




{kind=link}
As explained by Romain Fouache (Dataiku CRO) here, solving data cleansing in a central team can cause some pretty negative outcomes.
Data management encompasses activities relative to data, including data cleansing. More than "death" as Romain mentioned, its practice generally suffers from a lack of knowledge sharing. The symptoms are:
- Data engineers black market: skilled data engineers are like unicorns– rare but magic elements solving data issues.
-
Documentation is a taboo word: it is quite impossible to find up to date information about data products that have been built and could be reused.
- Communication issue: when a data engineer considers a dataset as high quality and the data analyst is complaining about its poor quality. It ends up in frustration on both sides
Forrester has identified the same symptoms in organizations trying to achieve their key business outcomes from machine learning and call it data silos.
I am sure it rings a bell to data engineers, data analysts, data scientists, and their managers. The result is that data teams are struggling with their deliveries and cannot scale to absorb the growing number of demands. The good news is that a treatment exists and small adjustments can have huge impacts.
Set Up a Virtuous Circle
Scaling up data and AI efforts requires organizations to set up data management in a virtuous circle, like in the image below:
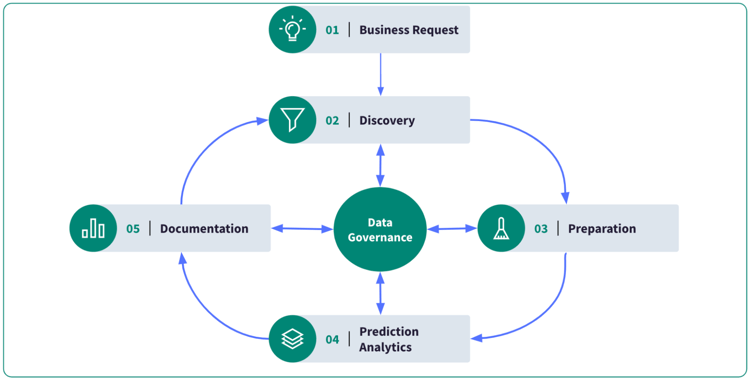
1. Business Request: A business team has expressed requirements for new analytics or predictions to support a decision process.
2. Discovery: During the discovery phase, teams work to identify and collect the data that is relevant to the requirements. This may involve reusing some assets already built for a previous request and/or gathering data from a variety of sources, such as databases, spreadsheets, or online platforms.
3. Preparation: Once the data has been collected, it must be formatted to match the next step of the pipeline. This may involve joining, grouping, or windowing the data. It's also important to ensure that it is accurate and free of errors. This may involve checking for duplicate records, correcting spelling mistakes, or filling in missing values.
4. Prediction or Analytics: After the data has been curated, teams can begin to analyze it to gain insights and make informed decisions. This may involve creating reports, visualizations, or other tools to help make sense of the data. Teams can also begin to use the data for prediction. This may involve creating models and training them on top of the curated data.
5. Documentation: Finally, it's important to document the results of the data analysis with the appropriate stakeholders. This may involve enriching the data with information about the insights and recommendations that have been gleaned from the data. This phase is key to facilitate the discovery.
Data Governance, which you see in the image above is in the middle of the diagram and applies everywhere, turns all of this into a virtuous circle by providing oil to those gears and removing friction from one step to another. It also ensures the security of the data processed.
Win as a Team
That’s where it becomes a team sport, and everyone on the team has a role to play. Here are some ways that different team members can contribute to effective data management:
1. Data Engineers: Data owners are responsible for the day-to-day management of data within their domain. They collaborate with data analysts and scientists to find the best data for the business request.
2. Data Analysts or Data Scientists: They are the people who rely on the data to do their jobs. They are the ones who can identify if the data is good quality and troubleshoot when there is an issue in the content. For example, the data scientist is the one who can identify a data drift for his model. The collaboration with the data engineer is key to making sure the data pipeline delivers value.
3. Data Governance Team: this team is the facilitator of this collaboration as it provides the necessary tools and the policy to use it. For example, it provides the platform to publish the data products that have been generated to be reused but at the same time forces them to maintain the information about the data product.
By working together and following these phases, teams can effectively manage their data and use it to drive business success.
Dataiku: One Platform for All
Here is how Dataiku helps you implement a virtuous data management circle:
1. Discovery: Dataiku facilitates the discovery process of datasets and other assets generated through a generic catalog in which you can search for any items of your Dataiku instance. You can also organize the information using tags, folders, or even workspaces.
2. Preparation: Data preparation has a different meaning for a data steward, a data engineer, or a data scientist. Each of them has their view of the data and approaches for data quality and preparation. That’s why Dataiku provides a visual interface to non-coders and a development environment for coders. Both are hosted on the same platform which allow the combination of the best of the two worlds.
3. Analytics and Predictions: This domain would require an entire blog to cover, but the main idea is that analytics and predictions are part of the same flow and data pipeline which makes the link between the preparation easier to track and understand.
4. Documentation: Dataiku has a built-in wiki where you can document all the assets of your project. You can also create flow zones to easily read your flow and understand it.
Data Governance: Dataiku has been built around the concept of a project where all the users of the data journey collaborate to deliver value as a team. Having them all on the same page allows you to centrally define all the permissions related to data as well as define policies.
As a conclusion, making data management a team sport is a unique way to scale up data and AI projects.