




At Dataiku, we’re committed to helping organizations of all sizes and maturity levels deliver on the full potential of Everyday AI. From the beginning, this has always meant having a clear focus on production — and not just design — in order to enable our customers to easily deploy models in the real world. Doing this comes with a lot of challenges and Dataiku's end-to-end AI platform already has many out-of-the-box features to implement best MLOps practices.
In the past year or so, there has been a lot of chatter in the data science community about feature stores and how they can help scale the amount of models in production. If you are not familiar with the concept of a feature store from a definition standpoint, the consensus is that a feature store acts as a central repository of curated features that can be reused for machine learning (ML) model training and inference across projects and teams.

However, through our conversations with many organizations, we realized that there is no one-size-fits-all implementation for feature stores because each organization has specific needs around feature management and consumption. These usually vary with the types of use cases being built, the existing data architecture, tooling, and processing.
Dataiku provides all the building blocks to let you assemble the right feature store for your specific needs.
This article will get you introduced to feature stores, show you how they can be beneficial to your organization, and share how you can implement one using Dataiku. Part two of this series will be a deeper dive on a feature store implementation in Dataiku.
Do You Need to Look at Feature Stores for Your Organization?
There are two main reasons that drive many organizations to look at feature stores:
- To limit duplication of work
- To reduce the risk of training/serving skew
Duplication of work happens when a data scientist develops a feature that was already built by another data scientist for a previous project instead of reusing the existing work. In a credit card company, a feature computing the number of transactions on a card in the previous three months can be beneficial to multiple use cases, such as in both a fraud prediction model and in a customer churn model. Without the proper processes and tooling to provide visibility into the existing models and features, it is very hard to avoid this problem.
Training/serving skew happens when the feature generation code in the serving pipeline behaves differently than in the model training pipeline. These differences in code behavior can lead to different feature distributions in the records to score compared to the records that were used to train the model, which ultimately leads to poor model performance in production.
In some organizations, data scientists write feature generation code to train models in Python and hand it over to engineers that reimplement the code — sometimes in another language like Java or C# — for scoring in production. This reimplementation step is both time consuming and error prone. A small difference in code logic can change model input values and impact the model performance in production.This is another example of duplication of work between the data scientist and engineer, which can also curb the ability to run quick iteration cycles on the models.
How Dataiku and a Feature Store Can Help Solve These Challenges
At a basic level, there are three critical sets of capabilities that allow feature stores to solve these challenges. These are often referred to as the foundational layers of feature stores:
- A compute and storage layer to populate the feature store with feature values in an intuitive way and logically organize them in feature groups stored in feature tables
- A feature serving layer to look-up and ingest feature values from the feature store into both offline model training and scoring pipelines and online model scoring APIs
- A metadata and cataloging layer to ensure that the features previously built can easily be documented, searched, and reused
Dataiku is a central workbench to let teams of users from business analysts to data scientists (and everything in between) design, deploy, and reuse data pipelines and ML models in a collaborative way. Dataiku’s core features around collaboration, reusability, and flexibility make it the ideal platform to support a future-proof feature store architecture that benefits the entire organization.
To build and store features, the Dataiku Flow allows teams to collaborate on feature generation pipelines by combining a broad set of code languages (Python, R, SQL, etc.) with handy point-and-click recipes to expedite the data preparation and wrangling steps usually required to build feature tables. These pipelines can leverage a variety of natively supported compute (Spark over Dataiku managed elastic AI clusters, SQL engine, in-memory etc.) and storage (cloud object storage, SQL/NoSQL, HDFS, etc.) options to build and persist feature values in an online and offline feature store (which we explain in the next section).
