




{kind=link}
In this article, we will go over some of the basic concepts of streaming in the context of a machine learning (ML) project and how you can use Dataiku to ingest or process streaming data.
Ideally, you should be familiar with Dataiku: you have already built a flow and use various Dataiku artifacts such as recipes and models — the Dataiku Academy Quick-Start Programs for Data Scientists or Data Engineers are good starting points. You'll also need knowledge of Python and/or Scala if you want to leverage streaming in coding recipes.

Introduction
Data sources you use on a regular basis (be them files, SQL, no-SQL, or data lakes) are all static, meaning data is stored for a long time and can be fetched, filtered, and processed the way you want. Streaming takes another approach — the data is not static but flowing constantly and materialized in the form of events. Interactions are organized between producers that will generate those events (like a temperature sensor or a market data system) and consumers that are fetching these events.
Tapping into this vast amount of data is more and more important for data science teams, and Dataiku offers native integration with streaming systems to leverage them in your projects. This feature comes in different flavors, from visual to code, and we will see in this article what the specific streaming artifacts are and how you can use them.
Some Typical Use Cases
There are lots of streaming use cases nowadays, sometimes as a new approach and sometimes as an evolution from existing batch logic. Some examples include:
- Activity tracking: This is the original use case for Apache Kafka at LinkedIn. The goal is to suggest user-specific pages, articles, or promotions to a website. In order to do that, you need to know the user activity as it is happening and push it to an algorithm that will decide which actions to trigger. Streaming is the technical backbone used to share.
- Sensor data processing: In the manufacturing industry specifically (but not exclusively), detecting faulty parts or machine incidents is key. Using sensors, manufacturers can aggregate a lot of data that needs to be analyzed and may generate alerts. A concrete example is analyzing pictures of electronic circuits to detect bad soldering, and another is to detect if a line needs to undergo planned maintenance in advance rather than waiting for it to break during peak activity. Here also, streaming is key to ensure the alarm is raised as soon as possible.
- Messaging: This use case is the inheritance of the Enterprise Service Bus logic. The streaming system is used as a format-agnostic system to pass messages between applications.
If you are interested in one of these use cases or if you have an internal streaming data source, let’s see what you can do with Dataiku to answer these business needs. But first ...
Real Time or Not Real Time?
We often want to use what’s shiny and new, even if we don’t really need it — this is often the case for streaming. If you ask your business users whether they want their insights in real time or delayed five minutes, there is a 99% chance they will say they want the former. However, doing low-latency data processing is complex, and the lower you want the latency to be, the more complex it is to implement.
Also, the skills needed to conceive and operate a real-time system are not common, so you need to carefully assess whether you have them and run some experiments before committing to deploying a low-latency streaming project. Another difficulty is that real time is a very vague word that has wildly different meanings from one industry to another, and even from one person to another. Always think critically about requests for real-time flows and ensure that only the projects that really need to be real time are addressed using streaming so that you can keep time and skills for other (perhaps higher-priority) projects.
Should you want more insights on this subject, you can read this interesting blog post: Apache Kafka is NOT Hard Real Time BUT Used Everywhere in Automotive and Industrial IoT.
Dataiku offers alternatives to using streaming processing if need be:
- Deploying your ML model on a Dataiku API node and call this endpoint directly from your streaming flow (using Kafka Streams, for example).
- You build and train your ML Model in Dataiku and export it. This exported model can then be used anywhere.
- If the data you need can be some minutes old, you may consider storing the streaming data in a static system and then running a batch process every X minutes using scenarios.
How Does Streaming Work in Dataiku?
Streaming capabilities need to be switched on from the Administration section of the Dataiku instance. Once activated, the new streaming features are integrated within project flows with new objects called Streaming Endpoints and Continuous Recipes.
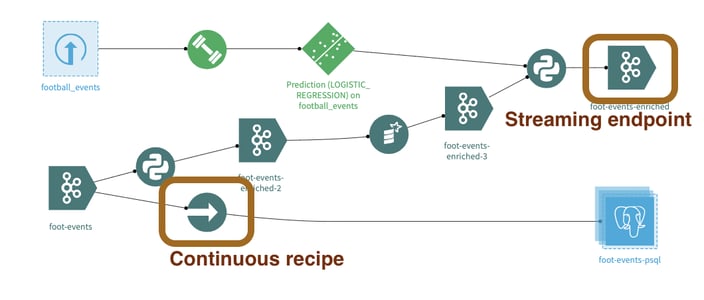
Figure 1: Streaming Endpoint and Continuous Recipes in the Dataiku Flow.
A streaming endpoint is based on a connection, which defines how to connect to the streaming server (in Kafka for example, it is the host:port of the Kafka broker). The streaming endpoint is the topic or queue where you will fetch or push messages. We support connecting to Apache Kafka clusters (all flavors: vanilla, Confluent, AWS MKS, etc.) and Amazon SQS.
We’ve introduced Continuous Recipes (a new type of Dataiku Recipe) to process streaming data. Contrary to existing Recipes, they do not run as part of a batch process but run indefinitely once they have been started.
