




{kind=link}
Given a text corpus, semantic search consists of retrieving texts whose meaning matches a search query. For example, if your search query is “car,” the retrieved texts could include words such as “car,” “automobile,” “vehicle,” and so on. In contrast, keyword search only returns text passages with words of the search query. In the previous example, you would only get text passages including the word “car.”
Over the last few years, semantic search has become more reliable and straightforward. It is now a powerful Natural Language Processing (NLP) tool useful for a wide range of real-life use cases, in particular when no labeled data is available.
In this blog post, I will:
- Broadly explain how semantic search can be implemented;
- Provide examples of use cases in a corporate setting;
- Explain some practical challenges and their potential solutions;
- Present a Dataiku example project that can be easily reused for your own semantic search use case.
Identifying Semantically Similar Texts
The most common approach for semantic search is to use a text encoder pre-trained on a textual similarity task. Such a text encoder maps paragraphs to embeddings (or vector representations) so that the embeddings of semantically similar paragraphs are close.
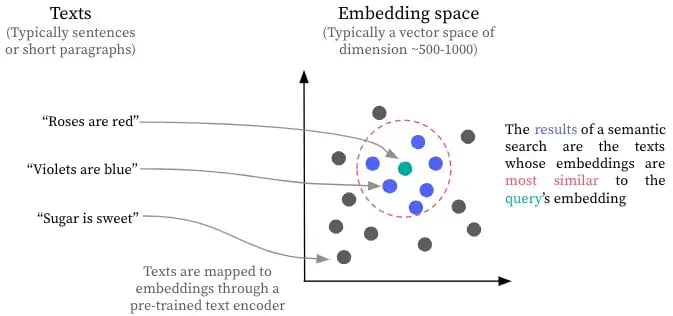
With the text encoder, we can compute once and for all the embeddings for each document of a text corpus. We can then perform a search by computing the embedding of a natural language query and looking for its closest vectors. The corresponding documents are the search results. We can also use one of the documents of the corpus as the query. In this case, the results of the semantic search should be the documents most similar to this query document.
Powerful text encoders pre-trained on semantic similarity tasks are freely available for many languages. Semantic search can then be implemented on a raw text corpus, without any labeling efforts. In that regard, semantic search is more directly accessible and flexible than text classification.
In fact, use cases involving text classification can be reframed to take advantage of semantic search instead of or in complement to text classification:
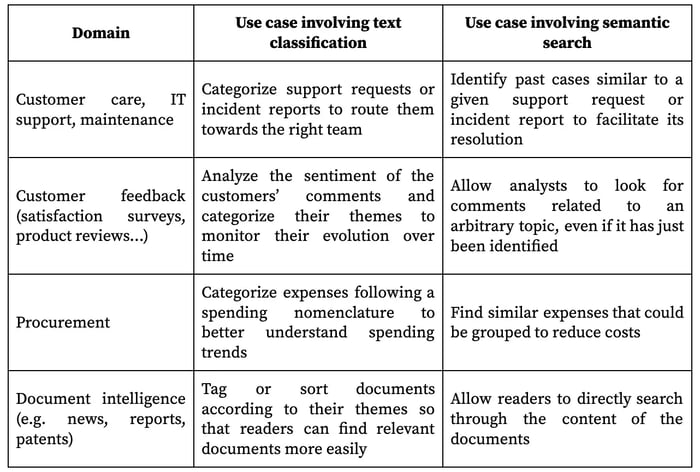
Semantic search can also be useful for a pure text classification use case. For example, it can be used for the initial exploration of the dataset to help define the categories or assign labels.
Even if the core ideas described above are straightforward, practical obstacles can hamper a semantic search use case. In particular:
- Processing Long Documents: Text encoders relevant for semantic similarity were pre-trained on texts as short as a sentence or a small paragraph. They are then not directly relevant for long documents (from several paragraphs to several pages). A first solution is to split long documents into short paragraphs. The semantic similarity is then computed at the level of these paragraphs and the results are aggregated per document. A second solution is to truncate the texts. This makes sense if a sufficiently representative section of the text (e.g., an abstract or a conclusion) can easily be identified.
- Taking Into Account Domain-Specific Vocabulary: The public pre-trained models were typically trained on general training sets (e.g., news headlines, image or video captions, etc.). As a result, they aren’t directly relevant for texts with a very specific vocabulary (jargon, slang, acronyms, etc.). Several techniques such as Augmented SBert, Unsupervised Text Embedding Learning, Adaptive Pre-training or Generative Pseudo-Labeling can be used to adapt a model to a specific text corpus. However, their data or computing requirements may be hard to satisfy. An imperfect but simple alternative is to combine the semantic search with a keyword search (potentially enriched with a list of synonyms). In this way, queries with very specific terms such as uncommon product names or acronyms may lead to adequate results.
- Handling Large Collections of Documents: Naively comparing the query embedding with the embeddings of all the documents of the corpus is not scalable. For large collections of documents, efficient vector indexing techniques such as Faiss should be used. Another option, in particular if more advanced search features are required, is to use search engine solutions, such as Elasticsearch, that can natively handle dense vectors.
