




{kind=link}
When it comes to being a data-driven company, it's usually not the data itself that's a problem - most enterprises have a wealth of it available. Instead, it's organization and being able to pull real value out of that data that can present challenges. 
Immuta CEO Matthew Carroll (pictured above) spoke with Dataiku CEO Florian Douetteau about the relationship between data governance and machine learning and their impact on the future of business intelligence.
Matthew Carroll (MC): Hey Florian, it’s great to connect again. I’m always excited to pick your brain, and want to ask you some questions about data governance—issues that are near and dear to our heart at Immuta. What challenges do you encounter when it comes to collaboration and governance with machine learning?
Florian Douetteau (FD): In lots of domains, machine learning requires a mix of business expertise and technological expertise to be applied efficiently. In some situations, tools can compensate for technological expertise, and business experts can start using machine learning algorithms by themselves. In other situations, it’s the reverse: business expertise is accessible enough through meaningful documentation for a technology expert to build relevant models. But in most situations, the complexity of the problem requires a business expert and a tech expert to collaborate. What's more important is that almost no machine learning by-product (model, data, etc.) is static. As it evolves, the person that adapts it to new business constraints might not be the person that created it initially. People collaborate across time. As a consequence, either because of complexity or governance requirements, collaboration is key for all real-life machine learning applications.
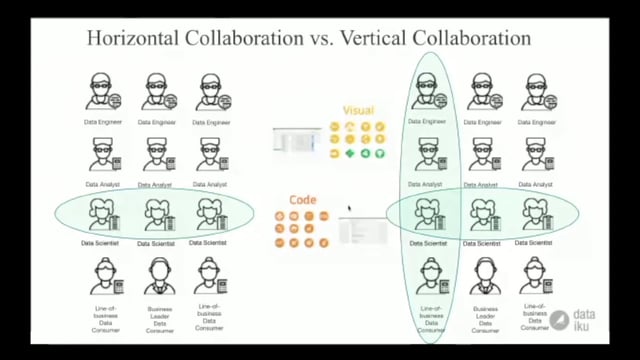
The complexity of many data questions require collaboration across domains, not just among them.
MC: I think we both agree that machine learning is the future of business intelligence. There’s simply too much data moving at too high of a velocity for humans or simple analytics tools to find patterns in the data. Given that’s the case, what does the modern machine learning stack need to include? Asked another way, what technologies or workflows are critical to implementing responsible, end-to-end machine learning?
FD: The core technology part of machine learning contains of a set of algorithms that can now be well implemented across multiple channels - either with open source or via commodity platforms. Random Forests, Boosted Trees, Deep Learning, etc. That being said, the most important thing about machine learning is probably that it needs to be "end-to-end" in order to be relevant. How you connect your data collection, data transformation, feature engineering, and machine learning components is key. There's an IT side of this, which relates to how your machine learning by-products will be applied in production once they leave the comfort of the data science lab. There's also a governance side of it, because implementing machine learning on top of a stack that is not integrated well enough will lead to high maintenance costs over time. How can you maintain a predictive model through time if you're not 100 percent sure that your very initial data parsing components are correct and transmit the data effectively?
MC: The data science platforms marketplace is complex and overwhelming, and I hear this all the time, from analysts all the way to folks in the C-suite. What advice do you give prospective customers when they’re looking for their data platform of record?
FD: One piece of advice would be to make sure it's a tool for the whole team and not just a tool for yourself or for the people most eager to get a platform, and make sure that everybody on your team can use the platform in a relevant capacity. Can they really understand what's happening even if they haven't built the whole project? Can they be fairly independent in front of a new project? If they’re trying to accomplish a simple task, would they be able to do it in the tool? Would the most tech-savvy be inclined to use the tool rather than go back to their own closed environment?

Having a strong data culture means getting the whole team involved, especially through a tool that everyone can use.
MC: In 12 months the EU’s GDPR will come into effect, and with fines of up to 4 percent of global revenue, it will impact practically every company collecting or using user data in Europe. What level of concern are you seeing in clients and prospective customers?
FD: The impact of the GDPR is still being evaluated by most companies. Most of them fear an increase in terms of cost for managing data and are looking for risk mitigation strategies. It's clear that having more transparent processes and ways to understand the impact of data is key for mitigating those risks. Again, it relates to the importance of end-to-end workflows.
MC: We go back a ways, and I know all about Dataiku and where you’re going, but some of our readers might not. So why should companies work with Dataiku? And what’s next for you guys?
FD: We created Dataiku in 2013 with one mission in mind: to enable our customers to successfully take predictive analytics and machine learning projects from inception to production and see real impact on their business thanks to their data projects.
But today it’s not only about getting value from data, it’s about providing a structure across an organization where thousands of people build and consume analytics. Therefore, what’s next is building the tools that support a data culture and operations that assist customers as they pioneer innovations that require the joint forces of data scientists, analysts, IT, and business teams. After all, true innovation sits at the intersection between technical and business skills, knowledge, and teams.
Data science and analytics will be among the most important driving forces of change in the next decade and any sophisticated data science operation will need to leverage robust data science and ML environments across the enterprise to drive innovations at scale.