The following Continuous Recipes are available:
- Streaming Sync: Push events to static dataset or a streaming endpoint (no transformation).
- Streaming Python: Process events using Python code.
- Streaming Spark: Same as above, but leveraging the Spark Streaming framework using Scala.
- KSQL: Powerful Kafka-specific stream processing leveraging a SQL-like syntax
As a way to facilitate discovery, streaming data can also be used in a notebook.
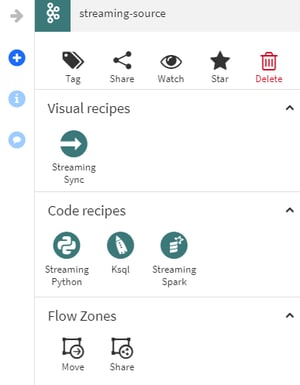
Figure 2: Code and visual Recipes in Dataiku for streaming.
A Journey Through Streaming Features in Dataiku
Exploration & Discovery
Streaming backbones within a company are usually shared amongst many systems, meaning they are processing vastly different types of data (not even homogeneous within a single topic). So your first move might be to explore the streams and see what kind of data is in there and in what volumes to start devising a strategy to use it.
Once you have your connection up and running in Dataiku, you can create a streaming endpoint and use the sampling button. This will simply listen to the stream and show you the first 10 events received.
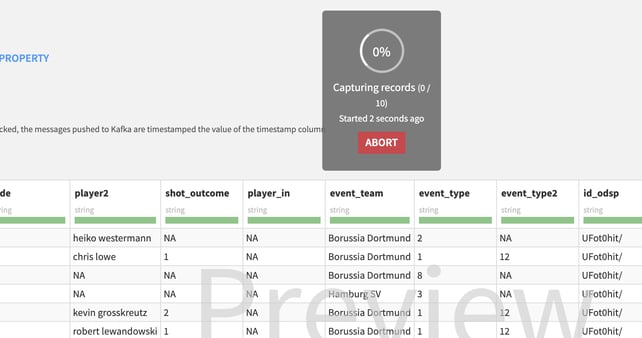
Figure 3: Listening to the stream in Dataiku — first 10 events received.
Once you have some data that seems familiar, the place you can go to experiment are notebooks. With a few lines of code, you can start analyzing the data.
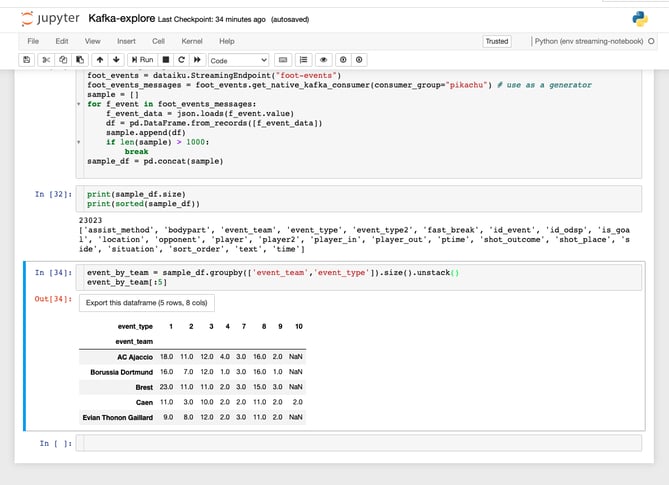
Figure 4: Analyzing streaming data in Dataiku.
The next stage is to experiment with the processing of this data, and the natural move here is from a notebook to Streaming Python. To do so, create a Streaming Python Recipe from your streaming endpoint, add your code (you can of course reuse most of what you have done in the notebook), and start your recipe to see it in action.
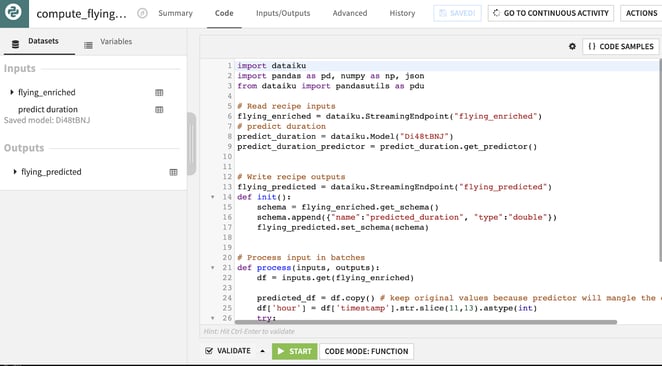
Figure 5: Processing streaming data with a Streaming Python Recipe in Dataiku.
The Bread-and-Butter Use Case: Tapping Streaming Data!
Once you know the data exists and is usable, you’re probably going to be willing to leverage it in your analytics projects. Be it for data processing or model training, leveraging data-at-rest is the best option, so you need to store the streaming data in a static source.
This is commonly done with custom code consuming events and pushing them to a static place (file or database). Although seemingly simple, this can become tricky when you start dealing with the volume of data and the guarantee of delivery (i.e., you do not want to lose a message).
This is where the Streaming Sync Recipe comes into play. It is a visual recipe — so it does not require coding skills — and will allow for easy processing, high throughput, and guaranteed delivery in an easily accessible way.
