




Some people don’t engage with others on data and AI because they perceive a barrier between how they work with data and how they could work with data — call it an unrequited dream of something better. Others simply don’t think data and AI are relevant to their work at all, as neither appear in their job title. And sometimes even when people work on data and AI together, collaboration can be challenging because they use data for different things, and so they look at it in different ways.
In my time as a data analyst and data scientist, I often got into conflict with DBAs — Database Administrators — enterprise gatekeepers of the valuable information underlying business systems like point-of-sale, customer relationship management, etc. These databases are highly optimized to keep those applications running and performing well, and everything else is secondary, including the requests of a pesky “data person” asking poorly-formed questions, who keeps saying “just give me the data and I’ll do the rest of the work myself.” To many DBAs, such requests sound, at best, like ill-advised attempts to waste time and money repeating work they have already done (“building reports” off that same data) and, at worst, a gateway to chaos, where anything goes and incorrect decisions might be made, based on work done by people who cannot possibly understand all the nuance in the data. I was right, and so were they!
What drives such polarized perspectives, and how can we use that understanding to improve collaboration and create more value from data? Given the underlying problem is people with different perspectives talking past each other, an analogy might be helpful.
The Analogy: Data as Matter
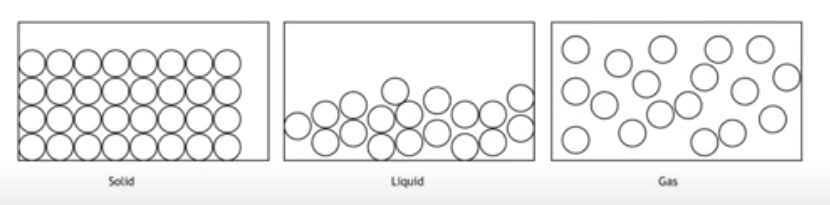
What do we mean when we say that people look at data in different ways? We can draw an analogy to three states of matter — solid, liquid, and gas — to underscore that it’s possible to view data as all three, but one state will likely resonate more depending on your background and particular experience working with data.
- Data as Solid: When we want to make a decision (i.e., do we buy this item or that one, should my team work on this project or that one), it’s fair to say we want a nicely structured, solid table of data in order to produce valuable insights. Relationships between the particles or cells (i.e., rows of a dataset) are clearly defined, orderly, and stable. For some people, this is the only context in which they have encountered data (in “reports” built by others) and for others, like my DBA friends above, it is the bedrock on which their entire worldview is based.
- Data as Liquid: Here, we can think of assembling data and pulling it together from different sources, mixing, blending, alloying these diverse elements, to (eventually) make a different kind of solid. This perspective illuminates the popularity of water metaphors and concepts over the last 5-10 years: streams, lakes, etc. It resonates best with data engineers whose job it is to get data moving or flowing from system to system, while keeping it as some coherent whole, just as a liquid can be separated for a time and rejoined easily. To many others though, this view uncomfortably breaks down the certainty we feel looking at a nice table of solid data.
- Data as Gas: My academic training is in social science and, when I think from that perspective, data are just ephemera, generated out in the world by humans acting within processes, floating around separately from each other. Think of how much business data is just harvested from a process, perhaps using a spreadsheet, with no real up-front plan. While we’d love data to be easily condensed into liquids, mixed together, and frozen into reliable solid matter, there is nothing guaranteed in that process. It’s easy to lose data, just as gases dissipate with no special effort; separating the data we want from the data we don’t is just as tough as filtering the air of pollution. Nevertheless, we must undertake that effort, with eyes open, to use data to reliably inform decisions: like changing the states of matter, it takes energy.
{kind=link}
Depending on your role, you might gravitate toward one end of the spectrum or another: collectors or users of data might lean toward data as a gas, while developers, software engineers or DBAs tend to lean toward the solid view. Sympathizing with others’ views may not happen overnight as it very well could require a change in mindset, but is important all the same.
Getting Value From the Analogy
So, how can this solid, liquid, gas analogy for data help organizations with diverse perspectives, skill sets, levels of technical expertise, and backgrounds collaborate on their data science and AI projects? Well, for starters, we need to understand what each other means when we talk about data. It’s clear that data scientists and database administrators look at the same entities completely differently, for example.
Good news — this is okay! We want people to think differently about data — it’s part of everyone’s job, all of the perspectives are equally valid, and so it shouldn’t be shocking to anyone that these differences can lead to difficulty collaborating. Data needs to be collected, stored, modeled, and represented, and if people with different jobs think about what data is and what it’s used for in a different way, it’s natural to miss connections and misplace assumptions when working together. What matters is how we use those differences to build more value than we could alone.
My preferred definition of data is that it “measures behavior and its outcomes.” While I know this isn’t to everyone’s liking, recognizing my own preference helps me better see others’ perspectives, which is crucial to developing a team sport mindset around data and AI. The next time you can’t get through to someone what data you need for your critical project, step back and ask yourself: What perspective am I taking on data here, and what about the other person? Am I asking for “solid” when all they have is “gas”? Or are we both talking “liquid” but one is oil and the other water?