





Note that this guide is quite old (it was written when Hive was at version 0.10) and might not apply as-is to recent Hive releases. Use at your own risk :)
Dataiku DSS provides deep integration with Hive (Execution engine for visual transformations, HiveQL notebook, autocompletion, syntax checking, schema validation, ...)
At Dataiku, when we need to build complex data processing pipelines or analyze large volumes of data, Hive is one of the main tools that we use.
![]()
Hive provides a simple way of expressing complex queries using SQL, which basically everybody knows.
Combined with Pig, it allows us to create processing pipelines that can scale quite easily without having to write low-level map-reduce jobs.
While Hive is a powerful tool, it is sometimes lacking in documentation, especially in the topic of writing UDFs.
User Defined Functions, also known as UDF, allow you to create custom functions to process records or groups of records. Hive comes with a comprehensive library of functions. There are however some omissions, and some specific cases for which UDFs are the solution.
Developing UDFs in Hive is by no means rocket science, and is an effective way of solving problems that could either be downright impossible, or very akward to solve (for example by using complex SQL constructs, multiple nested queries or intermediate tables). The lack of documentation and resources to help in this process however makes it quite painful. While there are a few tutorials out there, they generally don't cover the whole scope nor the common traps.

This post will therefore try to make writing Hive UDFs a breeze.
Hive UDF versus UDAF
In Hive, you can define two main kinds of custom functions:
UDF
A UDF processes one or several columns of one row and outputs one value. For example :
-
SELECT lower(str) from table
For each row in "table," the "lower" UDF takes one argument, the value of "str", and outputs one value, the lowercase representation of "str".
-
SELECT datediff(date_begin, date_end) from table
For each row in "table," the "datediff" UDF takes two arguments, the value of "date_begin" and "date_end", and outputs one value, the difference in time between these two dates.
Each argument of a UDF can be:
-
A column of the table
-
A constant value
-
The result of another UDF
-
The result of an arithmetic computation
TODO : Example
UDAF
An UDAF processes one or several columns of several input rows and outputs one value. It is commonly used together with the GROUP operator. For example:
-
SELECT sum(price) from table GROUP by customer;
The Hive Query executor will group rows by customer, and for each group, call the UDAF with all price values. The UDAF then outputs one value for the output record (one output record per customer);
-
SELECT total_customer_value(quantity, unit_price, day) from table group by customer;
For each record of each group, the UDAF will receive the three values of the three selected column, and output one value of the output record.
Simple Hive UDFs
In Hive, you can write both UDF and UDAF in two ways: "simple" and "generic".
"Simple", especially for UDF are truly simple to write. It can be as easy as:
/** A simple UDF to convert Celcius to Fahrenheit */
public class ConvertToCelcius extends UDF {
public double evaluate(double value) {
return (value - 32) / 1.8;
}
}
Once compiled, you can invoke an UDF like that:
hive> addjar my-udf.jar hive> create temporary function fahrenheit_to_celcius using "com.mycompany.hive.udf.ConvertToCelcius"; hive> SELECT fahrenheit_to_celcius(temp_fahrenheit) from temperature_data;
Simple UDF can also handle multiple types by writing several versions of the "evaluate" method.
/** A simple UDF to get the absolute value of a number */
public class AbsValue extends UDF {
public double evaluate(double value) {
return Math.abs(value);
}
public long evaluate(long value) {
return Math.abs(value);
}
public int evalute(int value) {
return Math.abs(value);
}
}
In short, to write a simple UDF:
-
Extend the org.apache.hadoop.hive.ql.exec.UDF class
-
Write an "evaluate" method that has a signature equivalent to the signature of your UDF in HiveQL.
Types
Simple UDF can accept a large variety of types to represent the column types. Notably, it accepts both Java primitive types and Hadoop IO types
| Hive column type | UDF types |
|---|---|
| string | java.lang.String, org.apache.hadoop.io.Text |
| int | int, java.lang.Integer, org.apache.hadoop.io.IntWritable |
| boolean | bool, java.lang.Boolean, org.apache.hadoop.io.BooleanWritable |
| array<type> | java.util.List<Java type> |
| map<ktype, vtype> | java.util.Map<Java type for K, Java type for V> |
| struct | Don't use Simple UDF, use GenericUDF |
Simple versus Generic
While Simple UDF and UDAF are .. simple, they do have some limitations and shortcomings. The main limitation is related to handling of complex types. One of Hive's main feature is its advanced handling of advanced types:
-
Arrays of typed objects
-
Maps of typed keys and values
-
Structs of typed named fields
The system of simple UDFs is based on reflection and method overloading, which cannot accept everything.