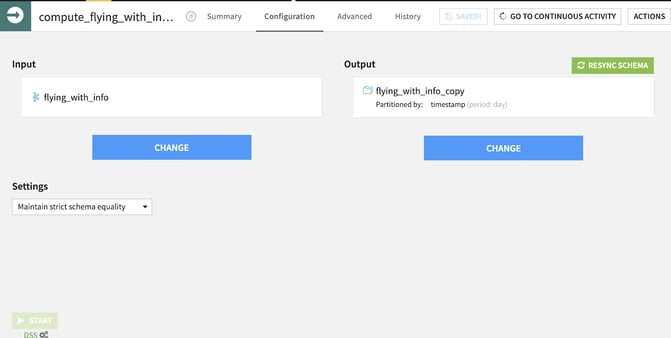
Figure 6: The Streaming Sync Recipe in action in Dataiku.
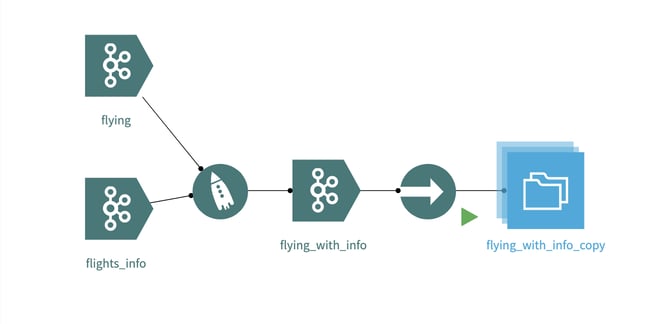
Figure 7: flying_with_info_copy is ready to be used for batch analytics processing.
Advanced Processing
Once all of the above steps are done, you may want to look at more complex use cases. They may be complex because the processing is more complex, because the volume is higher, because you need an exactly once guarantee of delivery, because you want low-latency, etc.
For those types of processing, you can leverage the Streaming Python Recipe, but you might hit some limits, especially in terms of volume and throughput. If this happens, you need to move to the Streaming Spark Recipe, which requires writing Scala and leverages the Spark Streaming framework. This requires good technical knowledge, and we will not deep-dive into it for such an introduction article; however, by knowing Scala and the basis on Spark Streaming, you should be ready to go.
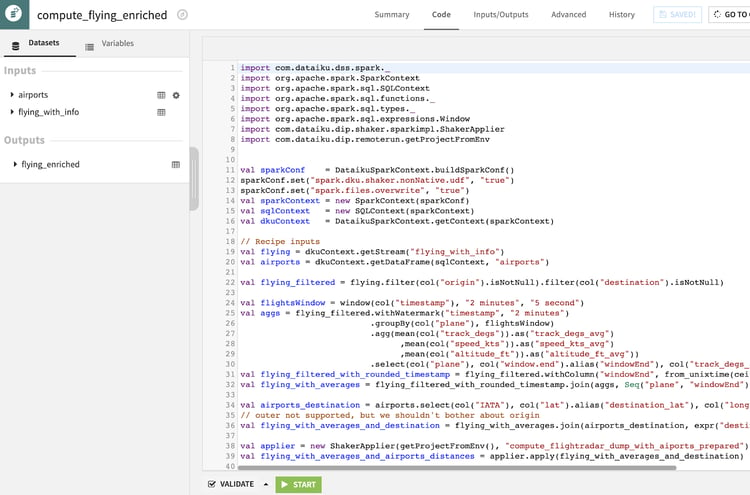
Figure 8: The Streaming Spark Recipe in Dataiku.
Another option if you are using Kafka is to use the Streaming ksql Recipe (Figure 9). This one leverages the ksql language and requires a ksqldb plugged to your Kafka cluster. It allows for some very powerful processing with high performances and a SQL-like language.
A little heads-up here: even though ksql seems familiar due to its SQL look, do not underestimate the learning curve!
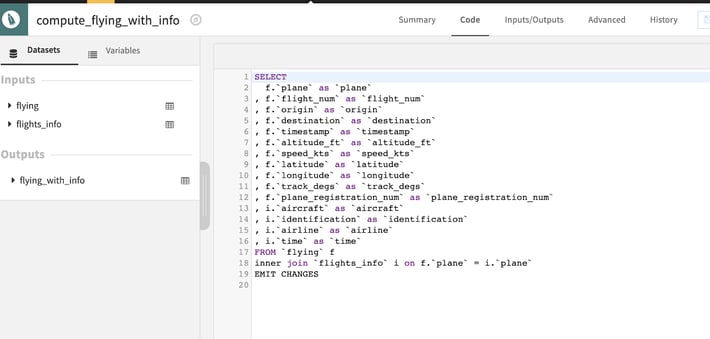
Figure 9: The Streaming ksql Recipe in Dataiku.
What’s Next?
Should you still be interested in streaming (and I hope you are), here are some things you can initiate:
- You need a Kafka cluster at hand with some data.
- Have a Dataiku version 9+ installed.
- Read the documentation, you will find all explanations.
- You can also find coding samples in GitHub.