




Wouldn’t it be great if data just came to you ready and primed for analysis? Unfortunately, as data often comes from different sources, with different definitions, and without standardization, it nearly always requires some modification to be useful for its target destination. Whether it’s being used as part of an Extract Transform Load process in data warehousing (or in some cases with modern cloud data stacks, ELT), for use in ML models, or simply ad hoc analysis, data transformation is a key part of nearly any project involving data.
What Is Data Transformation?
In basic terms, data transformation can be defined as the process of modifying data to make it usable for downstream application in tools, processes, and analysis. While steps can vary depending on the goals of your project and data needs, the process to transform data typically starts with a pre-check of understanding and cleansing the data and ends with reviewing changes with key stakeholders.
Step 1: Exploring and Validating Data
The goals of this stage are ultimately to understand key characteristics of your data and explore what changes might need to occur to data in order to meet your end purposes.
You should ask questions like: What is the ultimate goal for what I hope to achieve with this data? What are the different variables and how are they related? What does each variable mean and will it be useful? For example, in the case of transforming data for ML applications, text data might need to be transformed into numerical data, or ranges of values may need to be normalized.
You might also perform exploratory data analysis (EDA) prior to data transformation — in which you explore patterns and anomalies, test hypotheses, and check assumptions. In some cases, statistical analysis can help you understand relationships between variables so that you get a more complete picture of what data could have higher levels of importance.
Step 2: Mapping Data
Often you will need to join data from multiple sources into a single dataset. In this situation, you have to match data fields between datasets in preparation for joining them.
Step 3: Code Generation and Data Transformation Execution
This is when you actually transform data to meet the previously identified goals. First, code is generated either by hand or visually with some tools. Then, the code is executed and the transformation occurs.
There are many types of data transformation, including additive activities to enrich data with greater meaning such as deriving age from birthdate, subtractive activities that include deleting records or unnecessary fields, standardization or normalization to rescale data, and structural changes to the dataset itself.
Step 4: Validation and Review
In the end, after data transformation has occurred, the person doing the transformation validates that it meets the ultimate goals set forth in the initial stages of exploration. Finally, those involved in the downstream use of the data validate it meets their needs, such as business SMEs that will use the data to enrich a new business application. Often at this point revisions will need to be made and so the cycle begins in some form again.

How to Transform Data More Efficiently and Effectively With Dataiku
This process can be incredibly time consuming, especially when done manually. Data transformation can be even more of a hassle with several rounds of revision, and can be expensive with large datasets. Here’s how Dataiku can help at each stage of the process:
Exploring and Validating Data:
- With Dataiku’s visual flow, extensive documentation, and user activity tracking, you can quickly and easily see exactly what occurred to data before it got to you.
- Project wikis define business objectives and goals so that everyone on your team is on the same page.
- For EDA, Dataiku includes quick analysis where you can proactively identify errors, outliers, and get a summary of characteristics for each dataset by just clicking a menu item over a column. Built-in charting and statistical analysis enable you to quickly explore data relationships in a single tool. Dataiku also offers template notebooks for those that prefer to do EDA in code.
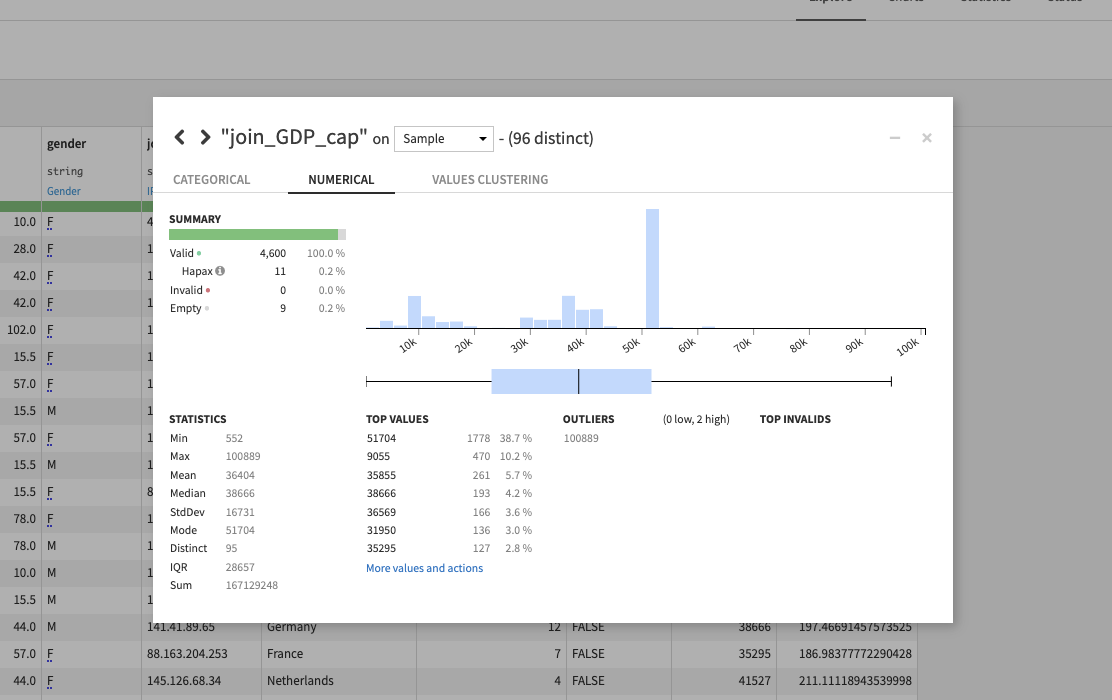
An example of quick analysis available for each column of data in Dataiku.
