




{kind=link}
When working with text values provided by real users, you must deal with various approximations or typing errors. Let's have a look at how Dataiku DSS makes dealing with a list of misspelled movie titles incredibly easy.
In a previous article, I illustrated how to use text normalization and text clustering within Dataiku DSS to work on text based datasets. Let's now see another use case.
We have two different lists:
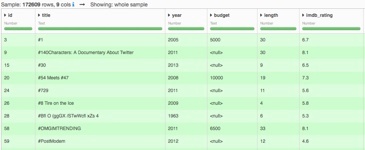
- The first is a list of ~173,000 movie titles extracted from IMDb
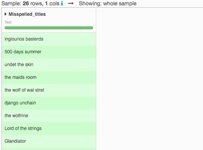
- The second one is a list of queries that users have entered in a search field. These queries contain various typos and misspelled titles.
This is a typical use case, as we want to match every searched title from the queries list with the actual movie from the IMDb database. This will allow us to add some additional data in our queries dataset (e.g. the genre and average rating). This could allow us to better understand what our users search for. We call this operation a join. When the values to compare are not exactly identical, it can become quite difficult to perform.
Thus, we perform what we call a "fuzzy join." It is a special join that can match even if the two strings being compared are not exactly equal, but close. For example, we would like to match the query 'inglourios basterds' with the real movie title 'Inglorious Bastards'.
Here is an overview of the two lists :
The transformation is easy to perform in Dataiku DSS. On the list of misspelled titles, let us apply the processor "Fuzzy join" and just fill a few parameters:
- The column to join on: 'Misspelled_titles'
- The dataset to join with: the list of movies extracted from IMDb that is named 'movies' in this case
- The column to join with: 'title'
- Columns to retrieve: 'title' and 'imdb_rating' (ratings are numbers on a scale of one to ten)
- An optional prefix for copied column names
- Some text 'simplification' that we can run beforehand: we choose to 'normalize text' to get better results
- The maximum distance between the simplified strings so that they are considered a match
The key parameter is the maximum distance for the match. The algorithm uses the Damerau–Levenshtein distance. Increasing this distance will lead to more matches but also probably imply more mistakes in matching.
Let us have a look at how this parameter changes the match. With a distance at one, we match 14 movies out of our list of 26 misspelled movie titles. Basically, it finds titles that are one operation away from the real title, where an operation is defined as an insertion, deletion, or substitution of a single character, or a transposition of two adjacent characters.
With a distance at two, we get 21 matches. At three, we get 24. All titles match for a distance of four.
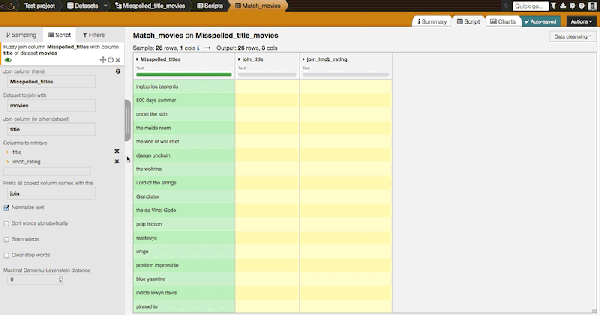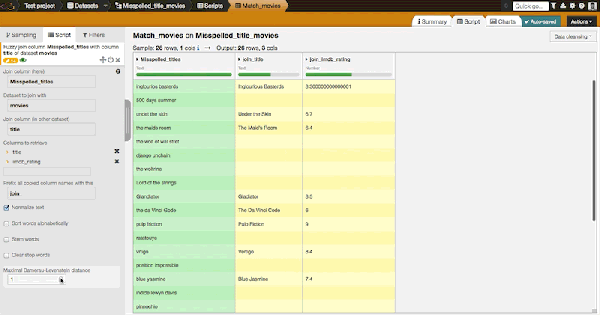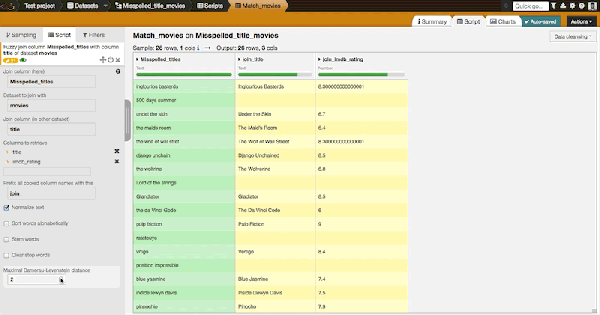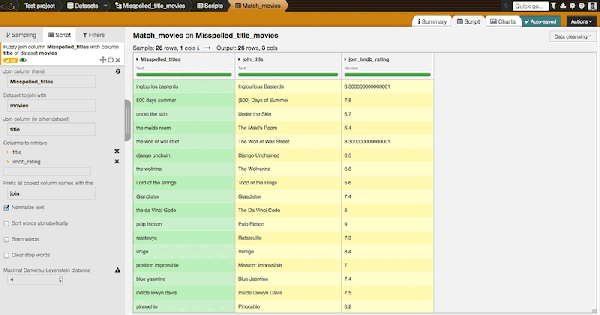
Note that few matches are not the ones probably expected. For example, 'toy stories' matches with 'Dog Stories' but 'toy stories 2' goes with 'Toy Story 2'. You may consult the full final list here. Fuzzy join, directly integrated in Dataiku DSS's visual interactive data preparation is really convenient whenever you need to match together text values that were entered manually.