




{kind=link}
A significant quantity of training data has long been a key requirement of successful machine learning (ML) projects. In this blog post, we will see that new state-of-the-art approaches make it possible to mitigate or overcome this constraint in the context of computer vision.

Zero-shot object detection (left) and segmentation (right) for 3 classes: chair, screen, dog. Photo by devn
Let’s imagine that you want to automatically identify and locate specific objects in pictures. This task is named object detection (respectively, semantic segmentation) when the location of the objects is described through bounding boxes (respectively, pixel-level classes). In this context, the traditional ML approach is the following:
- Collect many images with one or several of these objects;
- Annotate the images with the category and precise location of the objects;
- Use the annotated images to train or fine tune a deep learning model;
- Predict the class and location of objects on new images with the trained model.
However, finding and labeling enough images may be impractical or expensive. If this is indeed the case, zero-shot and few-shot methods can come to the rescue. In the zero-shot and few-shot settings, no example or just a few examples are provided at inference time. This blog post presents such approaches in the context of object detection and segmentation. In particular:
- We’ll provide a high-level overview of CLIPSeg, a recently released language vision model that can segment images in a zero-shot or few-shot setting;
- We’ll similarly describe OWLViT, CLIPSeg’s counterpart for object detection;
- We’ll show and discuss results obtained from these models;
- We’ll share a Dataiku demo that can directly be reused with your own images.
CLIPSeg for Zero-Shot and Few-Shot Segmentation
CLIPSeg is a deep learning model composed of a text encoder, an image encoder, and a decoder. The image encoder and the text encoder are simply those of a frozen CLIP model and the decoder is specific to CLIPSeg and fine tuned on a large segmentation dataset (340,000 images).
In the zero-shot setting, if the user wants to locate objects of a certain class in an image:
- The user needs to describe the class in natural language;
- The text encoder converts the natural language query into a CLIP embedding;
- The image is injected into the image encoder;
- The decoder takes as inputs the CLIP embedding computed at Step 2 and the activations of the image computed at Step 3 and returns per-pixel scores that can be converted into a segmentation mask.
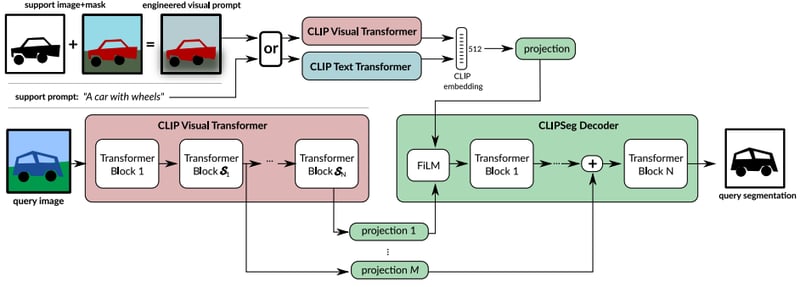
Architecture of the CLIPSeg model. Illustration from the original paper
In the one-shot setting, one image of the target class is provided and we assume that it is impossible to describe the target class in natural language (or that CLIP would be unable to properly encode this description). In this case, we can simply replace the CLIP embedding of the natural language query with the CLIP embedding of the example image. This is sensible because, by design of the CLIP pre-training procedure, the CLIP embedding of an image is somewhat aligned with the CLIP embedding of its description.
In the few-shot setting, following the same logic, we can just average the CLIP embeddings of the available images.
A nice feature of this approach is that a segmentation mask is unnecessary. However, as pointed out in the paper introducing CLIPSeg, this only works if the target class is well exemplified in the available images. Cropping to the object and blurring the background help the model focus on the right part of the images.
OWLViT for Zero-Shot and Few-Shot Object Detection
OWLViT, a pre-trained model for zero-shot and few-shot object detection, shares many commonalities with CLIPSeg: It combines a text encoder, an image encoder, and a lightweight task-specific module, with the text encoder and the image encoder contrastively pre-trained on a huge dataset of captioned images.