Mapping Data:
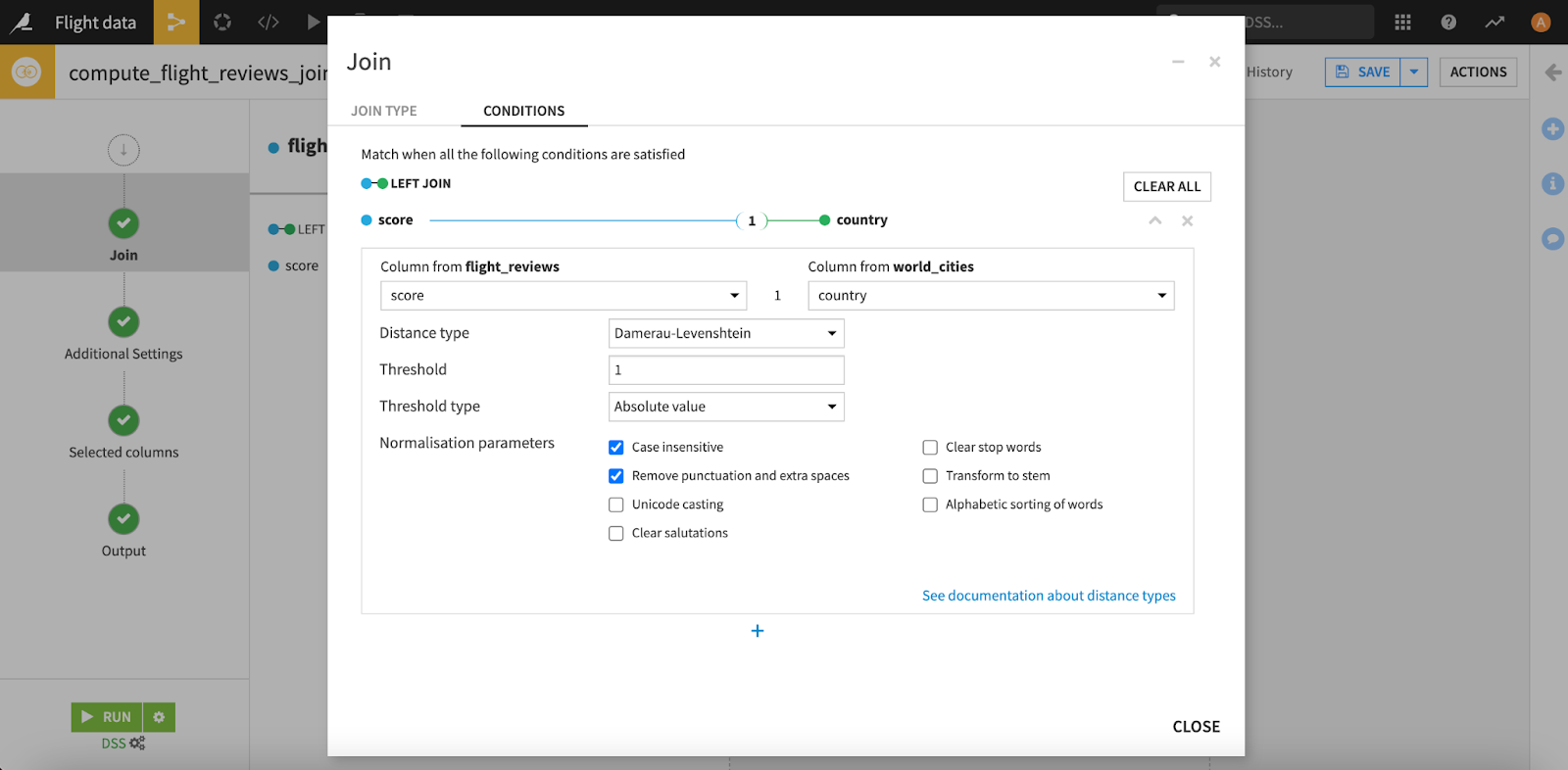
Dataiku features join recipes that make it easy to join datasets with no code required. Fuzzy joins are also possible so that you don’t have to cleanse data prior to joining datasets. Simply select the key, join type, and voila — your datasets will be joined.
