




{kind=link}
With search engines and now AI assistants like ChatGPT, we have powerful tools to retrieve relevant information from the internet. However, organizations also need to extract information from non-public documents such as meeting minutes, legal documents, product specifications, technical documentation, R&D reports, business procedures, and so on.
This blog post:
- Shows how to craft a simple question-answering system focused on a specific collection of documents, using GPT-3 and a “retrieve-then-read” pipeline;
- Illustrates how this method can be applied to a practical example based on Dataiku’s technical documentation;
- Presents the corresponding Dataiku project that you can reuse for your own use case.

Autoregressive Language Models and GPT-3
In their modern incarnation, language models are neural networks trained to compute the likelihood of sequences of words. In particular, autoregressive language models estimate the probability of the next token (i.e., a word or part of a word) given all the preceding tokens.
The best-known autoregressive language model is GPT-3, announced by OpenAI in May 2020. GPT-3 was trained at an impressive scale: It has 175 billion parameters and its training dataset nears 500 billion tokens (compared to three billion tokens for Wikipedia). As a result, although it was trained solely for next token prediction, GPT-3 can effectively perform a variety of natural language processing tasks without further training: question answering, summarization, translation, classification, etc. This generalization is referred to as zero or few shot learning depending on whether examples are provided at inference time.
The key to leverage these capabilities is to provide the right prompt (i.e., the initial text that the model will then complete), one token at a time. The following diagram illustrates what the prompt and the completion by GPT-3 can look like for a question answering task.
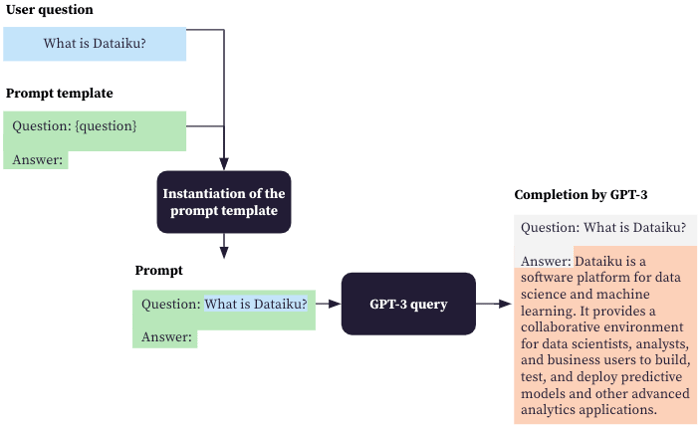
Naive question-answering pipeline leveraging GPT-3
OpenAI recently released GPT-3.5, a series of improved GPT-3 models, trained on a corpus collected until June 2021 and fine-tuned on various tasks. For the sake of simplicity, we will only use “GPT-3” below to refer to all these models.
The "Retrieve-Then-Read" Pipeline
In the question answering example above, the model serves as both an assistant and an expert: It interprets the question and formulates an answer based on its own knowledge. However, this knowledge is limited and, in particular, it does not cover recent or non-public documents. Fortunately, GPT-3 can still be a useful assistant with a retrieve-then-read pipeline.
Let’s assume that we want to get answers based on a specific collection of documents. As illustrated in the diagram below, the retrieve-then-read pipeline entails the following steps:
- Receive the question from the user;
- Retrieve from the collection of documents the passages most semantically similar to the question;
- Create a prompt including the question and the retrieved passages;
- Query GPT-3 with the prompt.
