




{kind=link}
This version of Technoslavia has been replaced with Technoslavia 2020 - check out the latest version!
My grandmother was born in a country called Yugoslavia. As you may know, Yugoslavia was one country with seven borders, six republics, five nationalities, four languages, three religions, and two alphabets. So, I used relatively sophisticated words like "Balkanization" at a fairly young age; and I still use it gladly to qualify the technological world of data infrastructure today.
Historically, the term Balkanization was not used to refer to Yugoslavia itself, but rather in reference to the Ottoman Empire and Austro-Hungarian Empire in the 19th century. These two empires, in fact, at the end of the Napoleonic wars, covered a large area of Europe, including countries such as today's Romania, Bulgaria, Greece, Croatia etc. As the 19th century progressed, successive fragmentations of empires led to the creation of autonomous states, which were sometimes united against their common enemies (the two great empires), sometimes hostile towards each other. The evolution of these republics occurred under pressure from the major powers, particularly Russia, always looking for strategic access to the Mediterranean.
If one dared to make a bold comparison, the world of Business Intelligence of the 90s, dominated by a few solutions (Cognos from IBM, Business Object from SAP, Oracle, SAS) fragmented starting in the early 2000s under the pressure of new solutions, for the most part open source. These Open Source solutions were developed in large part by stakeholders of the Internet revolution (Yahoo, Facebook, Twitter, LinkedIn) who chose the open source way for the construction of infrastructure under the pressure of a dominant Google.
This is where our comparison stops, because there is no war or conflict between the various emerging open source platforms. However, there is still a great heterogeneity.
The math of heterogeneity
Imagine for a moment: you are starting with a new business, and you are responsible for mounting a data platform from scratch. Besides interesting questions of recruitment and business goals, you have several technology platform questions. With tradeoffs particular to each area:
- Visualization. What complexity and volume for the data you want to visualize? Do your end users need to be able to easily create their own visualization? Are the visualizations intended to be integrated into other applications?
- Slicing/Dicing. How are you going to query queries to aggregate them, browse within, generate results? Are you more into a philosophy of browsing and looking for information, or a philosophy of Business Intelligence cubes?
- Statistics and Data Mining. How will you perform statistics on the data? Are there any needs to search for complex patterns in the data? Will these searches be by developers or by business profiles instead?
- Instant Access. Will you need to integrate the data into production applications with the need to very quickly access some data line by line, cell by cell?
- Storage and mass calculation. What is the total data volume to be stored? Do you need distributed mass storage or to set up a computing cluster? Would you like to follow a "File System" paradigm or "Relational Database" paradigm ?
- Real-time computing. Do you need a system that responds in real time? is it only a matter real-time visualization? or action? or adaptation?
- Automatic learning. Would you like to develop predictive systems using machine learning? With what volume and what kinds of data? Is the associated modeling intended to be carried out by technical profiles, business profiles, or both?
- Transformation and Integration. What are the source and destination systems for data integration?
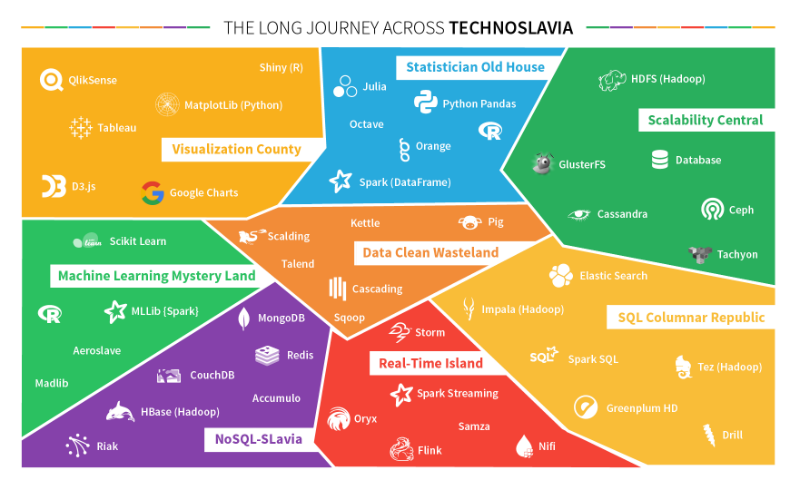
We thus come to eight technical areas. For each of them, there are a number of attractive technologies for taking advantage of them
For the purpose of this exercise, we will limit our list to the most well-known solutions, accessible free of charge (at least partly)
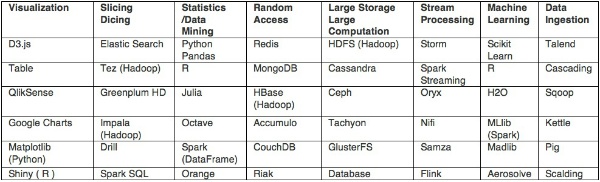
The Technoslavia math is easy to do. By multiplying the possibilities, we have not 6 x 8 = 48, but rather 6 to the 8th power = 1,679,616 possible architectures!