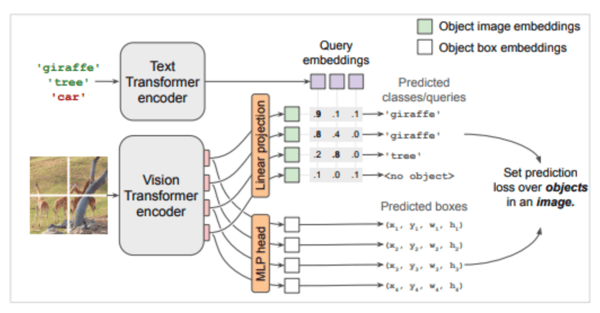
Architecture of the OWLViT model. Illustration from the original paper
There are, however, some differences. The task-specific module is composed of two heads attached to the image encoder. Their purpose is to describe candidate bounding boxes with their coordinates and an embedding that represents their semantic content. These two heads are fine tuned, along with the text encoder and the image encoder on several large object detection datasets (two million annotated images in total).
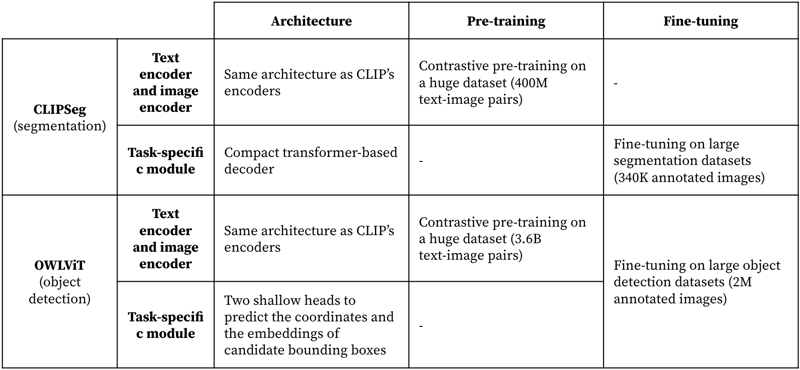
Similarities and differences between CLIPSeg and OWLViT
In the zero-shot setting, given an image and a prompt that describes the target class, OWLViT provides a large list of bounding boxes and a score for each of them. If we define a threshold on the score or a maximum number of boxes, we can remove low-confidence results. Optionally, we can also filter out boxes with a high intersection-over-union ratio with a better-scored box.
In the few-shot setting, we assume that we have a few training images with the ground truth bounding boxes for a target class. Let’s start with the simplest case: a single training image with a single ground truth bounding box. In this case, we can obtain the list of predicted bounding boxes and predicted embeddings and select the predicted bounding box with a high overlap with the ground truth bounding box.
We can then substitute the query embedding that would have been obtained through the text encoder with the predicted embedding of this bounding box. If there are several predicted bounding boxes largely overlapping the ground truth bounding box, the original paper suggests a heuristic to select the one to use.
The approach is the same with several images or several ground truth bounding boxes. We just need to average the embeddings obtained for each of these bounding boxes.
Testing the Models
We started to experiment with both CLIPSeg and OWLViT in several ways:
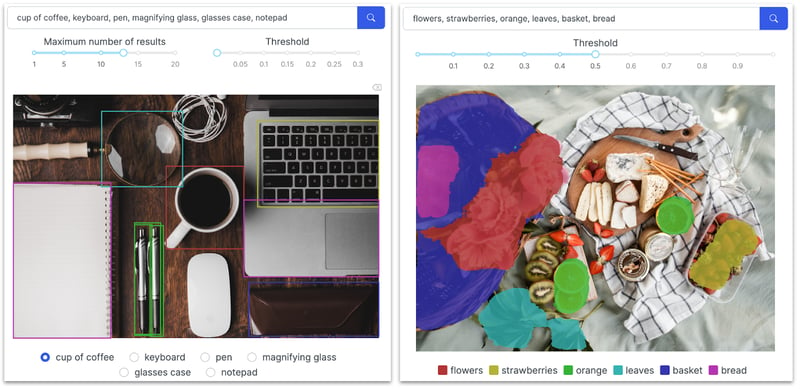
- Zero-shot object detection and segmentation: We tested various queries on a few images with everyday life scenes and common objects through two web applications published on the Dataiku gallery, one for segmentation and one for object detection.