For example, if you wanted to write an "array_sum" UDF, that would return the sum of elements in an array, you would write
But what happens if you would also handle arrays of integers ? You cannot overload with
public int evaluate(List<Integer> value)
because this is not valid in Java : the types of a method cannot differ by only the generic type. For more details, see the Generics article on Wikipedia
For this UDF to work, we need to use a Generic UDF.
The following table summarizes the main differences between Simple UDF / UDAF and Generic UDF / UDAF
| Simple | Generic |
|---|---|
| Reduced performance due to use of reflection: each call of the evaluate method is reflective. Furthermore, all arguments are evaluated and parsed. | Optimal performance: no reflective call, and arguments are parsed lazily |
| Limited handling of complex types. Arrays are handled but suffer from type erasure limitations | All complex parameters are supported (even nested ones like array<array> |
| Variable number of arguments are not supported | Variable number of arguments are supported |
| Very easy to write | Not very difficult, but not well documented |
Generic Hive UDF
A generic UDF is written by extending the GenericUDF class.
public interface GenericUDF {
public Object evaluate(DeferredObject[] args) throws HiveException;
public String getDisplayString(String[] args);
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException;
}
A key concept when working with Generic UDF and UDAF is the ObjectInspector.
In generic UDFs, all objects are passed around using the Object type. Hive is structured this way so that all code handling records and cells is generic, and to avoid the costs of instantiating and deserializing objects when it's not needed.
Therefefore, all interaction with the data passed in to UDFs is done via ObjectInspectors. They allow you to read values from an UDF parameter, and to write output values.
Object Inspectors belong to one of the following categories:
-
Primitive, for primitive types (all numerical types, string, boolean, …)
-
List, for Hive arrays
-
Map, for Hive maps
-
Struct, for Hive structs
When Hive analyses the query, it computes the actual types of the parameters passed in to the UDF, and calls
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException;
The method receives one object inspector for each of the arguments of the query, and must return an object inspector for the return type. Hive then uses the returned ObjectInspector to know what the UDF returns and to continue analyzing the query.
After that, rows are passed in to the UDF, which must use the ObjectInspectors it received in initialize() to read the deferred objects. UDFs generally stores the ObjectInspectors received and created in initialize() in member variables.
First, here is a very minimal sample of an UDF that takes an integer, and returns it multiplied by two. We could have easily implemented this sample as a simple UDF. This is really a minimal sample, that lacks some very important type checking logic, which we'll add later
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector.PrimitiveCategory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.IntWritable;
public class UDFMultiplyByTwo extends GenericUDF {
PrimitiveObjectInspector inputOI;
PrimitiveObjectInspector outputOI;
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
// This UDF accepts one argument
assert (args.length == 1);
// The first argument is a primitive type
assert(args[0].getCategory() == Category.PRIMITIVE);
inputOI = (PrimitiveObjectInspector)args[0];
/* We only support INTEGER type */
assert(inputOI.getPrimitiveCategory() == PrimitiveCategory.INT);
/* And we'll return a type int, so let's return the corresponding object inspector */
outputOI = PrimitiveObjectInspectorFactory.writableIntObjectInspector;
return outputOI;
}
public Object evaluate(DeferredObject[] args) throws HiveException {
if (args.length != 1) return null;
// Access the deferred value. Hive passes the arguments as "deferred" objects
// to avoid some computations if we don't actually need some of the values
Object oin = args[0].get();
if (oin == null) return null;
int value = (Integer) inputOI.getPrimitiveJavaObject(oin);
int output = value * 2;
return new IntWritable(output);
}
@Override
public String getDisplayString(String[] args) {
return "Here, write a nice description";
}
}
Here is another minimal sample of an UDF that takes an array as only parameter, and returns the first element of this array. We could not have done that with a simple UDF, because of type erasure. This is still a minimal sample, that lacks some very important type checking logic, which we'll add later
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;
public class UDFArrayFirst extends GenericUDF {
ListObjectInspector listInputObjectInspector;
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
assert (args.length == 1); // This UDF accepts one argument
// The first argument is a list
assert(args[0].getCategory() == Category.LIST);
listInputObjectInspector = (ListObjectInspector)args[0];
/* Here comes the real usage for Object Inspectors : we know that our
* return type is equal to the type of the elements of the input array.
