




The Atacama Large Millimeter/submillimeter Array (ALMA) is the largest astronomical project in existence, with its revolutionary radio telescope studying the oldest and coldest objects in the universe from a high altitude plateau in Chile. Processing the complex and enormous amount of data they receive from their high precision antennas is challenging and, since 2017, the nonprofit has collaborated with Dataiku to optimize its operations — lowering the hours needed to keep everything working as expected to focus on improving the quality of astronomical observations. Their pioneering organizational transformation was even recognized in the 2021 edition of the Dataiku Frontrunner Awards.

So when Dataiku wanted to provide analysts with an opportunity to grow their skills, it was natural for us to turn to ALMA. This turned into an exciting challenge that brought together volunteer data science practitioners from a variety of backgrounds, who came together to look at the stars and contribute to a good cause. Continue reading to learn more about the highlights of the challenge, and discover our recommendations for fostering volunteer collaboration to advance fascinating data projects!
The Evolution of the ALMA Challenge
Following an observation at ALMA, a compute-intensive and long data reduction process starts to produce the final image. However, the instruments used to perform the observation are not free from sporadic problems and bugs, and elements such as weather conditions can also negatively affect the data acquisition process.
What happens if these problems are not detected before the data reduction starts? A significant amount of processing resources are wasted, and the observation might not be repeated if the object is no longer in the same position in the sky or the required conditions are never met again.
To minimize the probability of this occurrence, a first quality check named Quality Assurance Level 0 (QA0) is performed before the data is processed. This check leverages huge amounts of metadata, which can be analyzed just a few minutes after the observation is done. Most of the process is currently handled manually by an astronomer, who analyzes the metadata with certain criteria to determine its QA0 status: Pass, Semipass, or Fail.
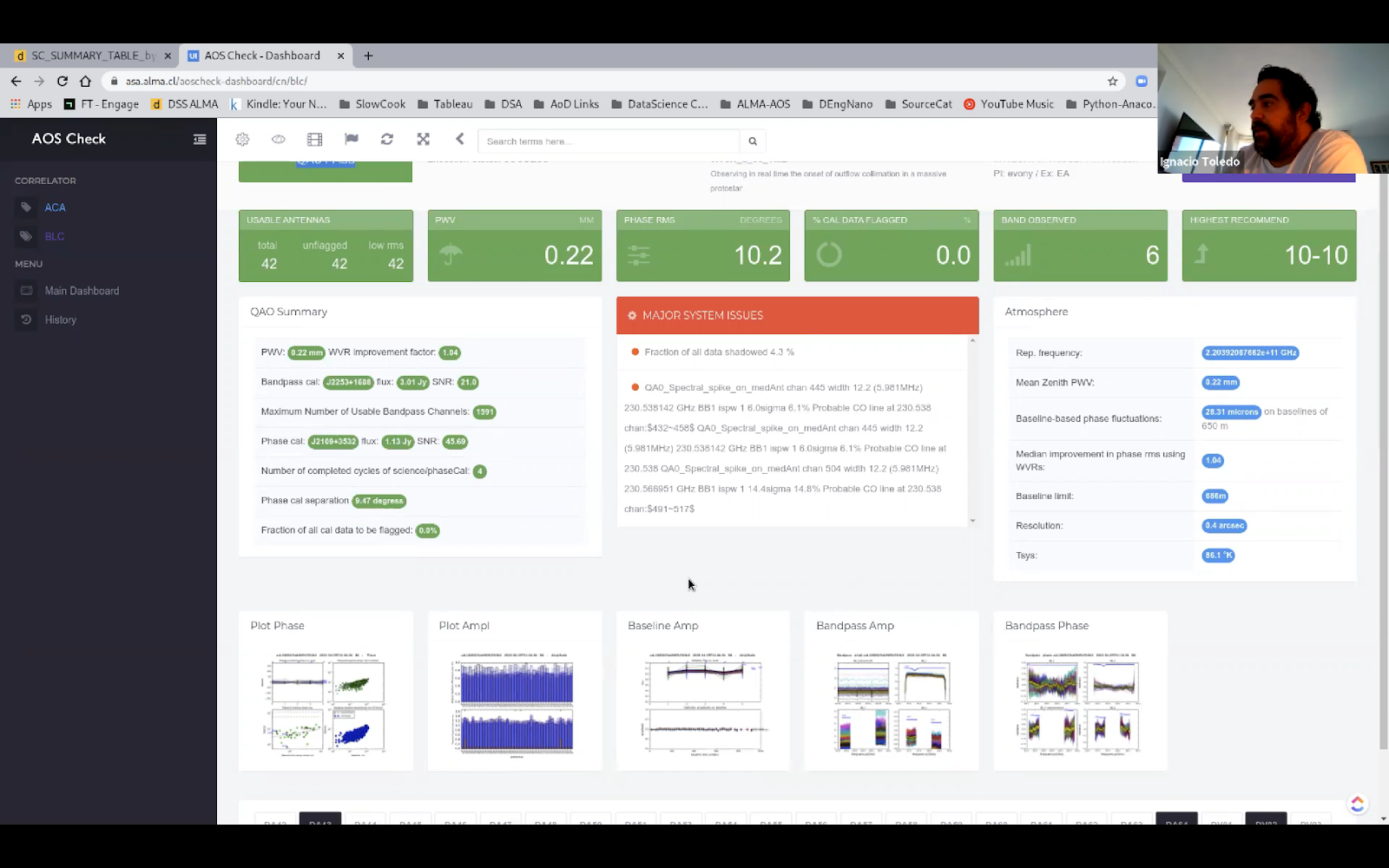
One of the interfaces used by the astronomer on duty to determine QA0 status
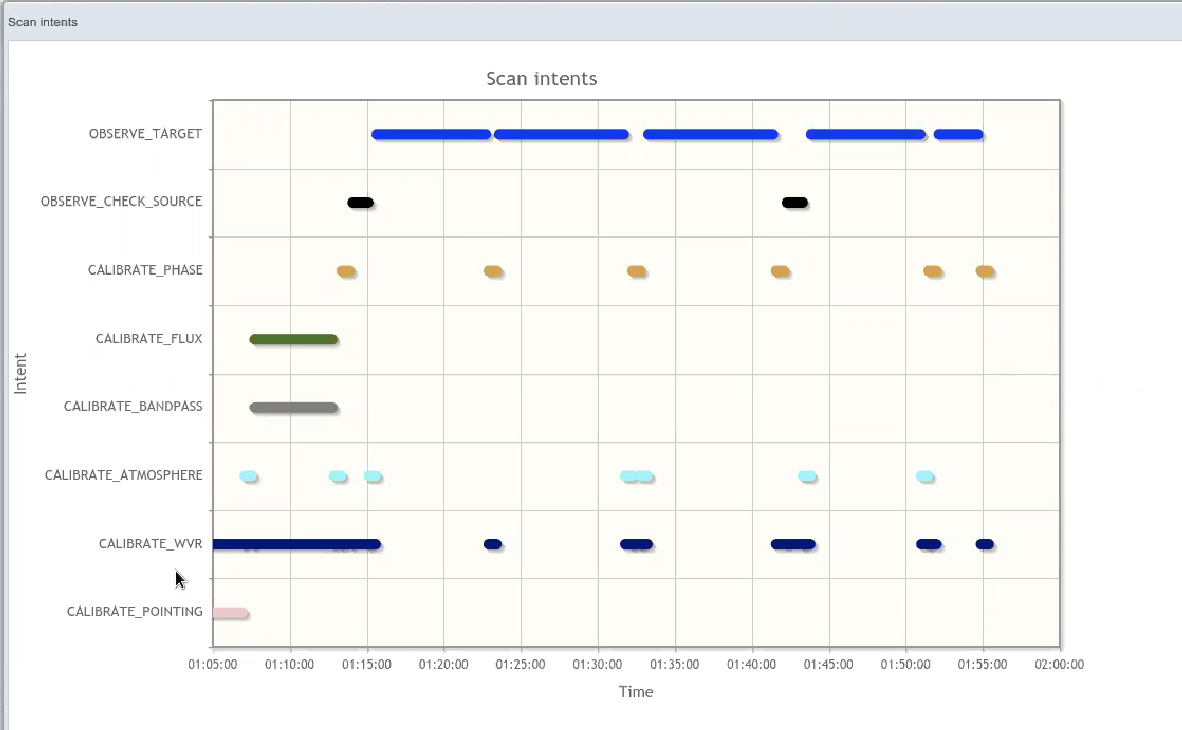
Example of metadata available per observation (OBSERVE_TARGET being the timing of the observation)
Together with the Dataiku Community, ALMA presented the following challenge: Leverage data science to automatize the QA0 decision, so that it can be made in the minimum time possible and more resources can be made available to produce useful observations.