If 1,000 companies tested each combination in parallel, one by one, at a rate of 1 evaluation per day, it would take about five years to test them all.
Many of the technologies mentioned in the table above are less than 5 years old, and in 5 years, a number of them will be outdated. In short, the Big Data architect of today should reread the myth of Sisyphus, and be satisfied with continual trials and self-reinvention.
"This universe, henceforth without a master, seems to him to be neither sterile nor fertile. Each grain of this stone, each mineral brilliance of this mountain full of night, forms a world, for him alone. The struggle itself toward the heights is enough to fill a man's heart. We must imagine Sisyphus happy. "
(Note that "We must imagine Sisyphus happy" is a notion that Albert Camus borrows from Baron Kuki Shuzo, Japanese philosopher, student of Heidelberg and contemporary of Bergson)
A few typical architectures
However, there are not so many possibilities as that. A few typical architectures are possible:
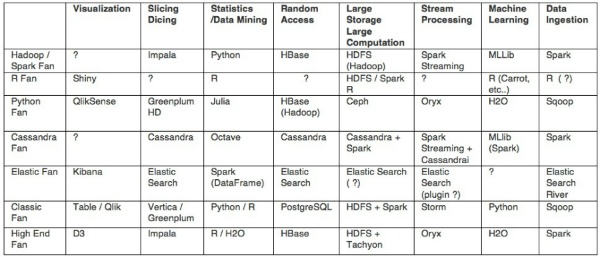
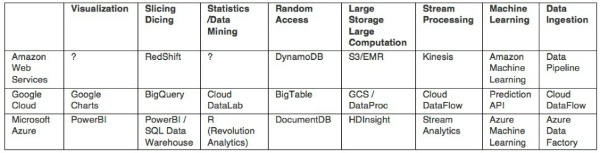
Alongside these solutions, cloud platform providers (AWS, Google Cloud, Azure) are also launching their own platforms, seeking to provide integrated platforms from start to finish. For this, they provide products for each area:
The republics or the Empire?
A time of similar heterogeneity marked the early 80s for data storage technologies. From this, emerged the paradigm of the relational database and the SQL language that unified it all.
What is the future in the world of data: unified by a single language and the victory of one player over the others? Will the multiple republics of data will soon give birth to a new Empire?
Several points leave room for doubt. The current Big Data ecosystem is very different indeed from the "Data" ecosystem of the 80s:
- Large Cloud platforms provide their own integrated technologies. By developing their own integrated technologies, they create attractive alternatives (which must be able to connect to one another) and which prevents the development of a single solution.
- Hadoop distributions. The major Hadoop distribution vendors want to provide their own solutions in their great battle for supremacy.
- The diversity of user profiles. Different profiles collide with one another in the world of Data. Biologists with a penchant for statistics come up against marketers seeking the formula for growth, and the open source developer. Each comes with his/her culture, each with his/her favorite way of thinking.
- Virtualization of resources and calculations is still a changing world. Nowadays, there are 4 possible granularity levels for managing one's resources (Physical Machine, Virtual Machine, Docker Container, Yarn Application, etc.) with no consensus as to who will win.
- The best technologies are continuously evolving. One feature of the previous years is a continuous development of technologies, which means the "best" technologies have changed almost every year for the last five years.
- Revolutions have yet to come to uses. In the end, it will be a matter of automating the decisions of connected smart objects. The technology is still in its infancy!
This is why we at Dataiku believe that Technoslavia is built to last! And, indeed, that's why we have created Data Science Studio.
In their furious crossing of Technoslavia, Data teams need a reassuring guide, a tool, always on the frontier with the latest technologies, but which allows all profiles to quickly seize it.
It's an endless battle, but it's one we will take up!