- Improving Accuracy: In the context of semantic search, the model used to transform some text into an embedding is called a bi-encoder. Using a bi-encoder is fast because the embeddings of the documents in the corpus can be computed once and for all and the similarity score can be obtained with a simple dot-product. More accurate results can be obtained with a cross-encoder, at the cost of a higher latency. A cross-encoder is a deep learning model computing the similarity score of an input pair of sentences. If we imagine that embeddings have already been computed for the whole corpus, we can call a bi-encoder once to get the embedding of the query and, with it, a list of N candidate matches. Then, we can call the cross-encoder N times, once for each pair of the query and one of the candidate matches, to get more reliable similarity scores and re-rank these N candidate matches.
Leveraging Semantic Search in Dataiku
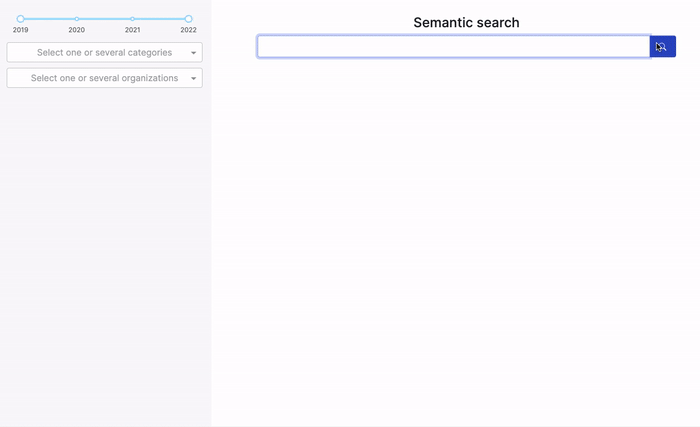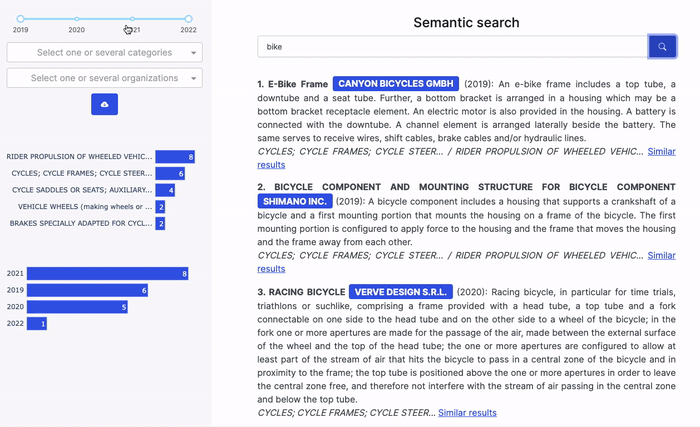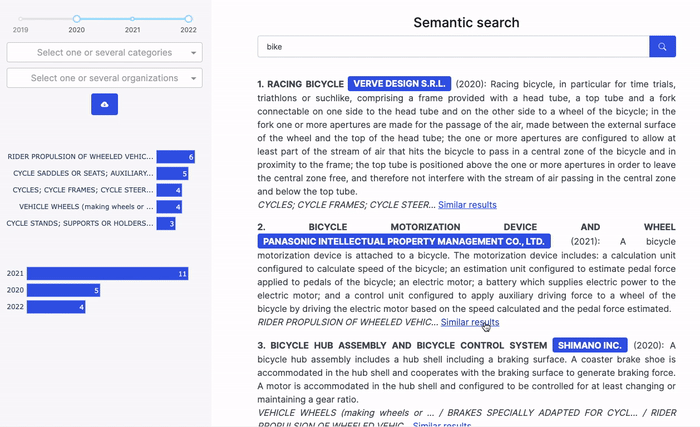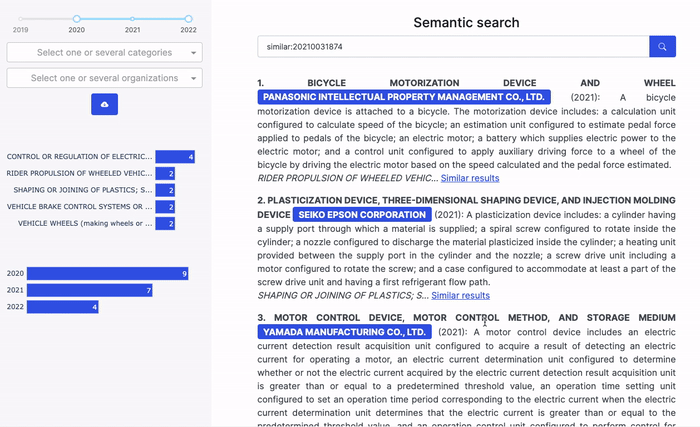
But if you are a Dataiku user, you could get started in no time with this example project. It aims to help you create a semantic search user interface for your own set of documents. This user interface includes features that enable you to:
- Find documents based on a text query, combining semantic search and keyword search;
- Find documents similar to a given document;
- Filter the retrieved documents on these documents’ metadata (e.g., year);
- Display charts summarizing some metadata (e.g., year) of the retrieved documents.
Moreover, the example project also illustrates how to leverage Faiss and Elasticsearch.
Semantic search is an essential capability in the NLP toolbox. It can be used for a broad range of use cases, in isolation or in conjunction with text classification. It particularly shines when labeled data is difficult to obtain.
If you use Dataiku, the attached example project significantly lowers the barrier to experiment with semantic search on your own use case, so leveraging semantic search is definitely worth considering for all of your NLP projects.