As a pilot, this project was exclusively offered to Dataiku super users, the Dataiku Neurons, and those who had completed certifications on Dataiku Academy. Fourteen users from around the world accepted the challenge. Their diverse range of profiles were complemented by the participation of Dataiku data scientists and ALMA observatory staff members.
Dataiku was leveraged as an accessible data science platform to enable participants to experiment and build upon each other’s work. Data Scientist Darien Mitchell-Tontar, who supported the project, noted: “I was impressed with the participant's fluency with Dataiku, but it was also fun observing their diligence, creativity, and genuine curiosity around the use case. All of the participants had a ‘full-time life’ outside of this challenge and I was truly inspired by their effort.”
The challenge naturally evolved over time to fit the schedules and interests of its participants, and became what it set out to be: a learning experience for everyone involved. All the new viewpoints were also greatly beneficial to the observatory.
“This project provided ALMA with a fresh perspective to improve on a key component of astronomical observations. We’re very thankful for the work accomplished by volunteers — not only are the insights useful for our day-to-day operations, but they also provide new ideas for future developments in the quality assessment process, and showed us the potential of applying ML and more advanced analytical tools to detect possible failures in advance,” says Ignacio Toledo, Data Analyst at ALMA, who initiated the project and guided participants through its completion.
Results, Reflections, & Celebrating Success
Outlier Detection
Participants were first tasked with exploratory data analysis, with the goal of identifying outliers — that is, determining what results in a “bad observation” in order to flag it in the system.
