




Data science in the energy industry has been around for quite a long time, with innovative techniques such as neural networks dating back to the 1980s.
Yet Natural Language Processing (NLP) is one of the lesser-explored domains in the sector. This branch of machine learning and AI deals with human language and, more specifically, with bridging the gap between human communication and computer understanding. An exciting opportunity hence lies ahead for the industry, which now benefits from improved access to a wealth of unstructured data.
Read on to discover two innovative use cases that the data team at SLB has implemented in Dataiku to leverage NLP in subsurface geology. The first is a simple yet efficient pattern recognition model. Then, to dig deeper into millions of documents of unstructured data, they are leveraging word associations through an algorithm known as Word2Vec.

If you’re looking to get up to speed with NLP, check out the NLP 101 ebook!
What Is the Value of NLP for the Energy Industry?
It all comes down to the numbers: a single rig rental for offshore drilling costs several hundred thousand dollars per day. This means that any errors on the exact location to build the platform can cost billions of dollars to the organization.
The key to successfully locating an offshore drilling platform is geological understanding. The process typically involves browsing a wealth of research publications on the area to look for a subzone of interest (e.g., one specific area in Norway) or find analogs to learn from similar solutions in other areas. It would previously take months for a geologist to find this information but, with NLP, the search is reduced to milliseconds.
The drilling process also requires teams to sift through hundreds of reports from the field to leverage pre-existing, organizational knowledge — for instance, engineers writing down their rig observations. Being able to process this goldmine of information and draw insights is paramount; it increases confidence in the decision and minimizes the risk of failed exploration.
Use Case 1: Limited Data With Patterns
Two main questions must guide geologists regarding the drilling decision:
- Is it a good reservoir, i.e., worth the investment?
- How deep is the reservoir? This will inform the depth of the drilling and therefore the overall cost of the operation.
Sampath (Product Analytics Champion) and his team at SLB have created two categories of sentences to answer these, and they set up a rule-based match in Dataiku to extract the name and depth of a target reservoir in the reports. Then, they run a sentiment analysis via Dataiku’s modeling interface to find out the expected quality of the reservoir.

This technique works very well with limited data, in order to understand patterns based on the extraction of fixed factors. However, when the volume of data increases, they need to shift to a kind of unsupervised learning model so as to not only leverage visible patterns but also infer information from contextual data, such as representations from word embedding within a given sentence.
Use Case 2: Word to Vectors (Word2Vec)
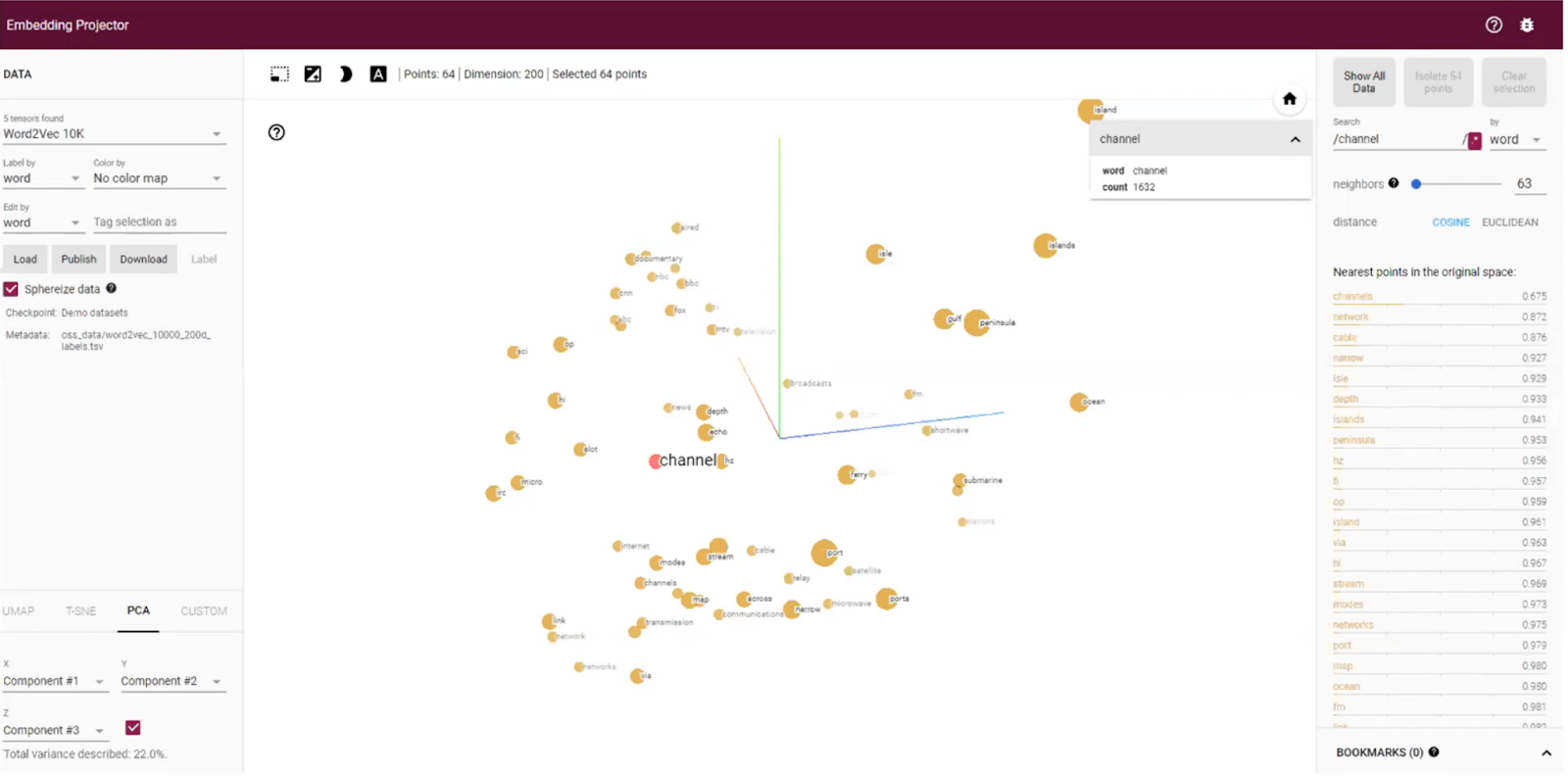
The team has used a retrained word-to-vectors (Word2Vec) model to uncover patterns through understanding word associations. For instance, they would use it for researching which cement to use in an area. Although the word “cement” might not be directly referenced, the tool will draw insights from where associations with this word are the most common and point to these areas to inform the decision. Another example is the association of “channel” and “island” which, interestingly, may not be that close in the text but are commonly used around similar terms:
{kind=link}
The solution also helps identify gaps in the data such as misspelling, synonyms, etc. in a tailor-made way for domain language. This is especially important when the data originates from field reports, where the speed and scale of operations might lead to inconsistencies or mistakes.
The team now has the capacity to query data from six to eight million documents in a matter of milliseconds — and not only based on designated keywords, but with those expanded keywords giving them the ability to make decisions based on all the data at their disposal.