




One key to more efficient, effective AI model and application development is executing workloads on compute platforms that offer high scalability, performance, and concurrency. Together, Dataiku and Snowflake deliver exactly that to data engineers, data scientists, and developers and now offer a full complement of integrations to improve AI, machine learning (ML), and data and analytic applications.
This blog addresses the many ways Dataiku and Snowflake partner to deliver an integrated solution for data science, including recent integrations with Snowpark for Python API and user defined functions (UDFs).
Dataiku and Snowpark for Python
Building on existing integrations, Dataiku and Snowflake have now delivered integration with Snowpark for Python for coders who like working in the language and IDE/notebook of their choice. Python programmers, now among the most numerous working in data science, can, inside a Dataiku notebook, use Snowpark to leverage their Python skills and execute SQL using Snowflake’s powerful processing engine.
Snowflake has always delivered performance and ease-of-use for users familiar with SQL. Now, Snowpark enables users comfortable with other languages such as Scala, Java, and Python to operate on data stored in Snowflake using a familiar DataFrame abstraction. The combination of Dataiku and Snowflake represents a best-of breed-integrated AI, ML, and analytics stack to build faster, scale AI, and deploy with speed and confidence.
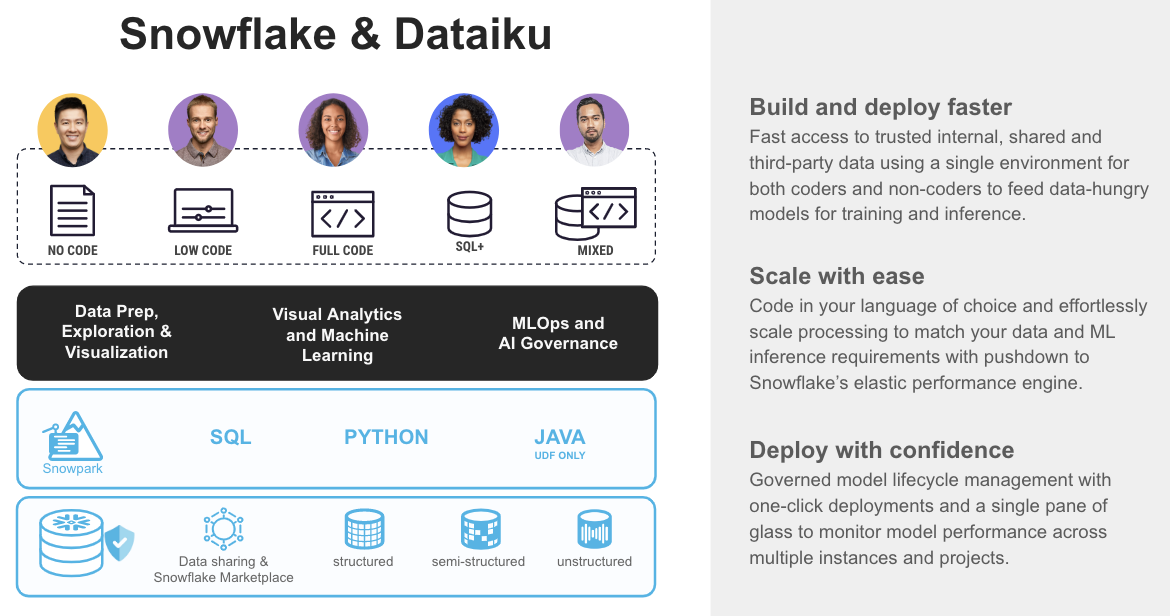
It’s a best of both worlds scenario for programmers who want to continue working in code and also collaborate with colleagues working in Dataiku’s visual no-code environment on Snowflake. Both can use the powerful compute and storage of Snowflake, but work in their preferred style and leverage different skill sets. Snowflake now also supports most of the popular Python ML frameworks like PyTorch and scikit-learn.
Using Dataiku with the Snowpark for Python API enables users to query and process data in a data pipeline and build data applications without having to move data out of Snowflake. Snowpark for Python uses DataFrames, virtualized views of the data that can be operated on. The corresponding SQL statements are executed in the Snowflake database. This approach removes the complexity associated with other processing engines like Spark.