Pauline van Nies, Data Scientist at Ordina NL, found that, unlike previous assumptions, not all antennas were behaving in the same way. This key finding prompted further data analysis on single antennas rather than on the assembly. Her contribution to the project was multifaceted:
“Combining ideas from Jordan [Blair, Solutions Engineer at SLB] and Giuseppe [Naldi, Software Architect at ICTeam], I performed an outlier detection and a changepoint algorithm using Python on a dataset of 17.5 million records. To visualize the results of the analysis, I created a Dash/Plotly webapp that can support the engineers of ALMA to investigate the historical antenna behavior and its changes, which can be applied in a predictive maintenance use case.”
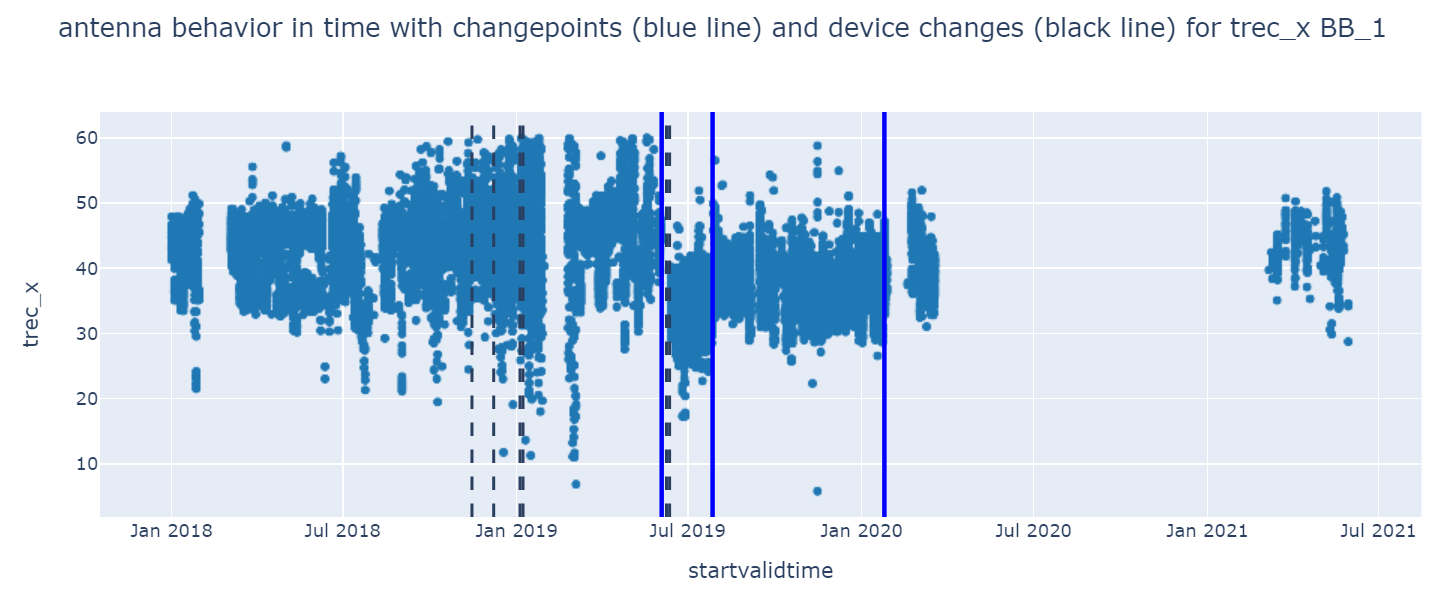
Chart showing the automatic detection of variations in the temperature of a component in one antenna, using the change point algorithm
To further anomaly detection, Giuseppe leveraged statistical methods and introduced participants to different machine learning algorithms, with outstanding results: “I think that my main contribution to the project has been to suggest the application of a changepoint detection algorithm to the analysis of the time series. I had found such analysis useful in other contexts (e.g., anomaly detection or predictive maintenance) so I did believe it could have been useful also in this specific context.”
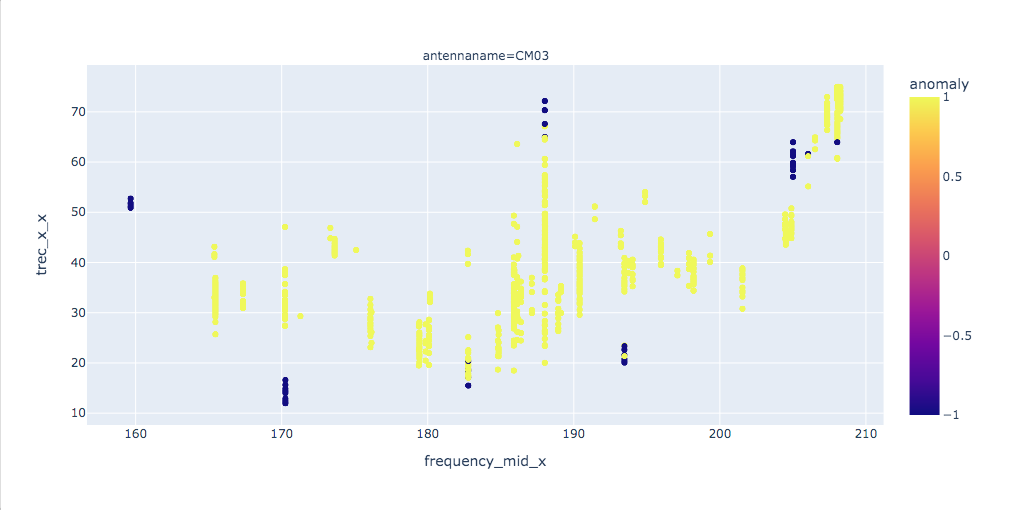
Chart showing anomaly detection using an isolation forest algorithm
Webapp Visualization
Dataiku Data Scientist Niklas Muennighoff volunteered his time to the challenge to build a visual representation of the insights discovered by participants, through the creation of a web application (webapp) enabling the astronomer on duty to analyze an individual observation for quality assurance.
