




I’m not going to lie to you. Despite years of hype, AI is still in its infancy in the pharmaceutical industry (feel free to reach out to me for a lively debate if you disagree). Moreover, let’s all admit to ourselves that, when we say “AI,” we broadly include machine learning (ML), data science, and really any efforts that advance digitization.
I began my career in this space 17 years ago with genomic research applications (methodology to correct for bias in genome-wide DNA variant analyses). I like to say I was working with big data before big data was a big thing. I shifted to include integrative genomics, biomarker discovery, translational research, clinical research and then planned clinical submission analyses and clinical operations in my experience toolbox. I now support data science applications broadly across the health and life sciences industry; quite the antithesis from exploratory core lab and consortia research where I started.
As the field has matured, we continually learn that we don’t yet know enough about complex biological systems (an understanding of which much of therapeutic development relies). We also are learning that the chasm between exploratory translational science and regimented clinical research narrows around a common challenge: how to move beyond explanatory or deterministic endpoints to predictive intelligence (ML application) that delivers realized, reproducible, and operational business value.
In the broader life sciences industry value chain, Dataiku has seen great success with key use cases in the evolving maturity model to embed AI into business practices — often in commercial (sales and marketing) analytics divisions. This success is paving the road to expanding use case adoption in R&D, operations, manufacturing, supply chain and patient engagement.
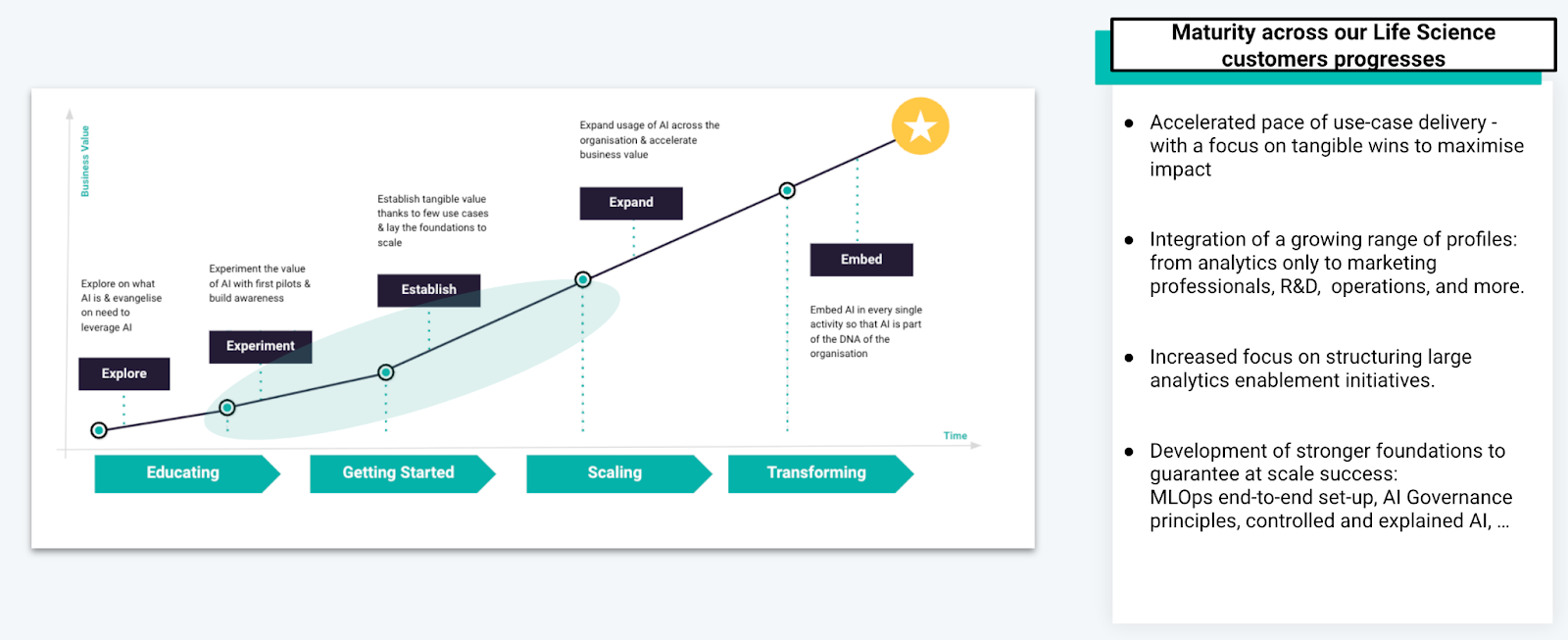
Given the critical necessity of R&D (pharma/biotech re-invests up to triple of revenue compared to other industries), 81% of life science research leaders are prioritizing investments in AI to improve productivity, reduce R&D costs, and improve pipeline diversity. Let’s explore some of the use cases where we have seen innovation leaders anticipate/begin to deliver success in the “digital transformation race.”