- Few-shot object detection: We used the Microcontroller Object Detection dataset available on Kaggle. This dataset includes images with four types of microcontrollers (“8266 ESP,” “Arduino Nano,” “Heltec ESP32 Lora,” “Raspberry Pi 3”). We used 35 training images totaling 10 instances of each class.
- Few-shot segmentation: We used the same dataset, with three training images of each class, with only the corresponding objects over a neutral background. We augmented each of these 12 images with 90°, 180°, and 270° rotations.
Based on these preliminary tests, our initial conclusions are the following. First, the zero-shot predictive performance is quite convincing for both CLIPSeg and OWLViT for common objects.
When it comes to few-shot object detection, the results are satisfying: 0.71, 0.71, and 0.53 for the average precision with IoU=0.5, IoU=0.75, and all IoUs. They are broadly comparable to those after fine-tuning a Faster R-CNN in Dataiku’s example project for object detection, even though much fewer training images were used (35 instead of 120): 0.87, 0.39, and 0.43 for the average precision with IoU=0.5, IoU=0.75, and all IoUs.
In contrast, the predictive performance for few-shot segmentation appears quite good to localize the objects but disappointing to categorize the objects in the various classes.
In all cases, it is possible to adjust the sensitivity of the detections. For example, with OWLViT, it is possible to define the maximum number of bounding boxes selected or the minimum score to keep candidate bounding boxes. With CLIPSeg, we can tune the decision threshold for the per-pixel logits.
In both cases, the right thresholds are quite dependent on the target classes and this cannot be automatically calibrated since we only have a handful of training images at best. The fact that we used the same thresholds for all classes might be the reason why CLIPSeg was not able to properly discriminate between the various classes in the few-shot setting.
CLIPSeg and OWLViT can both be conveniently used in interactive mode. Indeed, the computations related to the image and the query are done in parallel before their results are jointly processed by the task-specific module. Since the most computationally expensive step is the encoding of the image, it is possible to perform this step just once and cache the results. The user can then test various queries or various detection thresholds without being penalized by some excessive latency.
Overall, given the good but imperfect predictive performance, the need to experiment with the prompt and the detection thresholds, and the possibility to use CLIPSeg and OWLViT interactively, the most natural use case for these models is to accelerate labeling tasks.
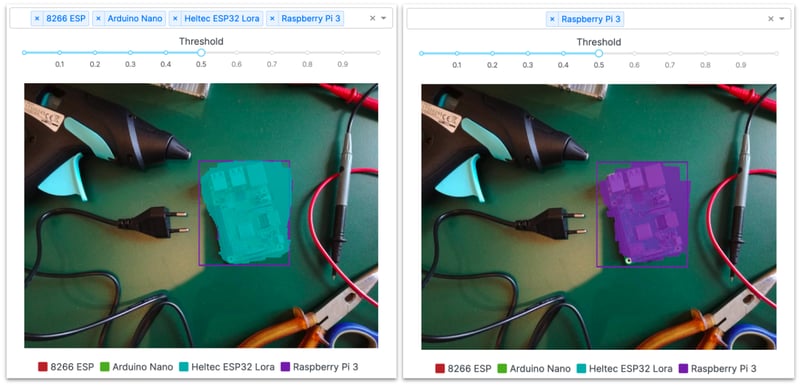
Example of good localization but improper categorization with few-shot segmentation and a single decision threshold (the color of the rectangle corresponds to the ground truth class)
Leveraging Language Vision Models in Dataiku
An online Dataiku demo shows how to perform zero-shot and few-shot object detection and segmentation. It includes simple web applications to interactively perform these tasks. You can download the project, replace the existing images with your own images, re-run the Flow, and re-launch web applications to get similar results. Check out the documentation of the project for more details.
Conclusion
The techniques presented in this blog post illustrate how advanced pre-trained models can directly be used, not only with common concepts most likely present in their training dataset but also with original concepts. The entry barrier is particularly low thanks to the possibility to express queries in natural language and the limited data and computational requirements.