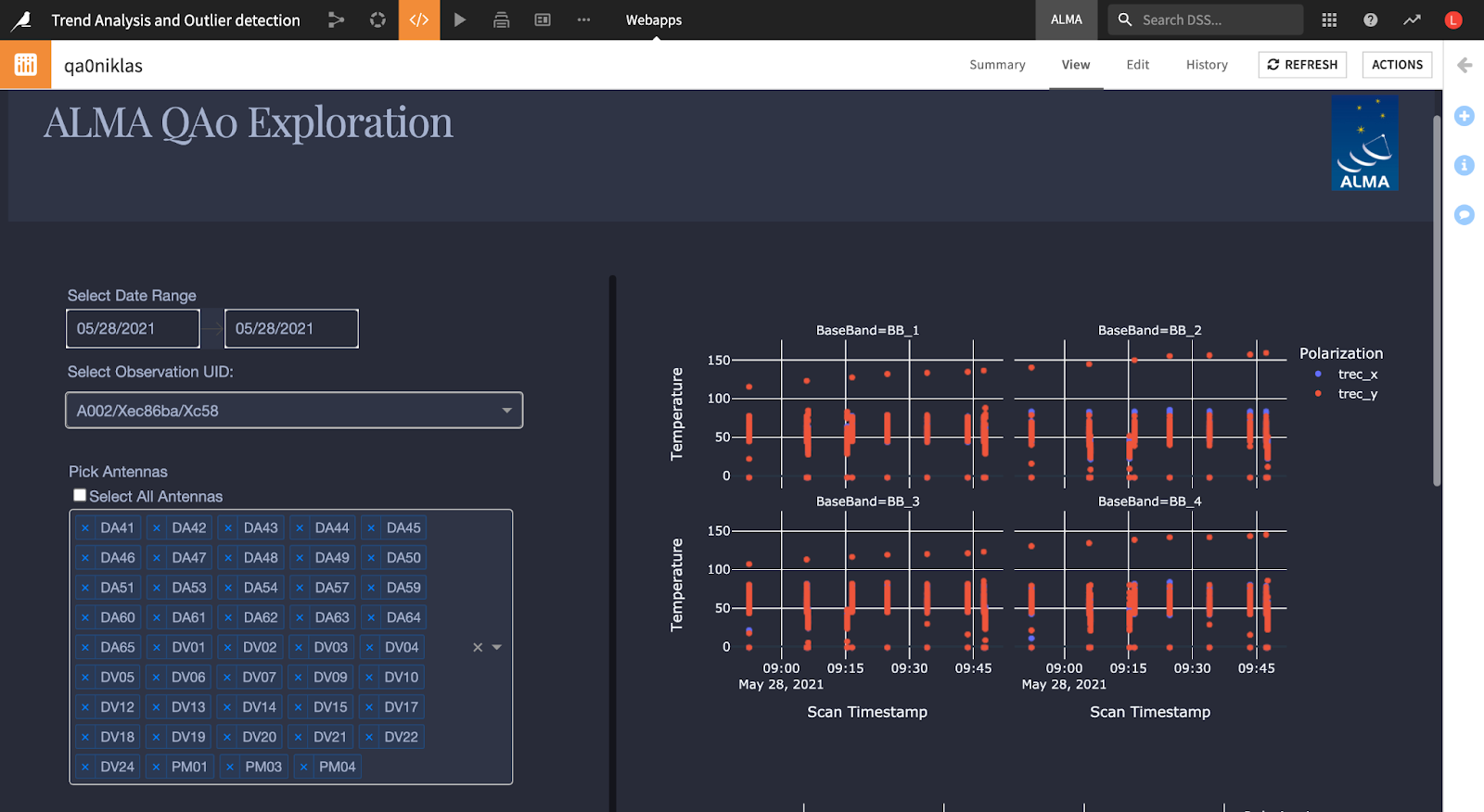
{kind=link}
Webapp demonstration
“I built a webapp for visualizing and interacting with observation data from ALMA. The webapp allows users to look at an observation in aggregate or drill down to the level of single antennas, basebands, temperatures, frequencies, and other parameters. It makes use of a combination of SQL, Python (Pandas, Dash), and CSS,” says Niklas. “Thanks to the work of Ignacio [Toledo], the webapp has been deployed at ALMA. Via Dataiku Scenarios, it automatically pulls the latest observation data so astronomers can perform the QA0 check within three minutes of the observation.”
