




{kind=link}
Data projects are generally organized in one of two ways: top-down (that is, starting with the business question) or bottom-up (starting with the data and working up to insights). But is there a right way, and is one approach better or more effective than the other?

Let's take a look at these approaches one at a time from the perspective of a financial institution that offers lines of personal credit.
Top-Down Method
In this approach, you might start with an initial belief that fraudulent transactions are a serious problem for your company. To test this hypothesis, you'll need some data, so you choose some representative customer profiles and carefully follow their transactions to be certain which are fraudulent and which are not.

After collecting sufficient transactional data and enriching it with third-party data (such as information about the locations where transactions were made, the weather at the time the transactions were made, holidays, and so on), you can:
- Estimate the cost of fraud among these cohorts and then extrapolate to your entire business.
- Build a model for predicting whether a transaction is fraudulent, and deploy the model to flag suspicious transactions for immediate investigation.
Bottom-Up Method
In this approach, you might start with all of your transactional data and wonder if there are any interesting relationships in it. After sifting through various groupings, charts, and summary statistics, you hit upon a compelling geo-temporal map that suggests there is a spike in customer purchases after 5 p.m. within 10 miles of the customer's billing address. This is information that retailers would find valuable for marketing purposes.
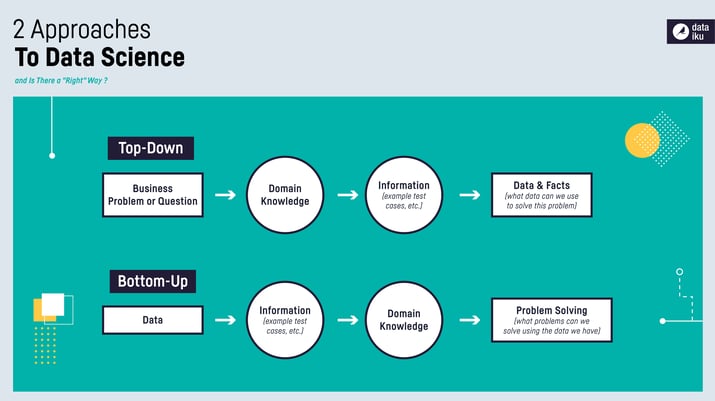
How the Two Approaches Are Different (Yet Complementary)
The bottom-up method to data science tends to be unstructured and exploratory. It lets the data lead to a result, while the top-down method defines a problem to be solved and constructs an experiment to solve it.
In this sense, the top-down approach is better aligned with the scientific method; however, it can also be relatively costly to design and carry out a proper experiment. Moreover, you need to have enough information at the start of the top-down method to set up the data collection so that you don't miss any important features. On the other hand, while the bottom-up method makes good use of the available data, it can also take you on the proverbial fishing trip and you need to take care that you don't chase spurious results.
Ultimately, neither approach is always best. They are often complementary, with one approach leading to the other in a cyclical fashion. For example:
- Top-down to bottom-up. After formulating the initial belief that fraud is a problem for the company, you can use the currently available data to perform a sanity check to gain a ballpark estimate of the scale of the problem and whether the full experiment is necessary.
- Bottom-up to top-down. After the exploratory analysis suggests when and where the increase in customer purchases occurs, you can confirm the finding with a more rigorous top-down analysis.
Both the top-down and bottom-up methods can be even more effective when leveraging a data science tool or platform that has features for easy reproducibility, clear workflows, and insightful visualizations — for more information on how, see Why Teams Need Data Science Tools.