




{kind=link}
Developing data science workflows can quickly become complex for data scientists and data engineers because of the variety of data sources, processing tools, and the growing number of tasks to be executed. In this blog post, I’ll explain how most data science tools on the market alleviate that complexity, with an emphasis on Dataiku’s unique way of providing a solution to this problem.
What Makes a Data Science Project Complex
Gathering as much relevant data as possible to solve data-driven problems sounds straightforward, but in practice it’s difficult to implement for a number of reasons. First of all, this data is very probably going to be sourced from many different storage platforms, and in order to properly handle it, you need to focus not on where it’s from but more on what’s in it. Consequently, if you can easily “import” datasets from multiple sources and represent them in a unified way to easily manipulate them, you get a clearer vision of your project.
Same goes for data processing tasks: data practitioners have a vast amount of tools they can leverage in their day-to-day job, from SQL queries to more advanced programming languages like Python, Scala, or R. Similarly to data sources, having a unique way of representing tasks regardless of their “backend” is also helpful to get a better view of a project’s structure.
When it comes to representing a project workflow as a sequence of tasks, the most frequent approach is to draw a directed acyclic graph, or DAG. In a DAG, each vertex is a task, and vertices are connected to each other via directed edges to reflect the order in which the tasks should be executed, as shown in Fig.1. This model is used by many orchestrators, the most popular open-source solution being Airflow. However, this approach is limited: since it’s task-driven, it does not include the input, intermediary and output data in its structure, thus offering only a partial view of the project.
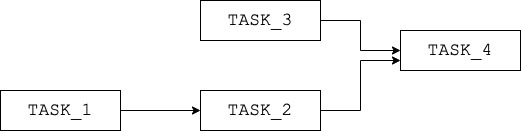
Fig.1: Example of a task-driven DAG: the sequence of operations is illustrated but the underlying data that is generated does not appear.
At Dataiku, providing a comprehensive vision of a data science project was at the heart of our product since the very beginning. In 2013, Dataiku’s CTO Clément Stenac gave a presentation on how we tackle the challenge by offering an alternative vision through a cornerstone feature in Dataiku called the Flow. As of today, the Flow is still a central piece of our product, and to understand how powerful it is, we first need to understand its philosophy and main building blocks.
The Flow: A Data-Centric Approach Inspired by Software Development
At its core, a data science project is all about manipulating and transforming data, so it is important to make it explicitly appear in its structure. To go even further, you could say that running a workflow is not about just executing tasks, but generating all subsequent data outputs of those tasks. In Dataiku, the Flow takes this so-called data-centric approach by representing both data and tasks as Datasets and Recipes respectively in its DAG. What does it mean in practice ?
First of all, let’s take a look at Datasets. Remember the part about abstracting away the storage layer? Datasets are all about it, since they offer the same interface, regardless of where the data lives, should it be in a cloud object storage bucket, in a SQL database, or even on your local filesystem. A Dataset is made of a schema containing the column names and types, and records which contain, well, the data itself.
Recipes contain the logic of the tasks to be executed. They can be seen as functions that take one or more Datasets as inputs, perform tasks on their data, then write the result on one or more output Datasets. Recipes introduce the notion of dependencies between Datasets: to create an output Dataset from a recipe, you need to have the input Dataset(s) already built for the Recipe to run properly. However, those input Datasets are also output Datasets of an upstream Recipe where the same principles apply! In practice, building a Dataset requires solving the dependencies of that Dataset, i.e., identifying all upstream Datasets that need to be built beforehand. The example in Fig.2 showcases how a Flow representation can help define such dependencies.
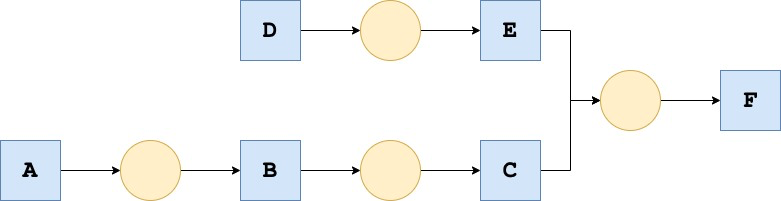
Fig.2: Example of Flow with Datasets as blue squares and Recipes as yellow circles. To illustrate dependencies, building C will potentially require building B, which itself may require building A. Furthermore, building F will lead to concurrent builds of E and C since they are on independent “branches."
The ability of a Flow to resolve dependencies and perform smart efficient builds directly takes inspiration from software engineering tooling. When developers craft software, they need to create build pipelines to transform their source code into deliverables, like executable binaries or libraries.
Historically, they first had to write their own scripts and fully describe the build logic inside of them, but at some point it became so complex that specific tools to handle dependency management were created. The most famous one — called Make — is still widely used today. Other modern build tools like Gradle or Bazel offer several additional high-level features, especially around "smart" dependency analysis. Those features remove the hassle of explicitly listing all required dependencies and will optimize builds, for example by running parts of them concurrently when possible.
The focus of software development is to build a program, and developers care about the final output of their code, not the intermediary build steps that led to it. That is why they don't list the tasks to build their software; instead, they define the target to build, and the system takes care of executing the appropriate tasks.
Dataiku developers understood that these patterns would also make a great fit in handling data pipelines, so they decided to implement the same data-driven and optimized dependency management pattern into the Flow. By doing so, they provided every Dataiku user with the same abilities as software engineers to handle complex projects, but with Datasets and Recipes instead of source code.
Supercharging the Flow With Additional Features
The Flow is meant to be much more than a DAG: it is the focal point of a data project, the starting place for all users who design and consume it. Here are just a small subset of the additional capabilities of a Flow:
- To foster collaboration between users, every element of the Flow can be tagged and enriched with metadata to facilitate their discovery, either directly in the DAG or by using the Catalogue feature of Dataiku. Larger Flows can also be visually split into zones to make navigation within a project easier.
- Machine learning (ML) models are treated as first-class citizens in a Flow: training them is similar to building a Dataset. They can then be used for ML-specific operations, such as scoring. In the next major release of Dataiku, a new Flow item will make its appearance to historize and compare model performances for efficient MLOps implementations, more on that soon!
- For advanced users who prefer coding, the Dataiku public API covers every available Flow item, including the Flow itself! In practice, it means that you can programmatically create and edit Flow items such as Recipes or Datasets as well as manipulate and traverse the Flow as if it was a graph data structure.
Wrapping Up
This blog post has provided an overview of how Dataiku solves the problem of structuring complex data science projects with the Flow. It also hinted at many more interesting adjacent topics! If you are curious about practical applications, you can read about the Flow we implemented at Dataiku to measure and improve CRM data quality