




{kind=link}
The versatility of large language models (or LLMs for short) gives them the potential to revolutionize the way you do business, but to fully capitalize on their value you need to know how to adapt generic LLMs to your domain & use case, as well as effectively combine them with other purpose-built models and tools. In this blog, we’ll cover some important considerations and provide a framework with four levels of increasing complexity for customizing an LLM’s behavior.
For each level, we’ll delve into the technical methods you’ll likely apply and how Dataiku makes these techniques accessible to more people. In the end, regardless of what complexity level or methods you choose, you’ll discover how Dataiku facilitates the end-to-end creation of LLM-powered data applications for your unique needs, from design to delivery.
Level 1: Integrate LLMs With Pre-Built Components
The first level may be easier than you think: Simply harness the power of LLMs right out of the box to simplify and supercharge your text applications! Dataiku simplifies this process with intuitive, visual components to integrate LLMs, whether private models or third-party services, and infuse AI-generated metadata into your existing pipelines. From automatic document classification or summarization, to instantly answering multiple questions about your data across a variety of languages, Dataiku provides teams with unprecedented transparency, scalability, and cost control over their LLM queries … all without users needing to know how to code.
Level 2: Master the Art of Prompt Engineering
What if your task is more specialized and you need to provide additional context or instructions to bridge the gap between an LLM’s natural outputs and your specific task? To elevate your LLM's acumen, the next best strategy is to craft more tailored prompts. With Dataiku's Prompt Studios, you can design, compare, and evaluate prompts across models and providers to identify & operationalize the best context for achieving your business goals.
Learn more about Prompt Studios in Dataiku
Prompt Studios provide an easy-to-use interface, with sections where you can:
- Create prompt templates for better standardization and reusability.
- Choose models you want to explore and compare results between.
- Explain your task in plain language (any language!).
- Add examples of inputs and the expected outputs for few-shot modeling.
- Test your prompt against real data to see how it performs.
- Validate compliance against common standards — no more worrying about valid json.
Dataiku's Prompt Studios also provide caching benefits and cost estimates, empowering you to make trade-off decisions between cost and performance and gauge the financial impact of embedding Generative AI into your pipelines during the design phase (rather than getting a large bill after the fact!).
Ready for some good news? Using just the LLM approaches discussed in these first two levels, a huge number of tedious, time-consuming tasks performed manually by your knowledge workers today can be automated. These types of “efficiency” use cases are essentially low-hanging fruit for you to tackle first while learning the LLM ropes, and solving them will free up precious time for your skilled workers that they can redirect towards higher-value activities.
Level 3: Add Your Internal Knowledge
So then, what are some situations where we might need to level up to more advanced methods?
- If you want to retrieve answers from your own proprietary knowledge bank to ensure accurate, up-to-date responses and mitigate the risk of hallucinations,
- The volume of specialized background knowledge you’d need to provide as context is too large to fit in the model’s allowable context window,
- Or you want to add a layer of logic that produces on-the-fly data visualizations to help users explore the answers and derive insights.
Here’s where the third level of complexity comes into play.
To give some practical examples, it’s likely that knowledge workers like your customer service reps, technical support agents, or legal analysts often need to look up facts from policy manuals, case law, and other such reference material to answer questions. In some cases, the answers may be sourced from internal documents or require a citation of where the answer came from for compliance purposes.
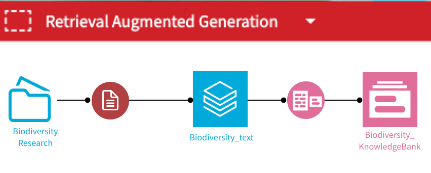
One method that enables this type of application is called Retrieval Augmented Generation (RAG). This technique encodes textual information into numeric format and stores it as embeddings in a vector store, either in a file index or database. In turn, this vectorized knowledge base enables efficient semantic search over your document collection, so you can quickly and accurately locate the right information for Question & Answer type applications.
In Dataiku, we make Retrieval Augmented Generation easy by providing visual components that:
- Create a vector store based on your documents,
- Execute a semantic search to retrieve the most relevant pieces of knowledge,
- Orchestrate the query to the LLM with the enriched context,
- And even handle the web application your knowledge workers will interact with, so you don’t need to develop a custom front-end or chatbot.
Level 4: Advanced Techniques
Finally, let’s touch briefly on the most sophisticated (and challenging) level of LLM customization. For even more customization, you can incorporate external tools with an approach referred to as “LLM agents,” orchestrate the underlying logic of these retrieve-then-read pipelines with LangChain (a powerful Python and Javascript toolkit), or use the ReAct method for complex reasoning and action-based tasks. To learn more about these methods, check out our “Introduction to Large Language Models With Dataiku” starter kit.
This level also includes advanced techniques such as supervised fine-tuning, pretraining, or reinforcement learning to adjust the inner workings of a foundational model so that it can better accomplish certain tasks, be more suited for a given domain, or align with instructions more closely. We won’t go into the details of fine-tuning here, but be aware that these approaches typically require copious amounts of high-quality training data and a significant investment in compute infrastructure.
Choose Your Own Adventure
Although Dataiku’s framework is equipped to help you explore these highly sophisticated forms of LLM customization, remember that these advanced techniques are only needed in a minority of cases with nuanced language, and that the techniques presented in the previous three levels are generally sufficient for molding the behavior of an LLM!
As a final thought: If you’re dissatisfied by the performance achieved by prompting and augmenting off-the-shelf models, it might be wise to explore the latest evolutions in prompt design (chain of thought, etc.), or even press pause on your plans to fine-tune an existing model. Advancements are coming fast & thick these days, so more capable models are likely to arrive in a short enough time frame to render heavy investments now in fine-tuning a waste of time and resources.
To learn even more about how Dataiku can help you build effective LLM applications to take your business to the next level, check out our LLM Starter Kit.