Final Thoughts
As it was the Dataiku Community’s first time organizing a volunteer data science challenge, receiving feedback from participants was vital to keep in mind when planning future projects. A final meeting allowed participants to reflect and share key takeaways, with multiple contributors praising the chance to volunteer for a good cause, the opportunity to learn more about ALMA processes and use interesting data sets, and collaborating and learning together.
When asked if they’d participate in another challenge, the answer was an unanimous “Yes!”
Get Started With Your Own Volunteer Data Science Challenge
Inspired to launch your own initiative to leverage data science for good? We’ve taken the lessons learned from our first hands-on challenge to provide you with a set of best practices!
1. Use Accessible Yet Interesting Data
While the datasets provided by the observatory staff at ALMA were undoubtedly compelling, they were also complex and necessitated more time than expected for our volunteers to engage.
“The level of complexity of the challenge was really high. We had to understand the data itself, how the telescope works, and we had to rely a lot on Ignacio [Toledo]'s knowledge to move on,” says Matthieu Scordia, Lead Data Scientist at Dataiku, who provided support to volunteers. “In the end, all participants seemed really happy to have learned things from a new field.”
To facilitate participation, we recommend prioritizing data that is both interesting and accessible to analysts and data scientists from different backgrounds.
2. Create Opportunities for Connections
Above all, the ALMA challenge was an enriching collaboration in which we learned from each other to develop our Dataiku and data science skills. While weekly check-in calls were set up to assess progress and plan the next steps, participants reported they would also have benefited from common working sessions to better collaborate with fellow volunteers.
Although it can be tricky to manage across time zones, creating more opportunities for real-time connection is key for quicker progress, for instance when digging into the data. It also helps keep up the collaborative learning spirit!
“The highlights were the weekly meetings, wherein we had stimulating discussions and where the astronomers of ALMA (Ignacio Toledo) explained not only about the data but also gave us unique insights in the daily operations and processes concerning the telescopes and their measurements. I likewise appreciated that we learned from the Dataiku experts on webapps (Darien Mitchell-Tontar and Niklas Muennighoff) and dealing with large datasets (Matthieu Scordia). The opportunity to present our results in front of an audience of astronomers and engineers during an online meeting at ALMA was a rewarding closure.” Pauline van Nies, Data Scientist at Ordina NL
3. Set Up Clear Objectives
Clear objectives should be set at the beginning of any challenge, accompanied by a roadmap that plots out the process and gives participants something to look forward to. While we began the ALMA challenge with the objective of finding out if data science could be used to automatize the QA0 decision, it evolved over the course of time in line with the availability of contributors.
To ensure that both long- and short-term contributors can stay involved and work together to meet common objectives, we would also advise dividing the workload and setting up smaller subgoals or micro-objectives.
4. Document Progress
When running a volunteer data science challenge, it’s vital to keep in mind that participants are volunteering their time — and may not necessarily have a lot of it. We suggest regularly documenting progress so that everyone involved can easily catch up on the work done so far, and make their proper contributions when their schedule permits.
5. Tailor Tasks to Participants
Every participant goes into a challenge with their own set of expertise and interests. This should be kept in mind when organizing, so that everyone can play to their strengths, while also still having the opportunity to learn new things.
Tom Brown, a data analyst and Dataiku Neuron who has both participated in and organized volunteer data science challenges, shares his thoughts on the learning curve: “Part of the reason I participate in such challenges is to learn and grow. It is making contact with others who are welcoming but know more than I do that made this valuable for me. And the opportunity to do this over an extended time period increased learning.”
6. Celebrate Success and Share Findings
After all the hard work that goes into running a successful volunteer data science challenge, it’s important to take the time to celebrate your collaborative success and share your findings. We had the chance to wrap up the challenge by presenting our insights to the ALMA staff directly, who were impressed with the results and grateful for the help provided by volunteers. This is the best recognition we could have hoped for!