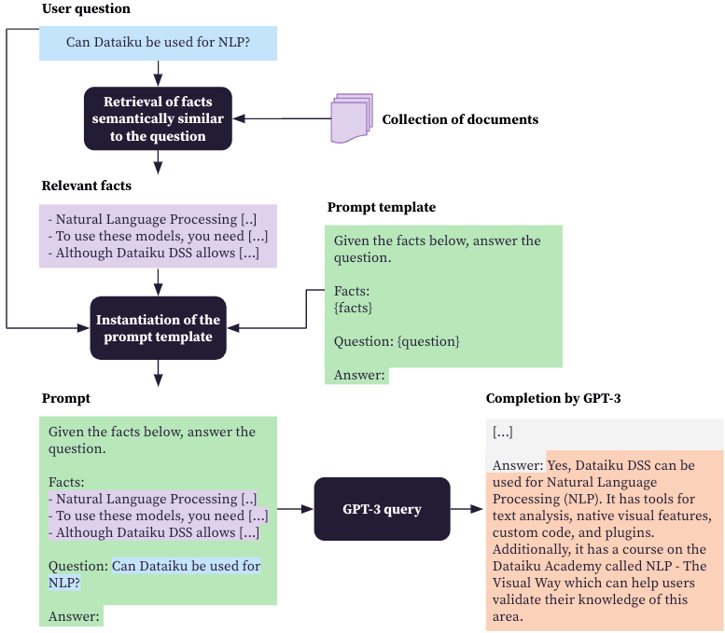 Retrieve-then-read pipeline
Retrieve-then-read pipeline
In this way, we hopefully provide relevant facts for the language model to prepare an accurate answer. Of course, this relies on our ability to extract the proper passages from the collection of documents. In a nutshell, this semantic search can be done in the following way.
As pre-processing steps, once and for all until the documents are updated:
- Extract the raw text from the documents;
- Divide the raw text in small chunks (typically the size of one or several paragraphs; this is needed to not include irrelevant information and stay within the prompt size limit);
- Compute the embeddings of each chunk either with a semantic similarity pre-trained model or a bag of words retrieval function like BM25;
- Optionally, index these embeddings to enable fast similarity search.
Then, for each question:
- Compute the embedding of the question;
- Find the K chunks whose embeddings are most similar to this embedding.
Please read our previous blog post on semantic search for further details.
Finding Answers in Dataiku's Technical Documentation
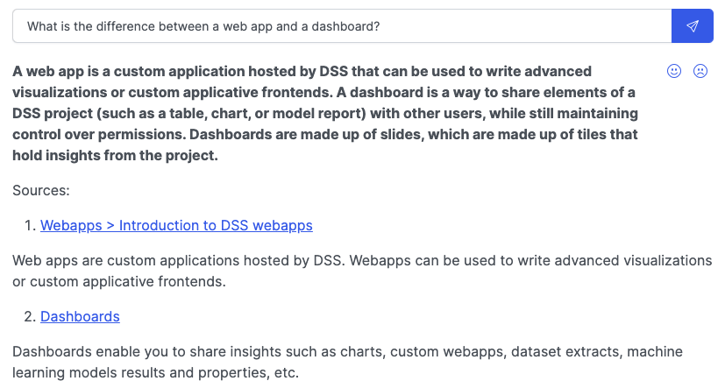 Screenshot of the prototype's user interface
Screenshot of the prototype's user interface
We can now turn our attention to a concrete example. The documentation available to Dataiku’s users and administrators includes more than 2,000 public web pages. This is a testament to the richness and versatility of Dataiku. More prosaically, this also means that finding a specific answer may be challenging.
As these documents are published on the internet, standard search engines can be taken advantage of. However, they can at best identify relevant web pages but it will still be up to the user to find the precise answer. ChatGPT could alleviate this effort by formulating an answer, but ChatGPT is restricted to an earlier snapshot of the documents which will not be relevant for recent Dataiku versions. This was then a good use case to experiment with a retrieve-then-read pipeline powered by GPT-3. Let’s see how it went in detail:
- Content extraction and formatting: We automatically downloaded and parsed all pages of Dataiku’s technical documentation, knowledge base, and developer’s guide, as well as the descriptions of the Dataiku plugins. We extracted the content in a Markdown format to retain some structure of the HTML pages (e.g., the section and subsection headings or the fact that some parts correspond to code samples or tables).
- Chunking: We first divided the text using the existing sections and subsections of the pages and then we cut each part in chunks of approximately 800 characters maximum. We used some pre-processing and post-processing transformations to make sure that this did not break the Markdown format (in particular for code sections and tables). We systematically added the heading of the current section or subsection in each chunk so that it is more informative and self-contained. We also removed exact duplicates. This is important because the number of extracts to add later to the prompt should be limited to avoid diluting or excluding relevant facts. We ended up with about 17,000 chunks.
- Computing embeddings: We computed the embeddings of the chunks with a pre-trained semantic similarity DistilBERT model. We did not use an indexing technique like FAISS given the limited number of vectors.