Dataiku and Snowflake for Data Science
Investment by the two companies continues to make it easier for users to work in the tools of their choice, while also removing the burden and complexity of having to manage infrastructure.
Integration between Dataiku and Snowflake puts powerful transformation, data engineering, and development capabilities in the hands of users, so they can work more effectively and cost efficiently. They can also work more securely with integrated features for authorization, access, and authentication, such as Oauth.
Let’s take a quick look at the full breadth of capabilities Dataiku and Snowflake have delivered through the lens of a project, shown below as a Dataiku Flow, a visual grammar to represent datasets and recipes (data transformations) in a data science project.
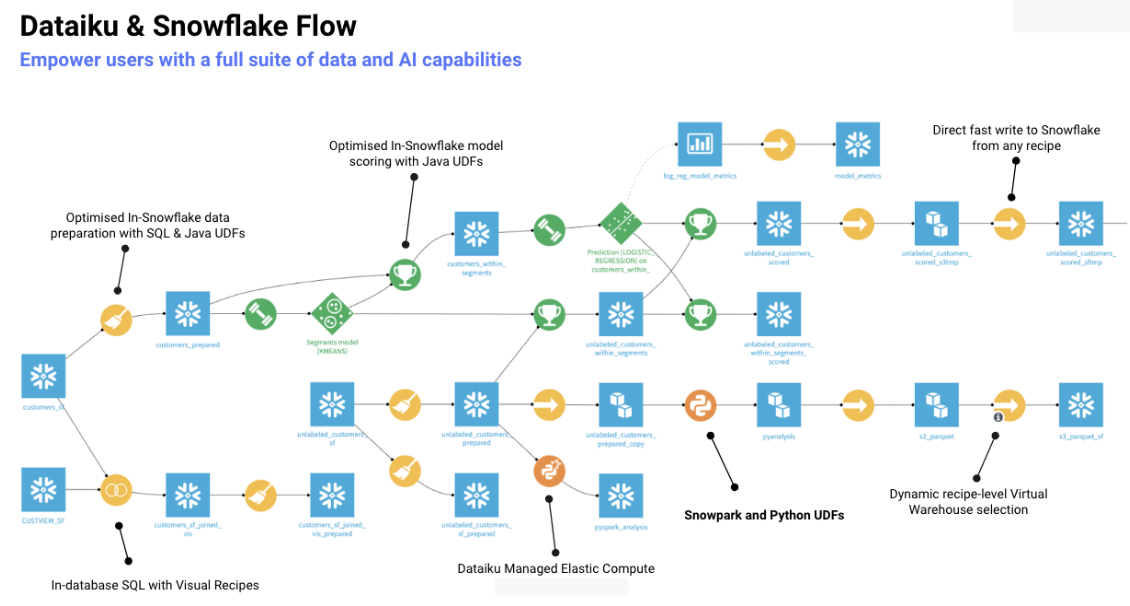
All of the Snowflake integrations shown above can be invoked directly in the Dataiku project via simple menus selections for ease of use and to remove complexity.
Beginning with bulk loading of datasets from cloud storage and SQL push down execution, which users have benefited from for years now, Dataiku last year added integration with Snowflake Java UDFs to enable push down of more workloads into Snowflake’s high-performance compute engine. Recently, Dataiku added the ability to push down using Snowflake’s Python UDFs and also added seamless integration to Snowpark, a framework for automating data engineering and compute workflows for AI, ML, and analytics.
These integrations enable data engineers, data scientists, and developers to work in familiar programming languages such as Scala, Java, and Python and then execute Dataiku workloads such as data transformation, data preparation, and feature engineering on Snowflake. Processing Dataiku’s visual recipes for data preparation tasks on Snowflake, users are able to leverage the powerful in-database SQL execution within Snowflake, enabling users to take advantage of Snowflake’s elastically scalable compute for any size of data transformation task.
Users can also leverage optimized in-database data preparation with Java UDFs. UDFs extend operations beyond those defined in the system to perform operations like manipulating data using Java UDFs and getting back results. With Java UDFs, customers can run functions they have in JVM (Java Virtual Machine) from Snowflake’s single, integrated platform. And customers can bring functions they have in JVM and execute right inside of Snowflake’s Data Cloud. With Snowflake’s powerful processing engine, users get better performance, scalability, and concurrency, greatly expanding the transformation capabilities.