{kind=link}
Dataiku allows you to join datasets via an easy to use visual fuzzy join recipe.
Code Generation and Data Transformation Execution:
- With over 90+ built-in visual data transformers — everything from deduplication, data derivation, and more — you can save time searching for the right transformation. Dataiku even provides previews of actions so that you can see what you’ll get before committing.
- Automation via scenarios for common data transformations to eliminate manual work altogether
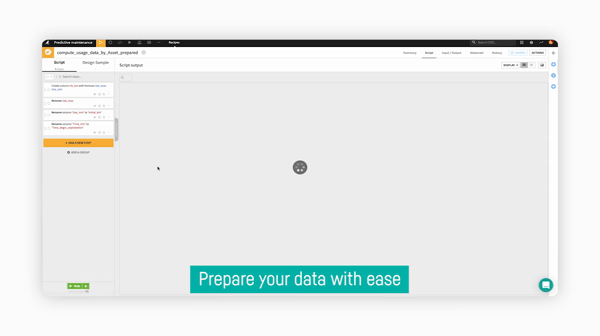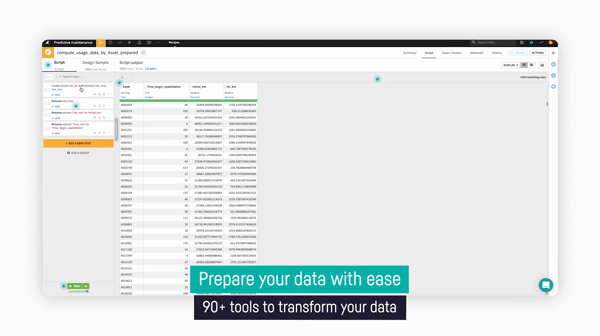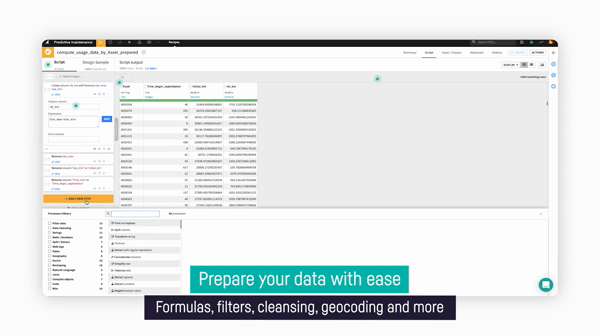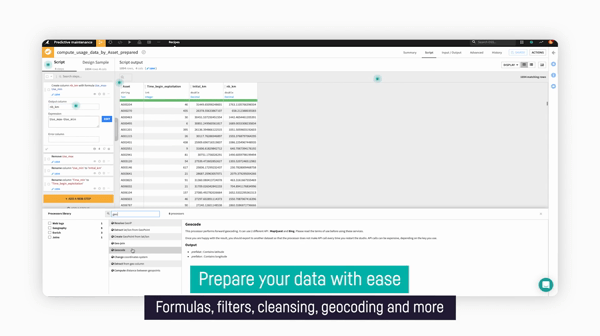
Data transformers in Dataiku make it easy to transform data with no code required.
Validation and Review:
The visual flow in Dataiku makes it easy to track everything that’s occurred to data in order to backtrack your work as well as explain data transformations to stakeholders.

Dataiku’s visual flow with tags by contributor illustrates each step applied to data.