





Large language models (LLMs) are the technology behind popular products including OpenAI’s ChatGPT, Microsoft’s Bing, and Google’s Bard. Yet reports of employees leaking sensitive company data to ChatGPT raises major questions around properly leveraging LLMs in an enterprise setting.
Using the technology behind ChatGPT in the enterprise (beyond the simple web interface provided by these products) can be done in one of two ways. And each approach has advantages and drawbacks that we’ll explore in this blog post.

Option 1: Leveraging LLM APIs
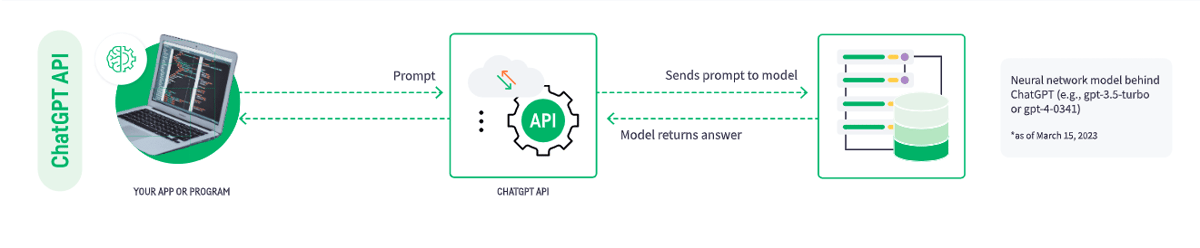
The first way to use LLMs in an enterprise context is to make an API call to a model provided as a service. For example, the GPT-3 models provided by OpenAI (including the gpt-3.5-turbo or gpt-4-0314 models that powers ChatGPT).
In addition to OpenAI, many large cloud computing companies provide these services. This includes Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
Making an API call requires setting up a small software program, or a script. This script connects to the API and sends a properly formatted request. The API submits the request to the model, which will then provides the response back to the API. The API then sends that response back to the original requester.
 Advantages of Using a Large Language Model-as-a-Service via API
Advantages of Using a Large Language Model-as-a-Service via API
This approach has several advantages, including:
- Low barrier to entry: Calling an API is a simple task. It can be done by a junior developer in a matter of minutes.
- More sophisticated models: The models behind the API are often the largest and most sophisticated versions available. This means that they can provide more sophisticated and accurate responses on a wider range of topics than smaller, simpler models.
- Fast responses: Generally, these models can provide relatively quick responses (on the order of seconds) allowing for real-time use.
Limitations of Using a Large Language Model-as-a-Service via API
The use of public models via API, as we saw above, is convenient and powerful. However, it may also be inappropriate for certain enterprise applications due to the following limitations:
- Data residency and privacy: Public APIs require query content to be sent to the servers of the API service. In some cases, the content of the query may be retained and used for further development of the model. Enterprises should be careful to check if this architecture respects their data residency and privacy obligations for a given use case.
- Potentially higher cost: Most of the public APIs are paid services. The user is charged based on the number of queries and the quantity of text submitted.
- Dependency: The provider of an API can choose to stop the service at any time. Enterprises should weigh the risk of building a dependency on such a service and ensure that they are comfortable with it.
Option 2: Running an Open-Source Model in a Managed Environment
The second option is downloading and running an open-source model in an environment that you manage. Platforms like Hugging Face aggregate a wide range of such models.
Given the drawbacks of using a public model via API, this option could make sense for certain companies or use cases. These models can be run on servers that an enterprise owns or in a cloud environment that the enterprise manages.
Advantages of Self Managing an Open-Source Model
This approach has multiple interesting advantages, including:
- Wide range of choice: There are many open-source models available, each of which presents its own strengths and weaknesses. Companies can choose the model that best suits their needs. That said, doing so requires some familiarity with the technology and how to interpret those tradeoffs.
- Potentially lower cost: In some cases, running a smaller model that is more limited in its application makes sense. It can provide the right performance for a specific use case at much lower cost.
- Independence: By running and maintaining open-source models themselves, organizations are not dependent on a third-party API service.
Tradeoffs to Self Managing an Open-Source Model
There are many advantages to using an open-source model. However, it may not be the appropriate choice for every organization or every use case for the following reasons:
- Complexity: Setting up and maintaining a LLM requires a high degree of data science and engineering expertise. We're talking beyond that required for simpler machine learning models. Organizations should evaluate if they have sufficient expertise. And more important, if those experts have the necessary time to set up and maintain the model in the long run.
- Narrower performance: The very large models provided via public APIs are astonishing in the breadth of topics that they can cover. Models provided by the open-source community are generally smaller and more focused in their application.
Become AI-Powered With Dataiku
Our core vision has always been to allow enterprises to quickly integrate the latest technology. This philosophy continues with LLMs.
Dataiku supports both approaches for using LLMs in the enterprise. The end-to-end platform also provides the broader framework necessary for using LLMs. This includes data connectors, data preparation capabilities, automation, and governance features.
Dataiku provides a direct interface with the popular OpenAI text completion APIs, including the powerful GPT-3 family of models. Check out a use case for using Dataiku and GPT-3 to query documents.
In addition, Dataiku provides additional deep learning and natural language processing (NLP) capabilities. These are built on LLMs to assist in building machine learning models using natural language text as an input. For example, sentence embedding allows text variables to be converted to numerical values. These values can then be easily used in the visual machine learning interface for classification and regression tasks.