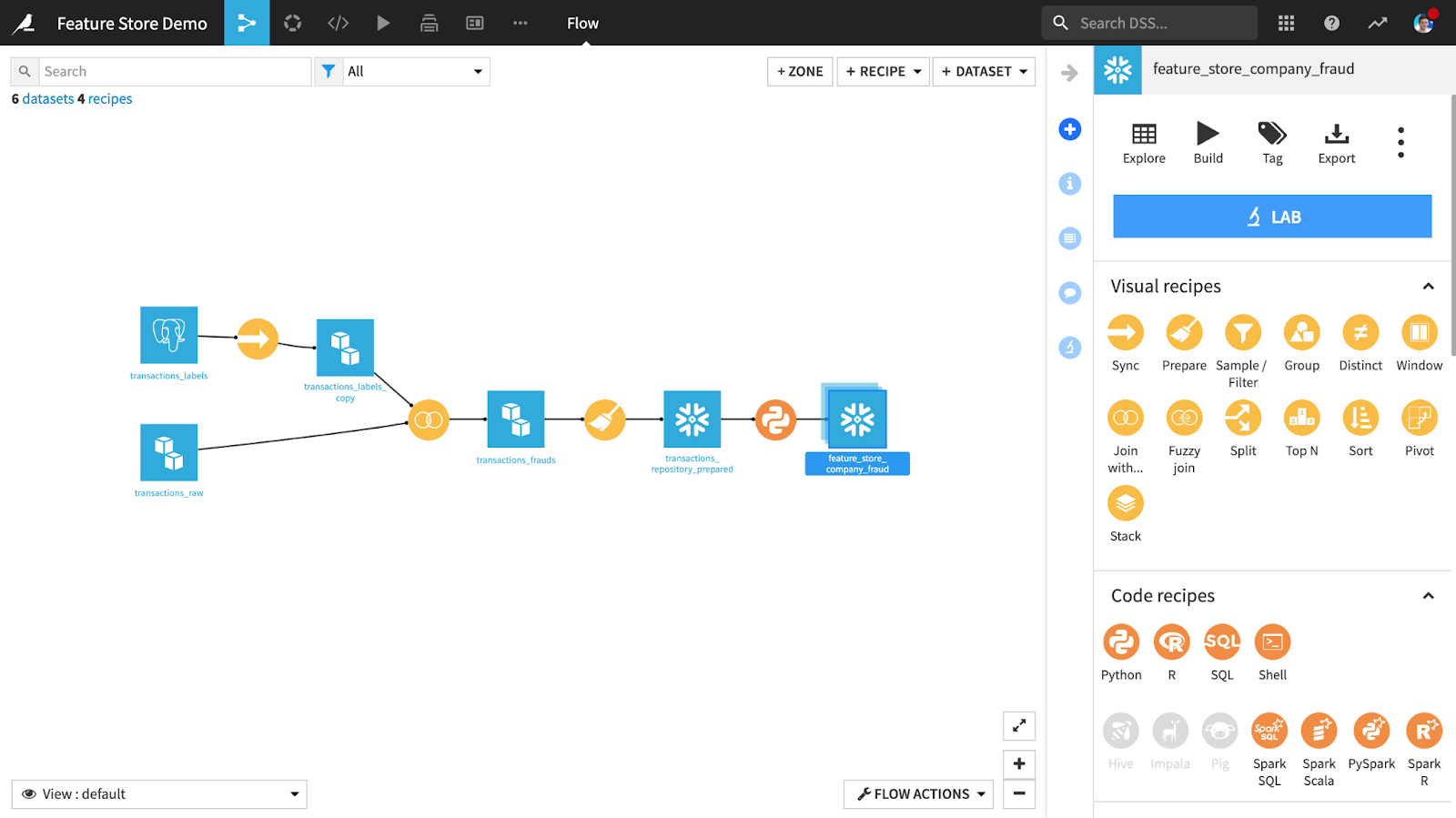
Designing feature generation pipelines in the Dataiku Flow
Dataiku is an integrated platform that covers the full model lifecycle, from development to deployment of productionalized batch scoring pipelines and real-time scoring APIs. Feature retrieval from the feature store and feature serving is natively supported for both batch use cases (offline) and real-time serving (online). In the offline case, the Join recipe allows you to enrich a reference dataset with a batch of precomputed feature values. For online serving, real-time query enrichment from a feature table can be set up inside your model API directly from the Dataiku UI.