Acceleration in Discovery and Development
Several years ago, I spoke with a gene therapy startup about ML applications with amino acid sequences. We agreed the model was not very useful unless we could predict protein folding patterns, and we all had a good laugh. DeepMind’s Alphafold ability to predict nearly any 3D protein structure is a remarkable AI achievement in this field, but designing new proteins does not “solve” designing a new drug. It’s worth noting that even as AI accelerates science, the first map of the human genome was released nearly 20 years ago, and we are just beginning to consider polygenic risk scores in clinical practice.
That said, AI-enabled R&D programs for discovery and design of new molecular drug targets have become an increasingly popular trend, with promise of increasing efficiency and success in bringing a new molecule to trial. Early signals of value gains are cost improvements with drastically reduced timelines and expanding molecular diversity. If you are asking, “How should I get started?” then consider an everyday approach that starts with accelerating digitalization (e.g. use of electronic lab notebooks), moving much of the bench experimentation off of laptops, and making it accessible for advanced insights with modern data science platforms like Dataiku. There, historical experiment trends can be explored and chemical compound databases can be mined with ML.
Another area where ML, along with knowledge graphs and graph databases, can provide value is in the identification of repurposable drug candidates. You can explore our Dataiku Business Solution to leverage graph analytics in drug repurposing with Neo4J here.
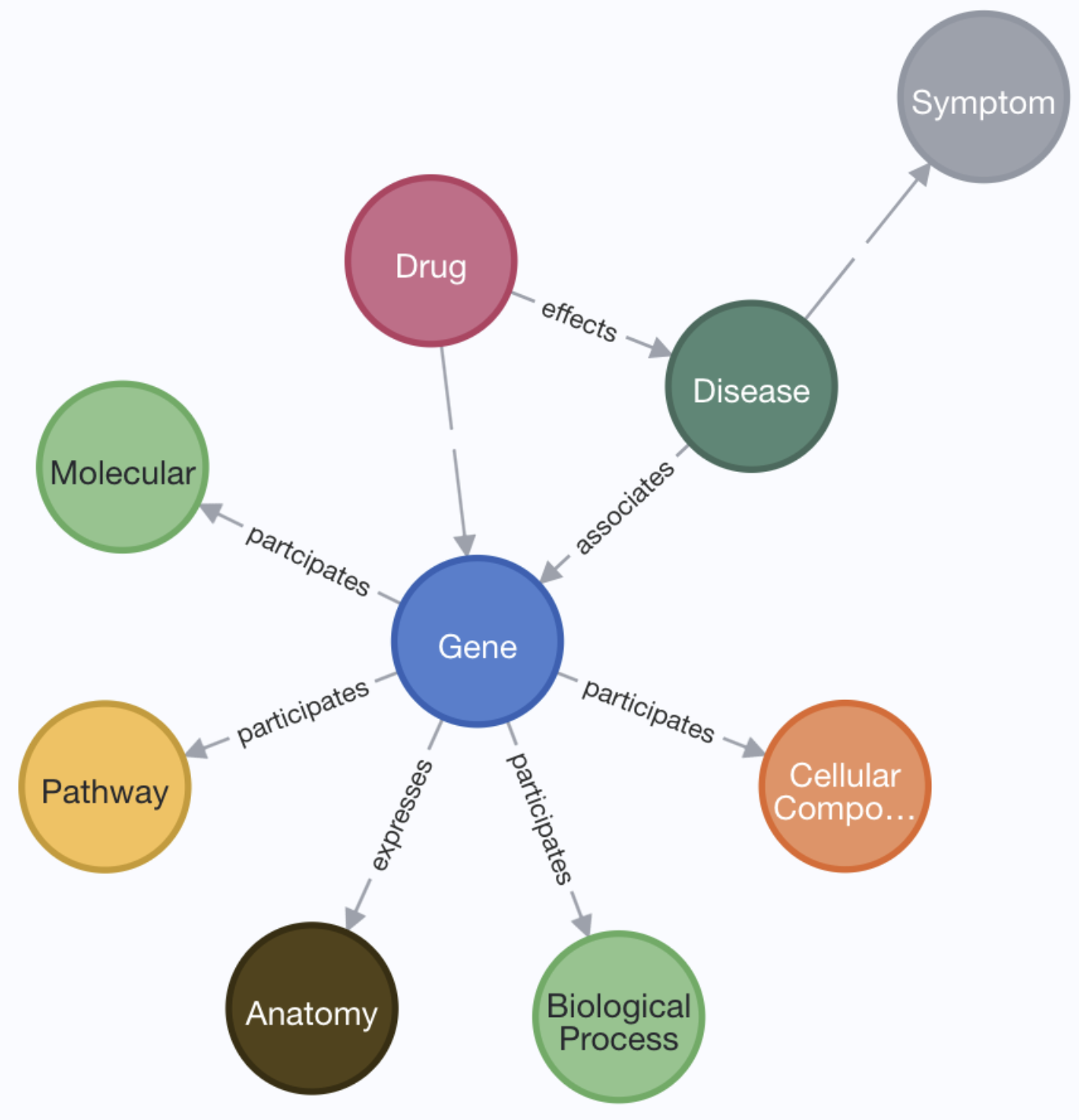
Pre-Clinical and Translational Science: The 3 In-s