Dataiku models can be scored in-Snowflake for batch scoring or scored using Dataiku’s elastic compute for scoring both batch and real-time models. And of course, Dataiku supports dynamic, recipe-level Snowflake Virtual Warehouse selection for massively parallel processing and direct fast-write to Snowflake for any data transformation. And the simplified architecture of the integrated solutions supports a complete, end-to-end AI, ML, and analytics platform.
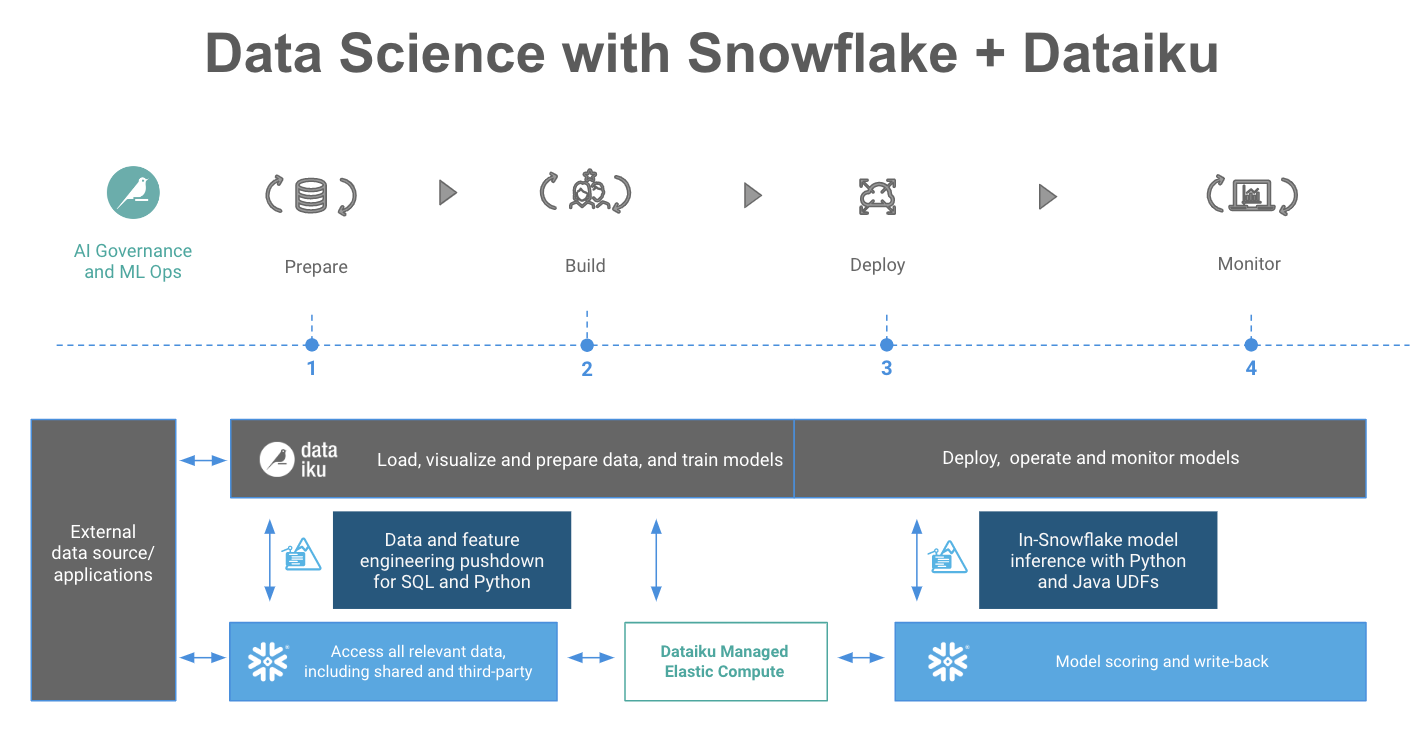
{kind=link}
Dataiku and Snowflake continue to invest for co-innovation in many other areas as well, including important areas like ML operations (MLOps) and key industry pillars such as retail/CPG, healthcare and life sciences, and financial services. Learn more about the partnership here.