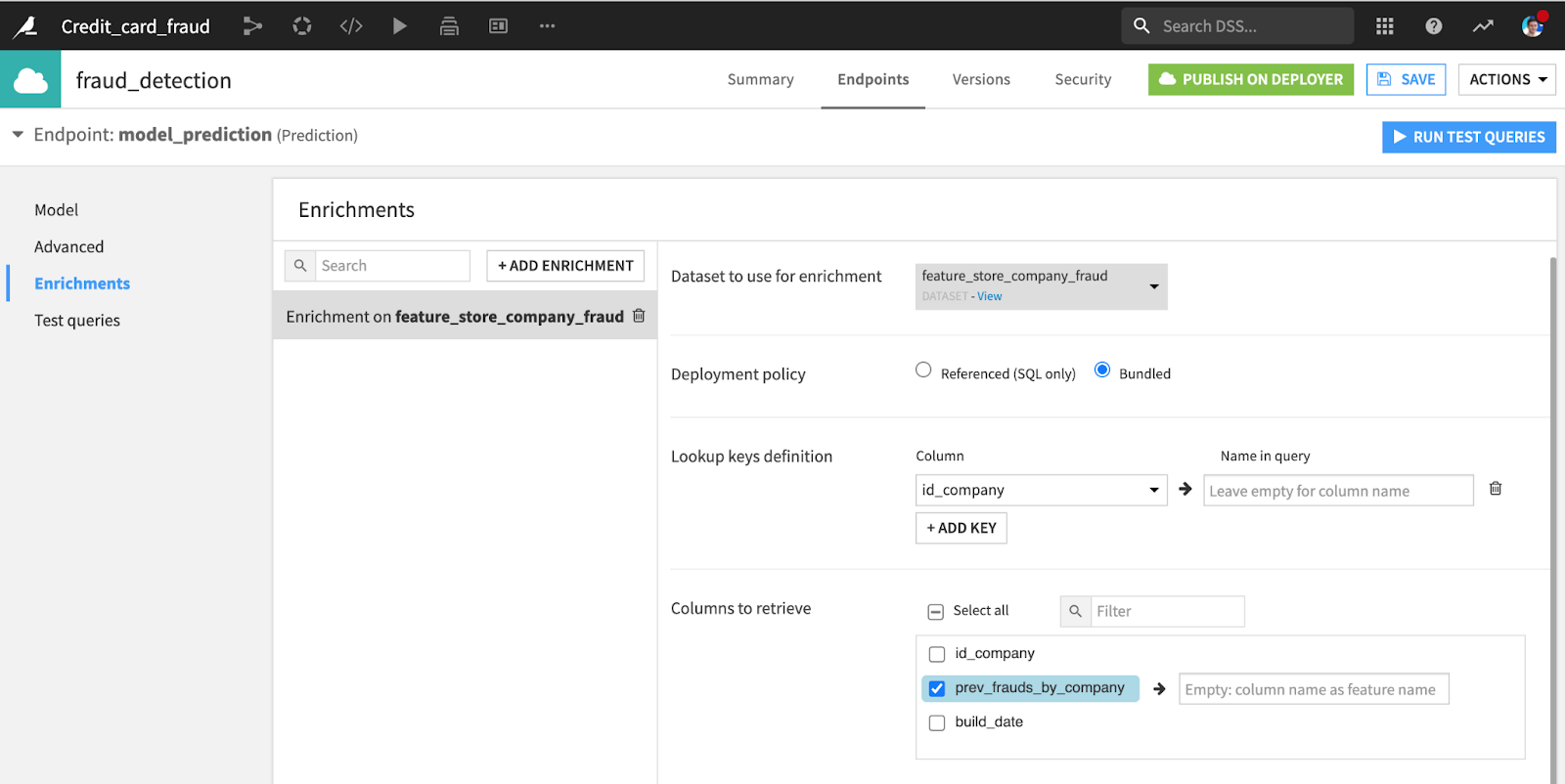
Setting up enrichment from the feature store for a model API
Discoverability and reusability is at the heart of Dataiku’s core value proposition. Every asset — including feature tables — built within Dataiku is automatically assigned extensive metadata. This includes lineage information retrieved from the Flow as well as asset history and versions from Dataiku’s native Git integration. On top of this automatically generated metadata, user-defined tags and descriptions can be added to feature tables and columns in order to build a shared understanding of the available feature groups and make them discoverable.