ML is finding a strong role in in-silico, in-vitro, and in-vivo applications. In-silico experiments (computer simulations) can provide rapid insights on dose-response modeling of body processes. One of our innovative biotechnology customers uses Dataiku for high-throughput image modalities processing for in-vivo animal models. If you prefer the moonshot use cases, the advancements with organ-on-a-chip in-vitro research may be for you.
Clinical Research and Trial Operations
There are huge hurdles to discovering and proving value of “innovation side projects” that explore the predictive capacity of clinical data, the largest being that the core business process in trial submission work is tightly regulated deterministic endpoints. Small, highly structured data size (as produced by traditional planned analyses) is often thrown up as another barrier to adoption of ML, something that has been debunked by none other than the co-founder of Google Brain.
This paradigm will only change when business leaders prioritize investments into both novel areas of clinical research that demand innovation as well as traditional areas with great opportunity — to ultimately increase productivity, efficiency, and collaboration.
Innovation areas driving clinical data science include some of the following:
- Novel trial design including decentralized and/or pragmatic trials driven with real-world data to increase diversity.
- Novel data sources such as digital biomarkers from wearables, social data, patient-reported outcomes, and unstructured data from virtual visits (chat or video transcripts).
- Novel data considerations such as trial aggregation and external (or even synthetic) control models.
Improving Traditional Clinical Business Processes With ML
Unfortunately, you can’t “quit your day job” to spend time solely in these innovation areas. For that reason, core change in the value and role of ML will come from how it improves traditional processes. Looking for a place to start? Here’s a non-exhaustive list of use cases where Dataiku is already helping or can help ML and advanced analytics find its place in clinical research and operations in the life sciences industry:
- Patient criteria, selection, and recruitment strategies
- Improving clinical site selection and optimizing site operations
- Budgeting and resource allocation for trial execution
- NLG (natural language generation) of protocols, analysis plans, and case report forms
- Pharmacovigilance and global safety signals processing and detection
- Site and patient anomaly detection for quality or operational risk signals
- Detection of early efficacy, disparate outcomes, safety concerns, or adherence issues that impact the success of trial milestones
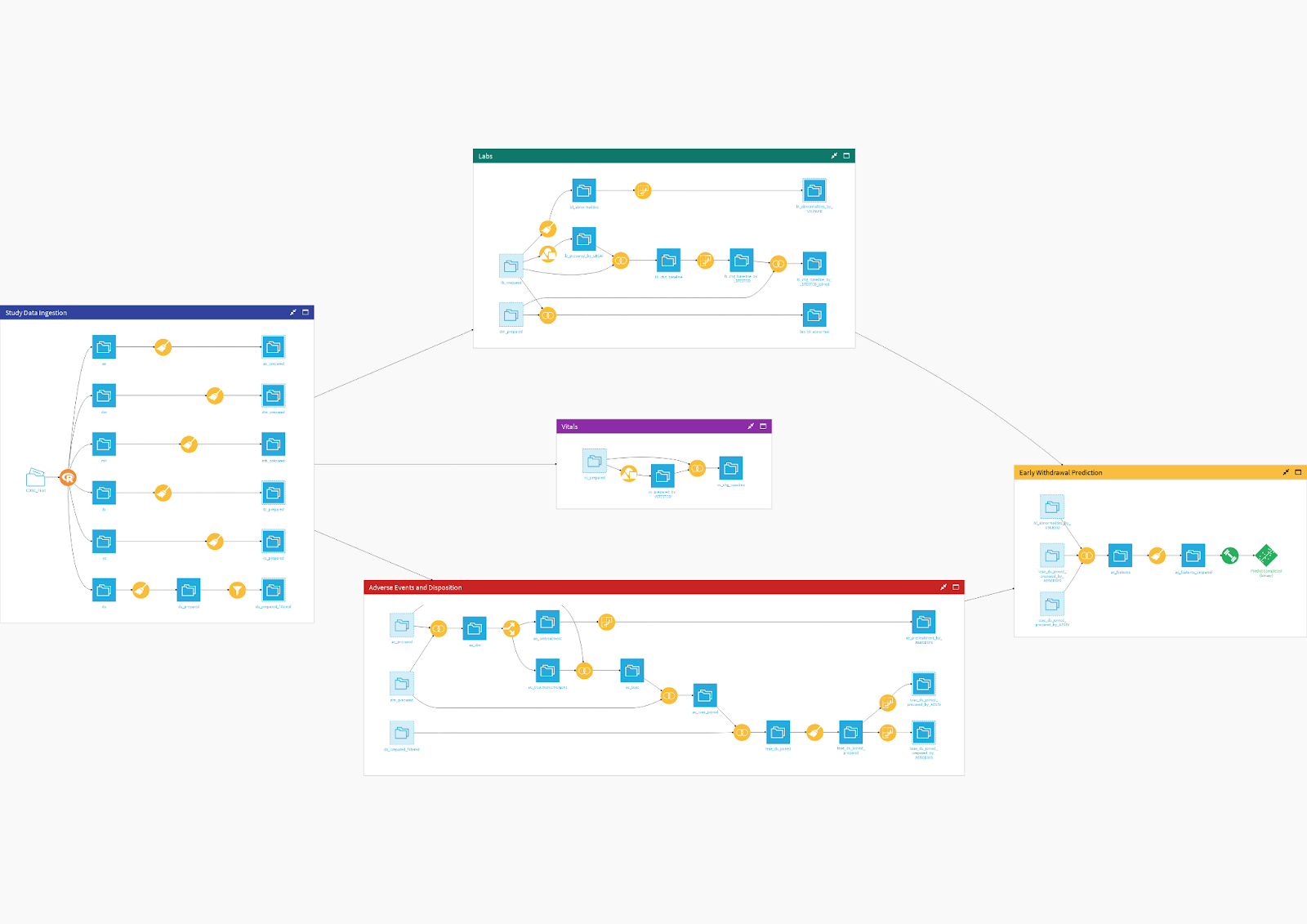
Speaking to this last bullet, I personally found great pleasure in putting together a simple project using the CDISC Pilot Project study. A well-known outcome documented in the results of the Alzheimer study was a lack of evidence for efficacy impacted by an unusual amount of early withdrawals. The project below showcases processing baseline laboratory abnormalities and the occurrence of treatment-emergent adverse events as features to predict a patient’s disposition event of study completion or withdrawal.
{kind=link}
Not only can this provide rapid insights into safety signals in trial outcomes and inform further trial phase operations, but I found it quite beautiful and incredibly rewarding to see the visual display and minimal effort of an analysis that I’ve done often through messy versions of multiple code bases (also for code-heavy analyses, the new Code Studios feature in Dataiku 11 is a game changer). Sharing and collaborating with such a project can empower diverse users in data science, biostatistics, data monitoring, and medical review teams, leading to more efficient, effective, and safe clinical research.
Learn more about Dataiku's collaboration capabilities here.