




{kind=link}
This series will go over at a high level what machine learning is plus take a deeper dive into some of the top algorithms and how they work — in plain English!
High Level: What Is Machine Learning?
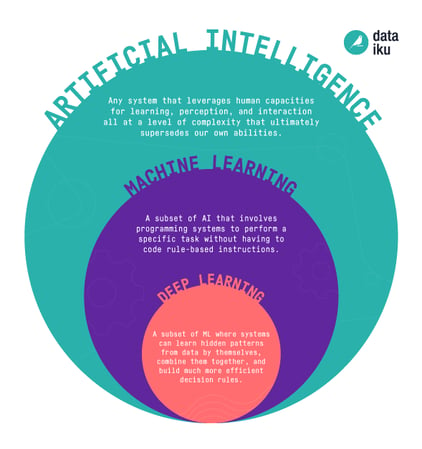
Before we get into machine learning (ML), let’s take a step back and discuss artificial intelligence (AI) more broadly. AI is actually just an umbrella term for any computer program that does something smart that we previously thought only humans could do. This can even include something as simple as a computer program that uses a set of predefined rules to play checkers, although when we talk about AI today, we are usually referring to more advanced applications.

Specifically, we're usually talking about machine learning, which means teaching a machine to learn from experience without explicitly programming it to do so. Deep learning, another hot topic, is a subset of machine learning and has been largely responsible for the AI boom of the last 10 years. In a nutshell, deep learning is an advanced type of ML that can handle complex tasks like image and sound recognition. We’ll discuss it in more detail in a later post.
One other thing worth mentioning about AI is that we sort of have this "Instagram vs. reality" scenario, if you will. That is, the way AI is portrayed in pop culture is not necessarily representative of where we’re at today. The examples of AI that we see in the media are usually “Artificial General Intelligence” or “Strong AI,” which refer to AI with the full intellectual capacity of a human, including thoughts and self-awareness. Think “Westworld,” “The Terminator,” “Ex Machina,” etc.
The good news is you can sleep soundly tonight knowing that this does not currently exist, and we’re probably still pretty far away from it — if it is even possible at all, which is up for debate. The closest thing we have to Strong AI today is voice assistants like Amazon's Alexa and Apple's Siri, but they’re pretty far away from having thoughts and feelings, and there are obviously serious concerns around ever creating AI with this level of human intelligence.
The AI/ML that we actually interact with in our day-to-day lives is usually “Weak AI,” which means that it is programmed to do one specific task. This includes things like credit card fraud detection, spam email classification, and movie recommendations on Netflix.
We can break machine learning into two key subcategories:
- Supervised ML, which uses a set of input variables to predict the value of an output variable.
- Unsupervised ML, which infers patterns from an unlabeled dataset. Here, you aren’t trying to predict anything, you’re just trying to understand patterns and groupings in the data.
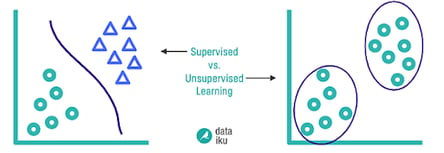
We will focus on supervised ML in this post. The idea is that we will look at historical data to train a model to learn the relationships between features, or variables, and a target, the thing we’re trying to predict. This way, when new data comes in, we can use the feature values to make a good prediction of the target, whose value we do not yet know.
Supervised learning can be further split into regression (predicting numerical values) and classification (predicting categorical values). Some algorithms can only be used for regression, others only for classification, and many for both.
Algorithms 101
We hear — and talk — a lot about algorithms, but I find that the definition is sometimes a bit of a blur. An algorithm is actually just a set of rules used to solve a problem. If you’ve ever taken a simple BuzzFeed quiz to answer important questions in your life, like what “Sound of Music” character matches your personality — you may notice that it’s really just asking a series of questions and using some set logic to generate an answer. Let’s explore the key categories of supervised learning algorithms.
Many of the most popular supervised learning algorithms fall into three key categories:
- Linear models, which use a simple formula to find a best-fit line through a set of data points.
- Tree-based models, which use a series of “if-then” rules to generate predictions from one or more decision trees, similar to the BuzzFeed quiz example.
- Artificial neural networks, which are modeled after the way that neurons interact in the human brain to interpret information and solve problems. This is also often referred to as deep learning.
We will look into each of these algorithm categories throughout the series, but this post will focus on linear models.
Machine Learning Algorithms in Action: Practical Examples
Let's say we're the owners of a candy store, Willy Wonka’s Candy, and we want to do a better job of predicting how much our customers will spend this week, in order to stock our shelves more appropriately. To get even more specific, let’s explore one specific customer named George. George is a 65-year-old mechanic who has children and spent $10 at our store last week. We’re going to try to predict the following:
- How much George will spend this week (hint: this is regression, because it is a dollar amount).
