




{kind=link}
For some tasks, spreadsheets will always be suitable, but for everything else, it's time to think responsible and with a bigger perspective.
As a community, we have been “digitally transforming” for decades — digitizing traditional business transactions that generate data (of which there’s more and more every day) for diverse teams to consume across the business. And yet, the way we collaborate during the analytics lifecycle continues to be very segmented by categories like coders vs. non-coders, open source vs. enterprise solutions, or tool A vs. tool B.
These solutions are designed to solve problems for specific pieces of a data pipeline (from raw data to dashboards, ML, or data products consumed by others that generate business value). In addition to this lack of communication, teams work using categorized or isolated pockets of tech (different people, with different skills prefer Tool A vs. Tool B) that are not necessarily integrated, and this generates a lot of friction for processes where teams need to be able to “tech-communicate.”
The Opportunity at Hand
Today, data is everywhere. It's generated by our phone calls and texts, social media posts, and online searches. And it's not just personal data; businesses are collecting mountains of data on their customers, transactions, and operations. All of this data has the potential to be transformational, and increasing availability and use of data can inspire new ways of working that translate in better insights that can help us make better decisions, improve our products and services, and impact our businesses.
According to McKinsey, by building ML into processes, leading organizations are increasing process efficiency by 30% or more while also increasing revenues by 5% to 10%. And to achieve this kind of metrics, new ways of working require cultural change, in particular with respect to how we do things with data and adjust to the current business demand for responsible, reusable, transparent, and governable data outcomes.
Leveraging the transformational potential of increasingly available data, spreadsheets became a ubiquitous tool that enabled XYZ. However, as increasingly innovative uses of data and data science are undertaken by organizations, spreadsheets' limitations start to show.
These limitations extend beyond computational ones. They also can't accommodate or enable the enforcement of formalized processes and practices regarding how people should document or do their work. In short, they omit governance frameworks and, should they be needed by a user, they have to exist outside the tool where there's risk for inconsistent application. Importantly, this is a compounding risk.
Where organizations are leveraging data in increasingly innovative ways, the risks associated with data outcomes are also rising. AI/ML or advanced analytics projects are now part of a bigger picture that touches on everything from responsible practices (e.g. bias, fairness, robustness, etc.) to compliance (e.g., doing everything you need to according to a set of internal and/or external requirements). Accepting that these risks exist and need to be addressed should be first, technology needs to follow that vision with systematic governance and responsible practices to minimize risk and maximize value.
When thinking about data projects, I see data as “water through a pipeline,” so the last thing I need is “green water” without knowing why it is green! This is called data traceability, and it is tough to achieve when everyone is doing their own thing on a non-single version of the truth data table, not integrated with production infrastructure.
Here are the three reasons why I see Dataiku as the “go-to” technology across teams for companies to maximize data outcomes responsibly:
1. Teams Need to Be Able to "Tech Communicate"
Like moving to another country and speaking a second language, the opportunities get bigger and better when you can communicate. You discover a whole new culture that enriches and empowers you (and believe me, I know this as an immigrant myself!). The same should happen with what we create with data and technology. It should be shareable, reusable, and adjusted to the team’s skills.
Today, I still see very siloed teams working on tech buckets, very different tools, usually not integrated enough, each meant to solve a very specific problem. This segmentation generates a communication problem that reflects in the data outcomes generated globally by teams across business units.
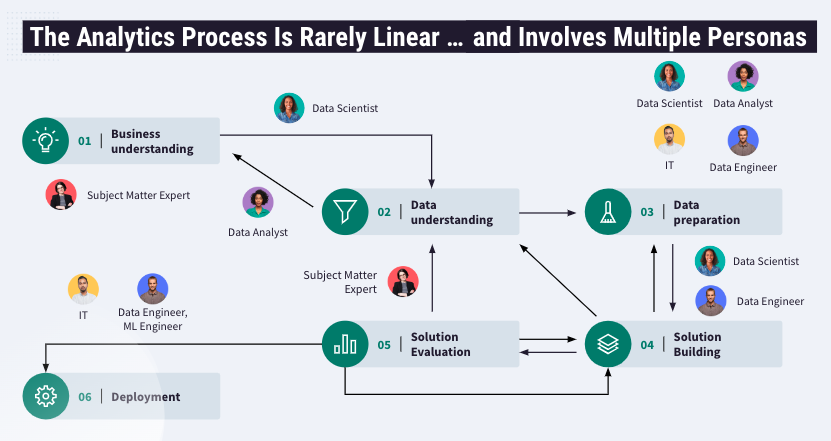
Let’s think about what happens during an analytics cycle:
The business questions should be first, and data sources that will support each of the variables that are part of the business questions should follow. At this point, different players should be in sync regarding the question they are trying to solve and understand the data that will support the project (data engineers, business analysts, data scientists, etc., could be involved at this stage). Most likely, data preparation will be needed, and that in itself will generate some questions back to the business (this may involve multiple tools that require different sets of skills). This step can take weeks.