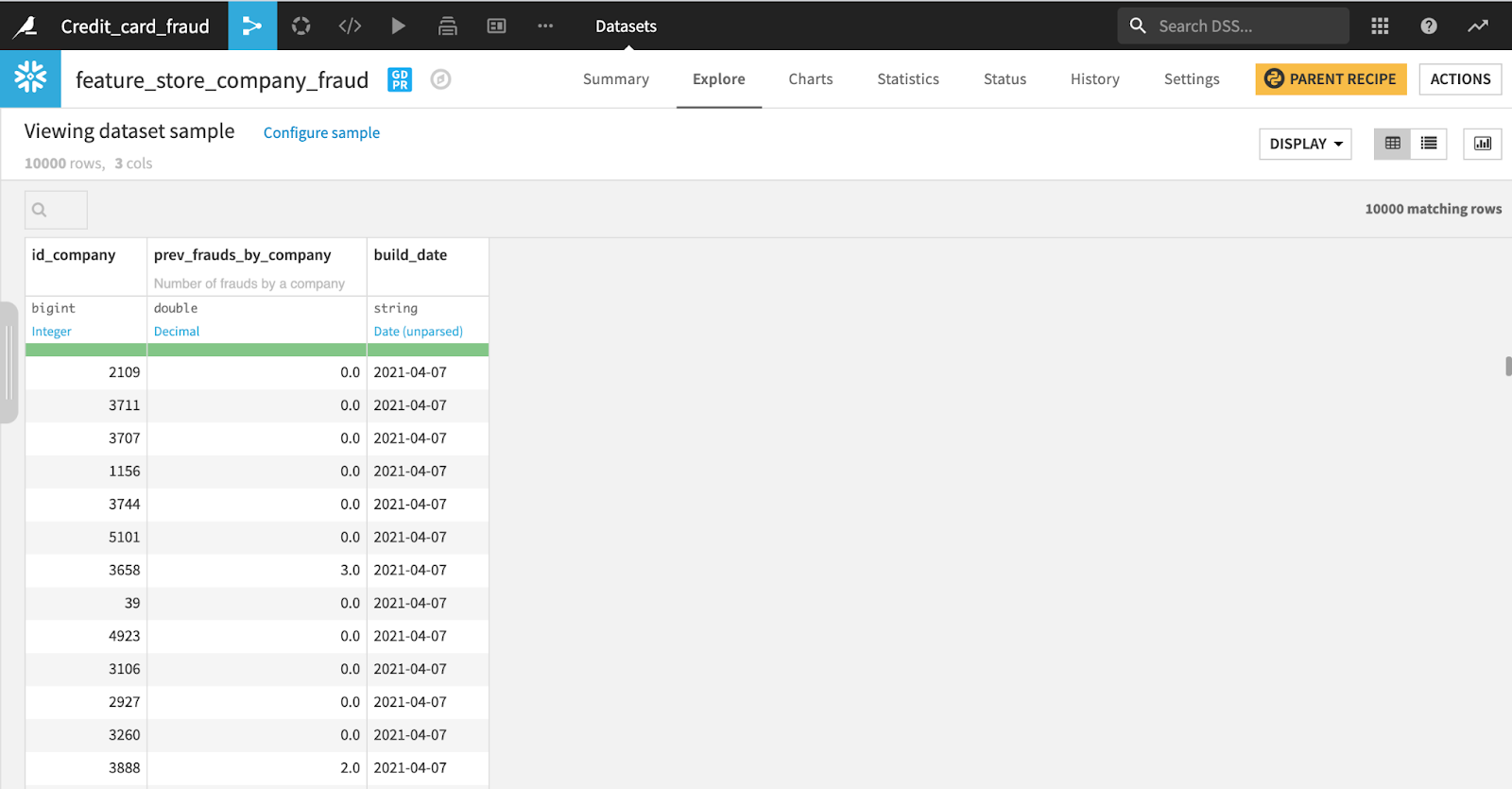
Documenting features using feature table column descriptions
Users can discover features from the feature store through Dataiku’s built-in catalog. The catalog allows anyone in the organization to easily search, discover, and import feature tables in new projects.
