




At Everyday AI New York last September, Dataiku CTO and co-founder Clément Stenac shared our vision for the LLM Mesh, a common backbone for Generative AI applications in the enterprise. We often reference five core benefits of the LLM Mesh, which enable organizations to efficiently build enterprise-grade applications while addressing concerns related to cost management, compliance, and technological dependencies.

Since we have already released a lot of helpful information around Retrieval-Augmented Generation (see this more technical article, this less technical one, and this video of RAG in Dataiku), this blog series will focus on the other groupings. To kick us off, we’re going to dive deep into the benefit of decoupling the application from the service layer. The TL;DR is that this decoupling makes it possible to design the best possible applications and then maintain them easily in production. Read on for the nitty gritty as to how this decoupling, ultimately, fosters long-term sustainability and reduces operational risk.
Let's Back Up; Why Decouple the Application From the Service Layer at All?
With the constant influx of new LLM providers, models, and vector databases these days, flexibility is key when rolling out Generative AI-powered solutions across an organization. By building in a future-proof manner from the get-go, teams can ensure that solutions can easily adapt to adopt the latest and greatest technologies. In fact, in our recent Forrester Opportunity Snapshot — a custom study conducted by Forrester Consulting on behalf of Dataiku — nearly half of the 220 AI decision makers agreed that the most important attribute when leveraging an external vendor for Generative AI implementation was flexibility and scalability.
Dataiku’s LLM Mesh provides an elegant solution to the flexibility challenge, not only reducing operational risk but also making it simpler for application developers to satisfy needs at various project stages, benchmark different options, ensure scalability, and take advantage of future technological innovations. Let’s zoom in on each of these topics:
1. Satisfy Needs at Various Project Stages
When it comes to an AI solution’s tech stack, agility and choice are important principles in both the design and production stages.
First, in the design phase, builders need to be able to efficiently test different models, as it is not always immediately clear which LLM is going to provide the best output for the requirements.
To give a real-world example, a good practice is to test the feasibility of a new use case by first starting with the most powerful model available in its class, such as GPT-4. If the results are successful (or at least initially acceptable), you know you have a viable use case you can pursue further. However, if the tests don’t yield the desired results and don’t improve with further prompt engineering, you automatically know that previous-generations or smaller versions of the model won’t work — in this case, trying a model more fine-tuned for your specific task or reframing the problem altogether is a better next step.
Later, once a solution is deployed, the team will need to maintain the ability to change the model without having to rebuild or refactor solutions. Overly-tight coupling or hard-coding to a certain provider can result in a situation where changes or updates in one part of the system trigger a cascade of updates and modifications across multiple layers, leading to a complex and error-prone environment rife with technical debt.
2. Benchmark Different Options
When testing different models and providers, teams need to balance tradeoffs in cost, security, performance, and speed. The ability to rapidly test various options and efficiently record and compare the results of each experiment is a huge productivity boost not only for the application developers, but also a benefit to downstream ML operators or AI Governance teams who may be asked to replicate or justify the selected methods.
In the example above, we mentioned starting with GPT-4 for preliminary validation of a use case. Whether in design or production, it’s a smart exercise to check if a smaller or less powerful model can also achieve satisfactory results while reducing costs or latency. With the initial GPT-4 benchmarks for performance, speed, and costs in hand, it’s easier to optimize the solution for these levers and calculate ROI.
We compared five different LLM models, something we couldn’t do without Dataiku, and found that one model continued to outperform the rest by a healthy margin for our specific use case. We realize that no single LLM is good for every use case.
-Dataiku Customer CHS Inc.
3. Ensure Scalability
Scalability is crucial as AI projects’ data volumes, computational demands, and complexities grow and evolve. For instance, when building a Q&A chatbot for your customers or employees, it may make sense to initially house your knowledge base (in the form of encoded textual information) in a local vector store such as FAISS or ChromaDB. Then later, as the solution is adopted and expanded, you may want to move to a more scalable commercial solution like PineCone if the quantity of documents processed becomes very large.
4. Take Advantage of Future Technological Innovations
Finally, in this fast-moving domain where the cutting edge seems to advance by leaps and bounds each week, it’s wise to keep your options open and avoid technology lock-in. One pitfall to avoid in particular: When developers hard-code technical dependencies into AI solutions, it becomes very challenging to introduce new features or swap out components without affecting the entire stack. This type of technical debt can slow down innovation and make it difficult to respond to changing business requirements.
How Does Dataiku Help?
With Dataiku’s LLM Mesh layer in place, teams can flexibly and seamlessly transition from one LLM provider or vector database to another without disrupting the overall project Flow or significantly altering code recipes. Sounds simple, but this is incredibly powerful.
A Centralized, Secure API Gateway
The LLM Mesh provides a secure API gateway that safely stores your organization’s API keys, manages security and access to models, and administers LLM usage controls for PII detection and toxicity monitoring.