- Whether George will be a “high spender,” which we’ve defined as someone who will spend at least $25 at Willy Wonka's Candy this week (hint: this is a classification, because we’re predicting a distinct category, high spender or not).
Linear Models
So now let’s dive in and see how we can use a linear model. Remember, linear models generate a formula to create a best-fit line to predict unknown values. Linear models are considered “old school” and often not as predictive as newer algorithm classes, but they can be trained relatively quickly and are generally more straightforward to interpret, which can be a big plus!
We’ll explore two types of linear models:
- Linear regression, which is used for regression (numerical predictions).
- Logistic regression, which is used for classification (categorical predictions). Don’t get thrown off by the word “regression” in the name. I know, it’s confusing. I didn’t make the rules.
Linear Regression
Okay, let’s imagine we have a simple model in which we’re trying to just use age to predict how much George will spend at Willy Wonka’s Candy this week.
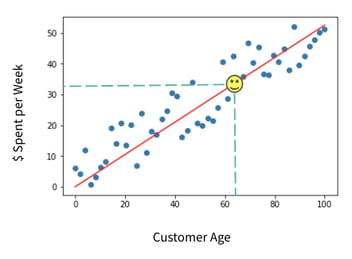
The data points we used to train our model are in blue. The red line is the line of best fit, which the model generated, and captures the direction of those points as best as possible.
Here, it looks like the older somebody is, the more money they will spend. We know George is 65, so we’ll find 65 on the x-axis and follow the green dotted line up until we meet the red “line of best fit.” Now we can follow the second dotted line across to the y-axis, and land on our prediction — we would predict that George will spend $33 this week.
Where does this red “line of best fit” come from? Well, you may be familiar with the formula y = mx + b, the formula for a straight line. This is the foundation of linear regression. All we need to do is reformat a few variables, add an error term (e) to account for randomness, and fill in our target ($ spent) and features (age).
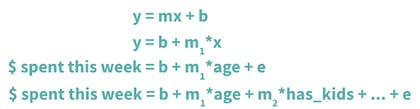
We’ll train a model to learn the relationship between age and dollars spent this week from past data points. Our model will determine the values of m1 and b that best predict the dollars spent this week, given the age. We can easily add in more features, such as has_kids, and the model will then learn the value of m2 as well.
In the real world, of course, building a straight line like this is usually not realistic, as we often have more complex, non-linear relationships. We can manipulate our features manually to deal with this, but that can be cumbersome, and we’ll often miss out on some more complex relationships. However, the benefit is that it’s quite straightforward to interpret — with a certain increase in age, we can expect a specific corresponding increase in dollars spent.
Logistic Regression
Now, rather than trying to predict George’s exact spending, let’s just try to predict whether or not George will be a high spender. We can use logistic regression, an adaptation of linear regression for classification problems, to solve this.
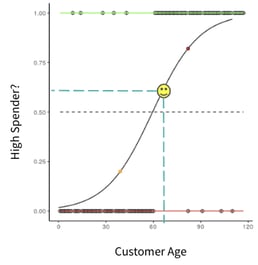
The black dots at the top and bottom are the data points we used to train our model, and the S-shaped line is the line of best fit.
You may have noticed that all data points in the above chart are either a 0 or a 1. This is because each point is marked as either a low spender (0) or a high spender (1). Now, we will use a logistic function to generate an S-shaped line of best fit, also called a Sigmoid curve, to predict the likelihood of a data point belonging to one category, in this case high spender. We also could have predicted the likelihood of being a low spender, it doesn’t matter. We’ll then use a predefined threshold to make a final prediction.
Let’s predict for George again — we’ll find 65 on the x-axis and then map it up to the S-shaped line and then across. Now, we think there is a 60%chance that George is a high spender. We’ll now use our threshold, which is indicated by the black dotted line in the chart above, to decide whether we will predict that he is a high spender or not.
Our threshold is 50%, so since our point is above that line, we’ll predict that George is a high spender. For this use case, a 50%threshold makes sense, but that’s not always the case. For example, in the case of credit card fraud, a bank might only want to predict that a transaction is fraudulent if they’re, say, 95%sure, so they don’t annoy their customers by frequently declining valid transactions.
Recap
Machine learning is really all about using past data to either make predictions or understand general groupings in your dataset. Linear models tend to be the simplest class of algorithms, and work by generating a line of best fit. They’re not always as accurate as newer algorithm classes, but are still used quite a bit, mostly because they’re fast to train and fairly straightforward to interpret.
More and more often, analysts and business teams are breaking down the historically high barrier of entry to AI. Whether you have coding experience or not, you can expand your machine learning knowledge and learn to build the right model for a given project.
We hope that you find this high-level overview of machine learning and linear models helpful. Be on the lookout for future posts from this series discussing other families of algorithms, including but not limited to tree-based models, neural networks, and clustering.