* We don't need to know in details what this type is, the
* ListObjectInspector already has it */
return listInputObjectInspector.getListElementObjectInspector();
}
public Object evaluate(DeferredObject[] args) throws HiveException {
if (args.length != 1) return null;
// Access the deferred value. Hive passes the arguments as "deferred" objects
// to avoid some computations if we don't actually need some of the values
Object oin = args[0].get();
if (oin == null) return null;
int nbElements = listInputObjectInspector.getListLength(oin);
if (nbElements > 0) {
// The list is not empty, return its head
return listInputObjectInspector.getListElement(oin, 0);
} else {
return null;
}
}
@Override
public String getDisplayString(String[] args) {
return "Here, write a nice description";
}
}
See? It's not much more complex than a simple UDF, but much more powerful.
Some Traps of Generic UDF
Everything in the Generic UDF stack is processed through Object, so you will definitely have a hard time grasping the correct object types. Almost no type checking can be done at compile time, you will have to do it all at Runtime.
It is important to understand that the Object returned by the evaluate method must be a Writable object. For example, in the "multiply by two" example, we did not return Integer, but IntWritable. Failure to do so will result in cast exceptions.
Debugging generic UDFs is not trivial. You will often need to peek at the execution logs.
-
When running Hive in full map-reduce mode, use the task logs from your Jobtracker interface
-
When running Hive in local mode (which I recommend for development purposes), look for the following lines in the Hive output
Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Execution log at: /tmp/clement/clement_20130219103434_08913263-5a10-496f-8ddd-408b9c2ff0af.log Job running in-process (local Hadoop) Hadoop job information for null: number of mappers: 0; number of reducers: 0
Here, Hive tells you where the logs for this query will be stored. If the query fails, you'll have the full stack there.
More on Writable versus Primitive
ObjectInspectors, especially primitive ones, exist in two versions: Writable versions and Primitive versions. Some tools like ObjectInspectorUtils.compare are very sensitive to this distinction. Using the wrong kind of ObjectInspector leads to cast exceptions.
To switch between modes, use:
ObjectInspector before; after = ObjectInspectorUtils.getStandardObjectInspector(before, ObjectInspectorCopyOption.WRITABLE)
A note about threading
Hive creates one instance of your UDF per mapper, so you may store some data as instance variables safely : each instance of your UDF will only be used in a single thread. However, multiple instances of the UDF can be running concurrently in the same process.
UDAF
Writing a UDAF is slightly more complex, even in the "Simple" variation, and requires understanding how Hive performs aggregations, especially with the GROUP BY operator.
In Hive, the computation of an aggregation must be divisible over the data :
-
given any subset of the input rows, the UDAF must be able to compute a partial result (and actually, you won't receive all rows at once, but one after another, and must be able to keep a state)
-
given a pair of partial results, the UDAF must be able to merge them in another partial result
-
given a partial result, the UDAF must be able to compute the final result (a single column value)
Furthermore, you must be able to serialize the partial result to an Object that MapReduce can read and write.
The main algorithm revolves around 4 functions and 3 modes, called PARTIAL1, PARTIAL2 and FINAL
| aggregate(input values, aggregation buffer) | Process a row of input data and store / update the partial result in the aggregation buffer | PARTIAL1 |
| terminatePartial(aggregation buffer) | Return the content of the aggregation buffer in a Writable way | PARTIAL1, PARTIAL2 |
| merge(aggregation buffer, writable_buffer) | Merge an aggregation buffer, in the format returned by terminatePartial() into an aggregation buffer | PARTIAL2, FINAL |
| terminate(aggregation buffer) | rocess the final (with all partial results merged) aggregation buffer into a single output value | FINAL |
Additionally, your Generic UDAF provides two functions:
-
getNewAggregationBuffer: initializes a new aggregation buffer
-
reset : resets an aggregation buffer, making it ready for reuse
PARTIAL 1 phase
Hive performs a pre-grouping in the mapper, based on a HashTable. For each value of the grouping key(s), a new aggregation buffer is created, and for each row, the "aggregate" method is called.
When the Map task is finished (or if the hash table becomes "too big"), Hive calls the terminatePartial method to get a serialized version of the partial results associated to each grouping key.