After iterations back and forth with different team members, the data pipeline advances to a solution-building stage where the goal is to experiment with descriptive and predictive analytics, ML techniques, and parameters and settings to generate a consumable data outcome (i.e., dashboards, API endpoints for ML, ETL automation jobs, ML apps, etc.). After 10+ years solving a wide variety of business challenges with analytics and machine learning across Fortune 500 companies globally, I see significant bottlenecks usually tied back to a few consistent themes: lack of documentation, lack of visibility/traceability, generational tribal knowledge, lack of tool integration, and lack of reusable “artifacts” that have been created by a very diverse team that speak a different “tech language” (e.g., code vs. no-code). The solution-building stage can take weeks to get right with all these challenges.
Next, the data pipeline advances to a stage where the solution needs to be evaluated. This means that, before entering this stage, the use case has been described (e.g., visualizations and dashboards), the results are consistent with expectations defined by the analysts or business users, and predictive analytics is transparent and provides explainability for a diverse team to agree and validate the solution. The subject matter expert (SME) will need to understand what the team has been generating and provide insights and feedback if needed. Your data pipeline has to align with the company’s AI Governance framework and values, and it has to be intentional, accountable, and transparent. This AI Governance framework should allow the teams to proactively check for and mitigate issues related to fairness, transparency, accountability, and reliability for these data outcomes generated by the teams.
At this point, the teams should have enough data and analytics that adequately represent the business question, and deploying the data pipeline to production will link the solution to the production infrastructure (where is your data today, where and how it needs to be tomorrow, who needs to have access to it, to see what, how often, API endpoints for ML models, AI, etc.) for final users to consume these data insights. A strong MLOps practice, populated with reviews and sign-offs informed by AI Governance requirements , will ensure that these deployed pipelines stay aligned with their original intention and remain robust in production.
All these steps are part of a data pipeline that will potentially be consumed by teams — from three to 100s or 1,000s — the bigger the company, the more complex the infrastructure, and the more diverse the teams and skills involved.
Data is essential for making informed decisions, but as I have highlighted at every step of the analytics pipeline, it's only part of the equation. Information is what you get when you process data, and it's only as good as the algorithms used to generate it. Responsible AI (RAI) includes keeping a broad set of humans in the loop so that we can ensure that the algorithms we use are producing responsible outcomes. And we as humans need to be able to communicate and “tech-communicate,” regardless of the skills we bring to the table.
Dataiku allows teams to tech-communicate, with technology that orchestrates the behind-the-scenes of the analytics lifecycle while sharing and reusing “artifacts” created by the teams with their skills as they are today (one artifact could represent a data connection, another could be a Jupyter notebook with an ML model, the next one could be a dashboard, etc.).
2. Teams Need to Be Empowered Today, Regardless of Code or No-Code Skills
The next spreadsheet tool will have to be a “Responsible AI-first” data platform powered by collaboration and used by anyone, regardless of skill set. It is essential to keep the human in the loop at all times within the data science cycle. A cultural change requires people of all backgrounds and skill levels to contribute to data projects, whether it is through coding, data visualization, model deployment, or SME feedback.
People are the best assets we have in our organizations. Inclusive collaboration, planning data projects together, drafting data collection standards together, and analyzing data together are best practices that I see consistently working for successful data projects.
3. Teams Need a Governance Framework for AI at Scale
At Dataiku, we believe that the only way to scale AI is to build an effective AI Governance program, where “effective” means that individuals building AI projects aren’t encumbered by or worrying about risk themselves because, by definition, they’re working in a governed way. A strong AI Governance framework should:
- Centralize, prioritize, and standardize rules, requirements and processes aligned to an organization’s priorities and values
- Inform operations teams, giving build and deployment teams the right parameters to deliver
- Grant oversight to business stakeholders so they can ensure that AI projects (with or without models) conform to requirements set out by the company
Deploying data outcomes into production should not be the end of the analytics lifecycle. Keeping guardrails and overseeing the behavior of ML/AI through time with new data as the business grows is the responsible approach. Many roles across teams can also be involved at this stage: The person who needs to be notified about ML model drift is likely not the same person who will be retraining the model. Consistent team communication is essential, as the business relies on these outcomes to make good decisions. Decisions based on these outcomes must be able to rely on models built responsibly.
Dataiku's approach to AI Governance and RAI supports business values and principles across the entire AI/ML lifecycle, allowing people to connect with technology and processes in an intentional, accountable, and transparent way.
Key Takeaways
So, after decades of digital transformation and with more data than ever to generate insights and AI from, we need to think about a new approach to data science as a team sport, where the team can “tech-communicate” and reuse assets regardless of who produced them or how they were produced, and incorporate an AI Governance framework that supports a data-driven culture.
The data science community has been learning to use data better and assemble more diverse teams to reuse assets we create together. We understand the importance of including our experts and their wisdom in our data science pipelines as a primer to AI-driven cultural change. The tool sets we use need to support our evolution and vision as a data science community, especially as data science is constantly transforming.
I see Dataiku as the “go-to” technology for spreadsheet users because Dataiku embraces this transformation, allowing many teams to “tech-communicate” regardless of code or no-code skills. Dataiku becomes that AI governance framework that will ensure RAI across the entire ML lifecycle orchestrating RAI deployments, connecting the humans and their expertise with what generates value for them and their business. Empowering people to make the best out of the technology with their current skills, smoothing out the processes that transform data into valuable information, and maximizing business impact.