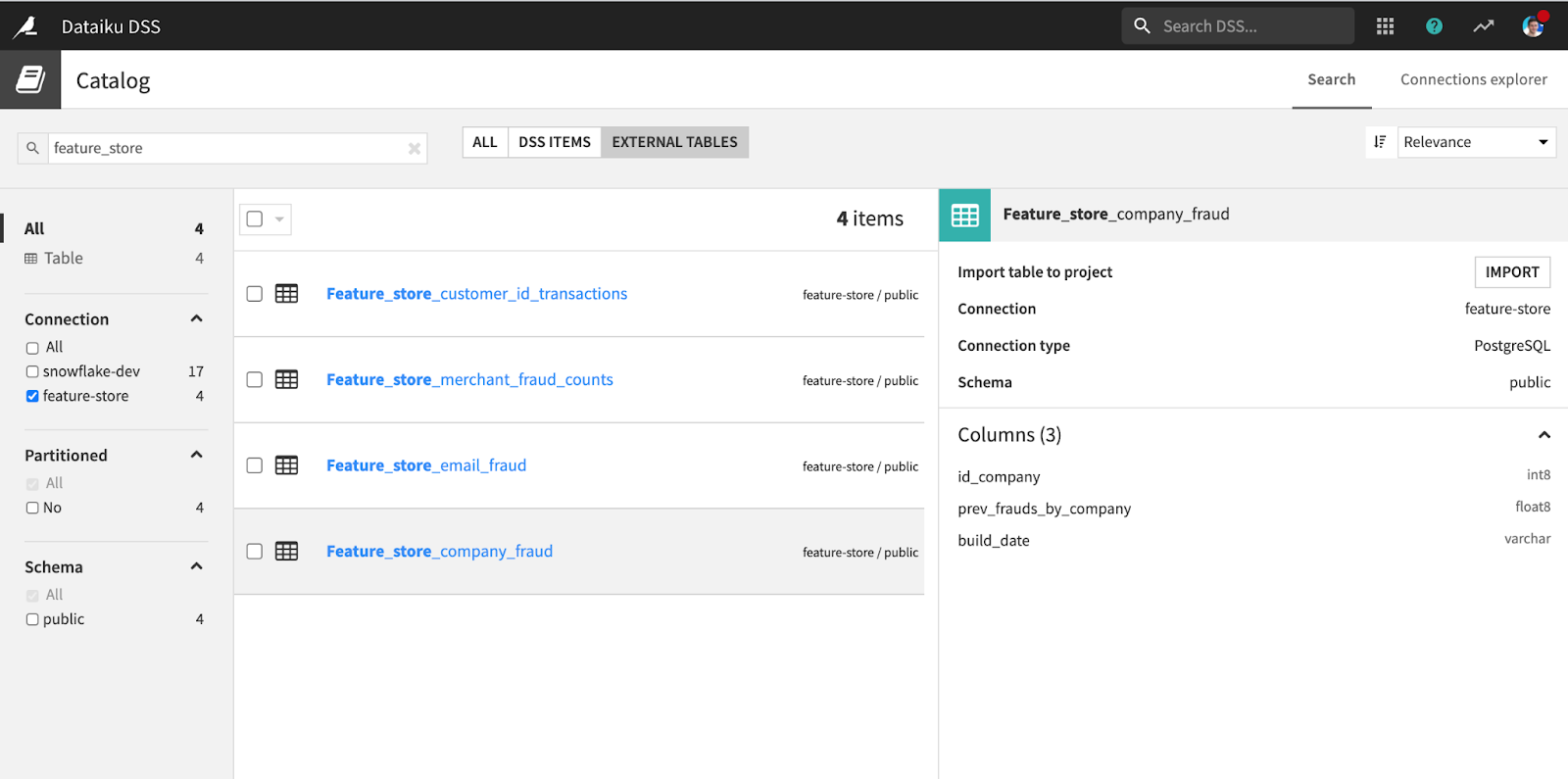
{kind=link}
Exploring existing features from the feature store
Now that you have a better idea of how Dataiku and a feature store can help your organization, in part two of this series, we will dive even deeper into the nitty gritty of a feature store implementation using Dataiku to get you started on your feature store journey.