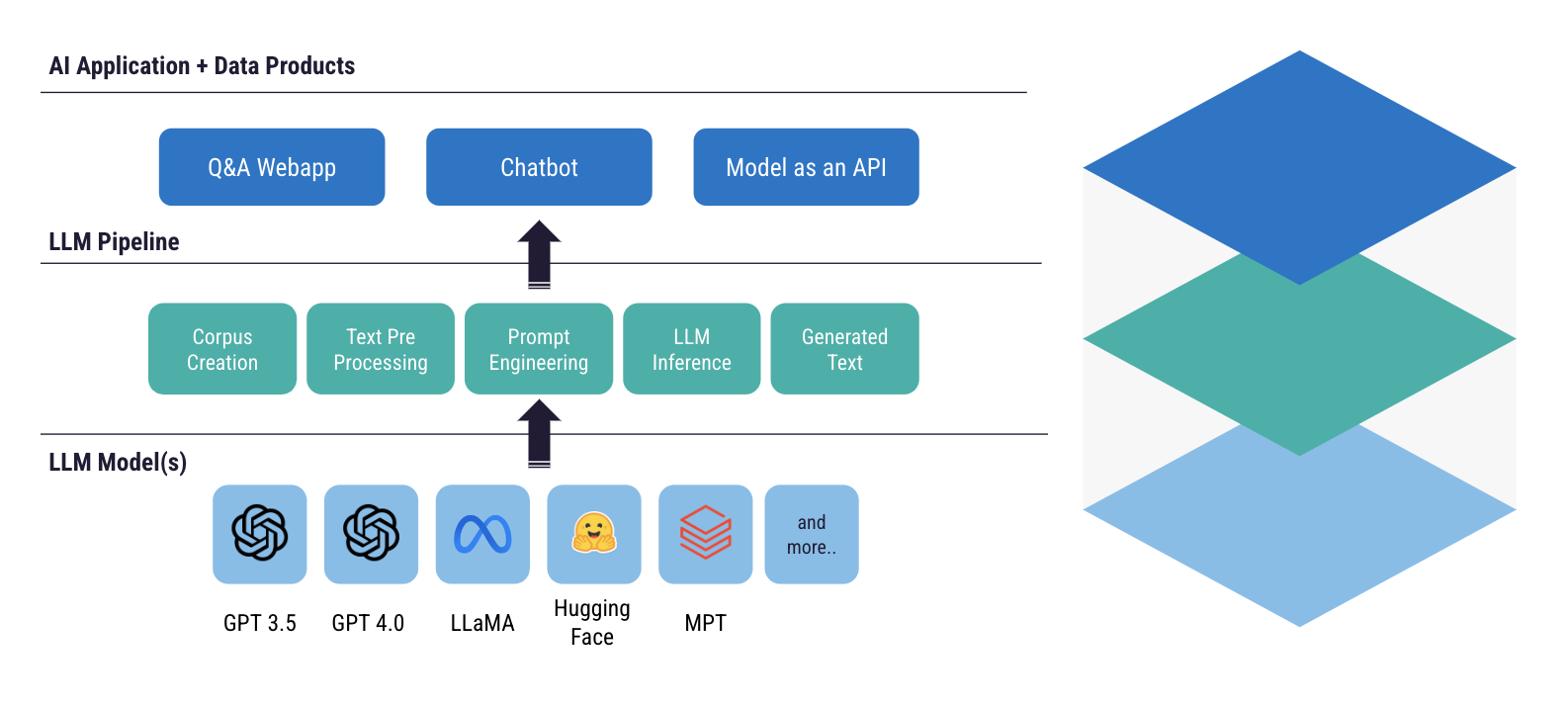
To start a proof of concept (POC) or minimum viable product (MVP), most will connect to an LLM available through an API. Something like OpenAI, open-source models, or offerings from the cloud providers are great places to begin.
From there, you develop an initial lightweight pipeline. This may include prompt engineering or retrieval augmented generation (RAG), for example. You get a generated output, which you surface through some sort of data product. This could be a chatbot, a web application, a model as an API, etc.
This is effective. A good way for C-suite executives to see Generative AI in their business is by getting an MVP out there. But it’s probably not the version that will go to production, and here’s why.
AI Governance for LLM Applications
In most organizations today, putting an LLM in production requires meeting governance and safety requirements. Why? To protect against a growing number of risks, including responsible AI considerations.
Maybe that means having a human-in-the-loop element. Those checks can be critical, even if they are just for a statistical sample of some of the generated results. When building LLM applications for production, you must validate outputs. This is especially true if you surface results directly to, say, customers.
These requirements could also mean having an automated way to detect and remove personal identifiable information (PII) content. Or adding automation (like toxicity detection) to prevent sending harmful content to customers.
Governance can also mean thinking about cost. For example, the cost of API calls or the cost of potential new infrastructure, whether that be a larger CPU or a larger GPU. IT leaders might require a way to monitor both project- and instance-level cost in a dashboard.
Key Elements for LLM Deployment at Scale
While an MVP pipeline might be functional, it probably isn't something that could — or should — be deployed at scale.
In addition to the aforementioned governance and safety considerations, here are some additional key elements. These considerations will help achieve the requirements of stakeholders across IT and the business:
- Agility: The pace of innovation with LLMs today is unprecedented. You probably don't, at this stage, want to hard code gpt-3.5 Turbo into your code. You need the agility to make different model selections and switch between different LLMs. Deployments at scale ensure that as new technologies emerge, you have the ability to adjust and pivot.
- Caching: You don’t want to keep regenerating your LLM with the same information if you already have that answer. This is even more true if you’ve implemented human-in-the-loop checks and that answer has potentially been validated by a person. That’s why you’ll want to provide some sort of caching functionality.
- Monitoring: It’s critical to monitor not only the context of individual queries but also the entire LLM service. If you’re deploying multiple applications and relying on multiple LLM services, it’s primordial.
That’s where the LLM Mesh comes in as a common backbone for Generative AI applications. The LLM Mesh promises to reshape how analytics and IT teams securely access Generative AI models and services.
“This LLM mesh is really what's going to help us scale not just one, not two, but N LLM applications in production.”
— Amanda Milberg, Senior Partner Sales Engineer @ Dataiku

{kind=link}