




{kind=link}
This is a guest post from our friends at Excelion Partners.
In this blog, we discuss an interesting historical anecdote between the history of tanks (yes, tanks) and what we can learn from their history as we launch data science initiatives.
Cautionary Tales
Have you ever listened to a podcast that gave you an idea? You may not do anything about it right away and that idea sticks in your brain... That’s what happened to me. I'm finally putting pen to paper on this concept. I’m a casual listener to Tim Harford’s podcast “Cautionary Tales." One of his early episodes is called “How Britain Invented, Then Ignored, Blitzkrieg.” For my military historian readers, please accept my apologies for the brevity of the military tactics in this discussion.
For those that don’t know the story of Blitzkrieg, I’ll begin in 1919 with a British officer named J.F.C. Fuller. He was obsessed with a new weapon of the British army: the tank. He was so obsessed that he theorized of a tactic utilizing tanks that could have neutralized the German forces in WWI by striking the German high command quickly and “winning the war in a single battle.” In the years to follow, his papers and war strategies on this topic won many awards.

The tank was utilized to some extent in WWI, but never to the maximum of Fuller’s theories. Tanks were organized in the British cavalry divisions. Many of the cavalry officers thought that the tank was a crude weapon and the horse’s intelligence when combined with the soldier was far superior. When tanks were utilized, they successfully penetrated German forces. However, British officers then sent in more traditional forces (like calvary) which allowed the Germans to recover and save themselves from being overwhelmed.
World War II
Fast forward to World War II. Hitler organized tanks within armored divisions (Panzer divisions) and implemented J.F.C. Fuller’s military tactics to defeat France, Belgium, and the Netherlands in just 46 days. Blitzkrieg was born.
The German army in World War II organized the Panzer units to include tanks and reinforced those tanks with infantry, anti-aircraft, and artillery. Ultimately, they recognized that tanks are not comparable to horses. They organized a division around the new technology and implemented it successfully.
Failed Opportunities
The example of the British poorly implementing tanks into their military is very easily translatable to the technology world:
- In 1973, Xerox built the first PC with an OS/GUI (think Windows) two years before Steve Wozniak even had the idea for the Apple 1.
- In 1975, Kodak created the first digital camera.
- In 1999, Sony created the “memory walkman” two years before the iPod.

Cautionary Tales podcast discusses two theories as to why companies fail when applying new technology to their business:
- What I’ll call the “Disruption” theory based on Innovator's Dilemma: Existing organizations are exceptionally good at what they do, but if they keep doing what they have always done they will fail. Organizations have the ability to see and build new things, but the application of this innovation is wasted by applying new innovation to the incorrect market. At the same time, new companies are continually applying new technology to find niches, improve, and take greater market share from the existing organizations.
- What I’ll call the “Organizational” theory based on Architectural Innovation: Organizations struggle with innovation and new technologies because it doesn’t fit into the current organizational chart.
Learning From History
When it comes to data science (finally got to the point, didn’t I), I witness more organizations struggling with its implementation due to the Organizational theory. Data Science as a competency doesn’t fit nicely into normal organizational structure. As a demonstration of this, let’s take a look at the key roles in a data science project:
- Data Analyst (or Citizen Data Scientist) - Typically sits within a business unit analyzing data on excel spreadsheets or some other desktop tool.
- Data Engineer - Typically sits within IT. IT likely has a backlog of data requests like reports or data warehouse initiatives.
- Data Scientist - Could sit anywhere. Inside a data science team, innovation team, IT, a business unit, etc.
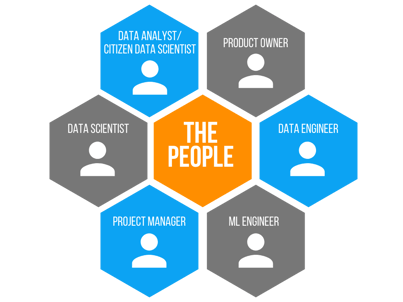
This organizational structure for data science is set up to perform, at best, clunky. At its worst, the performance of this structure could sour the entire organization on the documented benefits of data science.
Just as the German army organized around the new tank technology to utilize it optimally, data science leaders or leaders that understand the business value of data science need to steer the organizational structure to support these endeavors. There are multiple documented organizational models out there, such as this infographic highlighting an AI Center of Excellence. In conclusion, we can learn a lot from history. I hope this was a fun, yet informative, analogy. Good luck with all your data science endeavors!