- Creating the prompt: We used the straightforward question-answering prompt below, insisting on the fact that the question is asked in the context of the use of Dataiku.
prompt_template = """Use the following extracts of the Dataiku DSS documentation to answer the question at the end. If you don't know the answer, just say that you don't know.
- - - - -
Dataiku DSS documentation:
{context}
- - - - -
Question: I am a Dataiku DSS user. {question}
Answer: """- Querying GPT-3: We leveraged text-davinci-003, which is, according to OpenAI, the “most capable GPT-3 model” and the best option for “applications requiring a lot of understanding of the content, like summarization for a specific audience and creative content generation.”
- Displaying the answer: The answer is presented to the user, along with the corresponding “sources.” These sources are not provided by GPT-3. They are simply the paragraphs of the retrieved passages (cf. step 2 of the retrieve-then-read pipeline) most semantically similar to the answer. Moreover, it’s useful here to enable users to flag useful or useless answers so that this feedback can guide future design choices and help prevent potential regressions.
Even though it is quite simple, this approach already yields satisfying results. For many questions, the answers are accurate, well formulated, and concise. Examples are provided in the table below. The sources provided are also mostly relevant.
 Examples of correct answers
Examples of correct answers
There are some wrong answers. Here are some examples with a potential explanation:
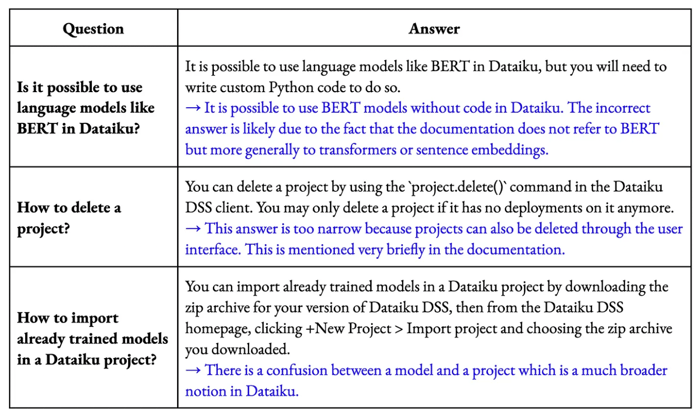 Examples of incorrect answers
Examples of incorrect answers
Potential Improvements
With more real-life use and feedback, it will be possible to better understand the reasons for the inaccurate answers and consider several improvements to this first prototype, for example:
- If the real answers are often nowhere to be found in the current documents, adding new documents is an obvious option. In practice, we should however make sure the new documents are sufficiently accurate, concise, and up-to-date. Given that the length of the prompts is constrained (4,097 tokens for text-davinci-003), we should also avoid having too many duplicates or near duplicates when the new chunks are added.
- If the clues leading to the proper answers are present in the current documents but not included in the prompts, the focus should be on better retrieving the relevant passages. This can be done by fine-tuning a semantic similarity model to our corpus of documents, by combining such a model and a sparse approach like BM25, or by using as an alternative a more accurate but computationally expensive cross-encoder.
- If all clues leading to the proper answers are included in the prompts but GPT-3 somehow fails to interpret them, “prompt engineering” may help. This may entail providing examples of satisfying answers (few-shot learning), encouraging the model to make its reasoning more explicit with techniques such as chain-of-thought, self-ask or demonstrate-search-predict, or generating several answers and selecting the most consistent one (self-consistency).
Conclusion
Building a basic question answering system based on specific collections of documents with decent results is now straightforward with modern language models like GPT-3. This does not require creating a dataset of question/answer pairs: Only the documents themselves are needed.
However, even if the accuracy can be improved through a range of techniques, there will always be risks of misleading or inappropriate answers. Users should be informed of these risks and such a system should be restricted to the situations for which these risks are acceptable.
The Dataiku project to reproduce this prototype described in this blog post is available on Dataiku’s project gallery and can be freely downloaded. Except the initial web scraping part which is specific to Dataiku’s technical documentation, it can largely be reused for your own case, in particular:
- The chunking step;
- The computation of the embeddings for each chunk;
- A web application for end users to ask questions and receive answers;
- A web application to visualize the answers flagged by users as useful or useless.
Besides, you can take advantage of the Natural Language Generation plugin to leverage GPT-3 in the Flow of your Dataiku projects.