




{kind=link}
Across industries, technologies, and use cases worldwide, there is perhaps no other data science strategy more important to understand and to leverage than anomaly detection. While useful across an array of industries and for a variety of purposes, one use case stands out above the rest: anomaly detection for IT and DevOps teams.

The Larger Picture
Anomaly detection is the ability to find patterns of interest (outliers, exceptions, peculiarities, etc.) that deviate from expected behavior within datasets. This may sound (relatively) simple if you think of a basic use case, like for example, your bank identifying that an out-of-the-ordinary purchase was, in fact, fraudulent.
But in practice, anomaly detection is generally much more nuanced and complex, which can make it daunting (though critical) to undertake. For a closer look at a variety of uses cases, get the latest guidebook for an in-depth walk-through at executing on anomaly detection at scale.
. 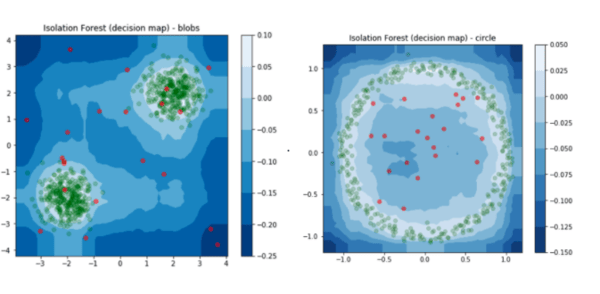
Visualizations are especially useful in the process of building and testing anomaly detection models because sometimes they are the clearest way to see outliers, especially in very large datasets. For more, get the anomaly detection how-to guidebook.
The IT and DevOps Angle
In fact, one of the most important use cases for anomaly detection today is for monitoring by IT and DevOps teams - for intrusion detection (system security, malware), production system monitoring, or monitoring for network traffic surges or drops. The bottom line: increase up time and reduce any downtime through, of course, prevention but also quick identification of any issues the minute they arise.
This use case is wide-reaching for obvious reasons: it transcends industries and is something almost every company today has to grapple with, no matter what service or product they provide. But that doesn’t mean it’s easy.
Challenges include the need for a real-time pipeline to react, which isn’t always feasible. In addition, this use case involves huge volumes of data plus the unavailability of labeled data corresponding to intrusions making it difficult to train and test (usually teams have to adopt a semi-supervised or unsupervised approach). But it is these challenges that make the development of a scalable anomaly detection system even more critical.