




{kind=link}
Ever heard of Doorstep Dispensaree Ltd? Probably not. But in December 2019, they became the first-ever company in the UK to be fined for failing to comply with the European Union’s General Data Protection Regulation (GDPR).  The doorstep pharmacy business stored a range of documents containing names of patients, NHS numbers, addresses, dates of birth, and — of course — sensitive medical information in some unsecured and unlocked containers.
The doorstep pharmacy business stored a range of documents containing names of patients, NHS numbers, addresses, dates of birth, and — of course — sensitive medical information in some unsecured and unlocked containers.
Yes, containers - and no, nothing to do with Docker, Kubernetes, or some fancy computation in the cloud, although some of the data was found "soaking wet.” The report of the investigation adds that some of the files "were stored in disposal bags and a card box [...] not secured or marked as confidential."
It’s difficult to disagree with Steve Eckersley, Director of Investigations at the ICO, when he declared that “Doorstep Dispensaree stored special category data in a careless way and failed to protect it from accidental damage or loss. This falls short of what the law expects and it falls short of what people expect.”
Whether they are the product of human negligence or the result of complex hacking techniques, data breaches often end up with record fines (as was the case for Marriott last year) — GDPR allows for penalty up to 4% of the annual revenue. And companies are, ultimately, having to pay up; Uber had to fork over a staggering $148 million in a lawsuit for a data breach in 2016 that they tried to cover up, and Yahoo paid $84 million to compensate users from a hack that affected 500 million email addresses in 2014.
Compliance and Capitalization
With the increased level of scrutiny from regulators, organizations find themselves in a delicate situation. The competition to acquire and retain clients is so fierce that putting compliant data and robust technology in the hands of data scientists is now the de facto standard to secure market shares while yielding to the law.
On one hand, organizations now have to invest significant time and effort to secure their data and comply with the law to avoid astronomical financial punishments (not to mention the cost of reputational damage). However, on the other hand, companies also have to race to make the most of these treasures of information, using machine learning to create the best, most innovative products in line with the new customer habits.
To stay relevant to the market, companies have forked over some serious cash not only to attract top data scientists, but also to get access to some fresh datasets from third parties (or by collecting the data themselves).
The Technological Paradigm Shift
This race to gain a competitive advantage is also driven by a new paradigm shift in technology. Elastic computing offers a quicker — and in most cases a cheaper — alternative for organizations willing to process significant volumes of data at scale. The cloud is slowly overtaking on-premise infrastructures, and McKinsey predicts this decade will see the rise of hybrid architectures mixing on-premise and multi-cloud deployments.
Indeed, a study conducted by Dataiku of 200 IT leaders confirms this trend, as 64% of respondents said the data they use for machine learning projects is stored in a hybrid cloud/on-premise setup (read the full results of the survey Trends in Enterprise Data Architecture and Model Deployment).
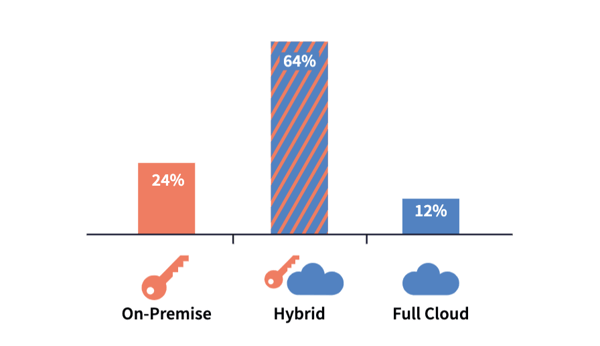 The results of a survey of 200 IT leaders when asked where the data being used for machine learning projects is stored (source)
The results of a survey of 200 IT leaders when asked where the data being used for machine learning projects is stored (source)
However, this context has significantly increased the load on IT departments, which very often struggle to keep up. That load can even be felt in digital-native organizations that often need to prove even more to the regulators that they meet the standard requirement to have access to an industry license or accreditation.
CIOs now have to come up with some long-term initiatives to encrypt or anonymize the strategic parts of the data lake, ensuring the business is protected from bad actors and won't fall short of the expectations of the law. This adds up to the critical transition plans to evolve a full-fledged on-premise infrastructure toward a hybrid strategy where part of the storage and compute is now offloaded in the cloud.
Last but not least, they are still in charge of operationalizing thousands of data products created by the analytics teams across the organization, as new frameworks make it easier than ever to try advanced statistical techniques and develop machine learning models.
The Resulting Paradox
This situation creates a unique paradox. IT departments are unfairly perceived as the bottleneck to innovation, but they have — in reality — been busy thinking about how to bring the best technology to subject matter experts and centers of excellence while simultaneously taking care of business applications running in production.
It is out of those special circumstances that the self-service trend has emerged. Removing some of the burdens on IT departments became a strategic direction, and the rise of visualization, BI, and data preparation tools empowered thousands of employees on the path to analytics; but that self-service trend has yet to touch data protection.
The strategic deliberations around how to protect the data assets of the organization are often long and tedious as the regulation itself evolves to better serve the citizens, and very rarely do we observe these plans following a smooth path and seamless execution.
That often causes some significant delays as the analytics teams wait for the approval and validation from the compliance department to get access to their data and start working on some of the juiciest use cases, the ones that will surely transform the way the organization serves its customers.
The Solution
What if a compliance team could mask the data needed for a specific use case without having to go through cumbersome processes and, once done, make them available to the analytics team? At Dataiku, we aim to harmonize the processes inside organizations by providing a self-service approach for the use of data, analytics, and technology while at the same time encouraging better corporate governance.
We believe that the analytics teams across organizations should be able to work on the most lucrative use cases without any delay while at the same time, strategic decisions are being made at the top to come up with the best approach to comply with regulatory expectations.
We are proud to announce a partnership with Protegrity, known for its expertise in data protection. With this integration, Dataiku helps make self-service data protection a reality. Users with granted access can now protect the data required for an analytical use case, whether it involves some simple data preparation for visualization purposes or working with heavy datasets containing a lot of personally identifiable information (PII) waiting to be fed to the most cutting-edge machine learning algorithms.
![]()
We understand that the teams in charge of validating data compliance are not always coding or cryptography experts. Thus, the self-service nature of the Dataiku offering allows them to use a point-and-click interface to secure data, while Dataiku works in the background to leverage the Protegrity tokenization API.
Self Service Data Protection Is Only the Beginning
As an abstraction layer on top of desired cloud infrastructure, why not make the most of newly tokenized data by leveraging Snowflake elastic computation? Using the Protegrity API, Dataiku allows the tokenization of data from any source it is connected to and can directly store them in a Snowflake environment. The analytics team will now be able to help the business make data-driven decisions, at scale — a critical step on their path toward Enterprise AI.