Connection-level settings securely store API keys and control user access and usage of LLMs
Without the LLM Mesh, API keys may be embedded directly into scripts — a practice which not only introduces technical debt, but also could jeopardize cloud data and IT compliance policies if the keys are leaked or shared.

An example of a Gen AI script with hard-coded API keys
Best of all, at the application level there are no credentials needed in the script. Just like access to any storage system or database from within Dataiku, user group permissions determine who can use the LLM connection.
Beyond keeping API keys secure, the LLM Mesh also abstracts away the complexity of configuring secure access to diverse AI services, saving developers the time and frustration of poring through documentation to accommodate nuances in code when swapping out LLMs. Every provider has its own package/API, and while these offerings have many features in common, the corresponding code needed to interact with each is always slightly different. With the LLM Mesh, it’s easy to switch between services without changing your code, whether directly using the Dataiku Python API or LangChain.

Programmatically accessing an LLM connection from the LLM Mesh
Efficient Experiment Tracking With Dataiku Prompt Studios
If a team prefers to take advantage of built-in visual tooling like Dataiku’s Prompt Studios for prompt engineering, testing out different LLMs is even easier — just select a different model from the dropdown menu and compare the same results and projected cost estimates for multiple experiments side by side in the left panel.

Testing and comparing performance and costs of different LLMs in Dataiku Prompt Studios
Built for Change
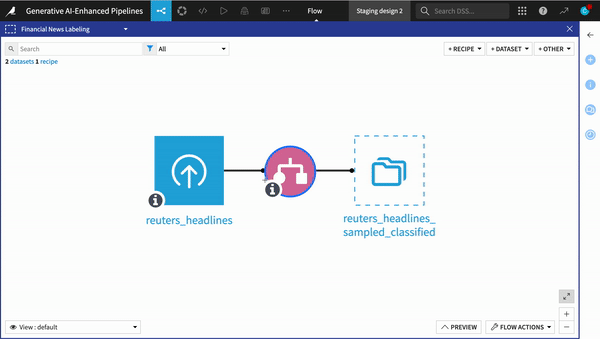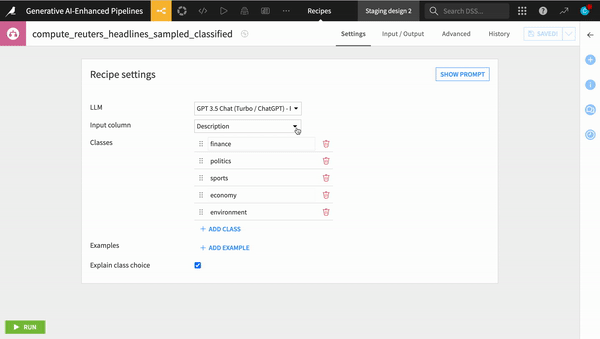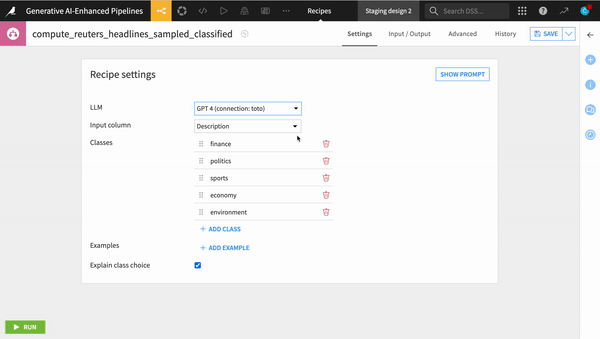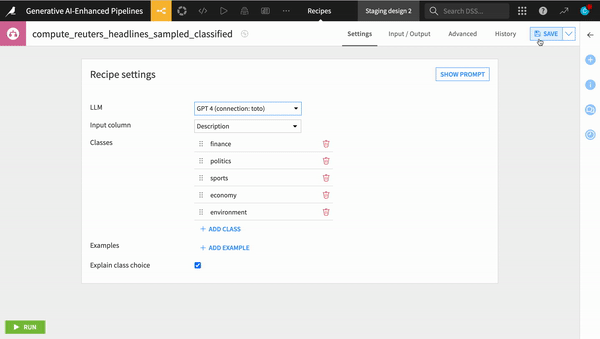
Regardless of whether a pipeline is in design or production, changing the model from one to another is as simple as selecting a different model in the drop down menu or swapping out the LLM connection id if working with code. All of the underlying dependencies and security measures are taken care of for you, so you can focus on the big picture.
{kind=link}
Changing the underlying LLM used in a production NLP pipeline
Putting It All Together
As we’ve seen, this decoupling of the application and AI service layers makes it possible to design the best possible applications and then maintain them easily in production. By maintaining choice and agility, AI systems can become more resilient, scalable, and adaptable to changes in the long run (and enterprises can trust that Dataiku is enabling their teams to produce sustainable Generative AI applications). Be on the lookout for our next article in the series, where we’ll dive deeper into the benefits of the LLM Mesh’s secure API gateway.