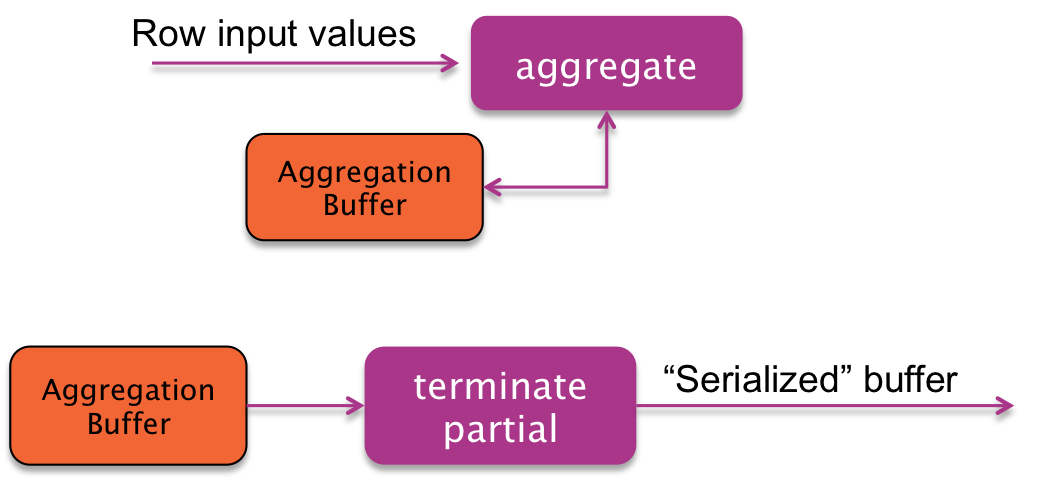
PARTIAL 2 phase (optional)
In some situations, Hive will choose to make an additional partial results merge phase (usually, in a MapReduce Combiner)
Hive will have the serialized aggregations sorted by grouping keys. For each of the keys, it will get a clean aggregation buffer, merge all partial results in a single one using the "merge" function, and then, call terminatePartial to get a serialized version of the partial results.

FINAL phase
This phase runs in the Reducer of the MapReduce algorithm.
Hive will have the serialized aggregations sorted by grouping keys. For each of the keys, it will get a clean aggregation buffer, merge all partial results in a single one using the "merge" function, and then, call terminate to get the final output value.
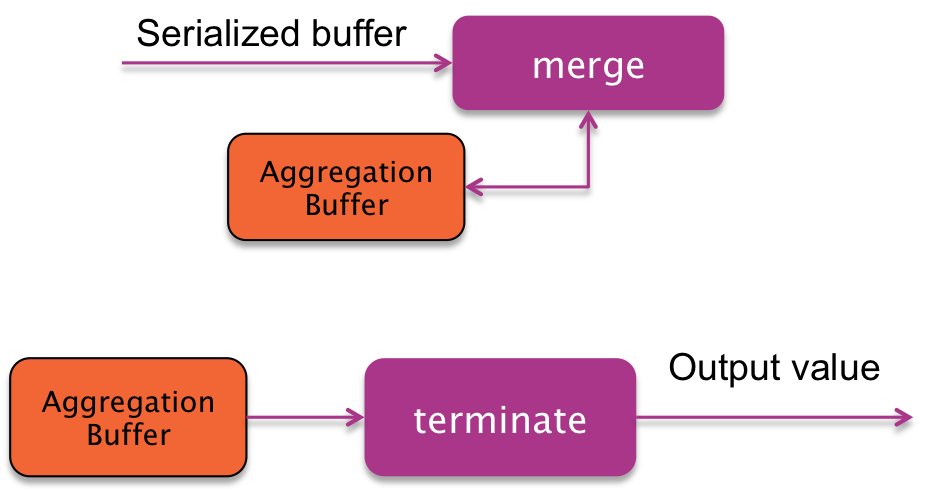
COMPLETE mode
Alternatively to the PARTIAL1 / PARTIAL2 / FINAL mode, Hive UDAF can also be called in a single mode, called COMPLETE. In that mode, all is done in one single step:
-
Aggregate
-
Terminate
Sample
A note about copying Common mistakes with GenericUDAF A common mistake is forgetting to call super.init(m, parameters) when creating your evaluator. This will result in Hive miscomputing the mode your UDAF runs in, calling the wrong methods, and generally failing.