





What Is a Large Language Model?
22 minute read
A Large Language Model Is a Type of Neural Network
The launch of ChatGPT by OpenAI in December of 2022 drew an incredible amount of attention, extending from AI in general to the class of technologies that underpins the AI chatbot in particular. These models, called large language models (LLMs), are capable of generating text on a seemingly endless range of topics.
What makes LLMs impressive is their ability to generate human-like text in almost any language (including coding languages). While this technology is the natural evolution of natural language processing in machine learning, these models have become examples of true innovation — they produce outputs more sophisticated than anything that has existed before. Why are large language models called foundation models, you ask? A foundation model refers to AI systems designed to perform a wide range of specific applications. The original model provides a “foundation” on which other things can be built. Often, foundation models and LLMs are used synonymously because LLMs are the most well-known and widely used type of foundation model today.
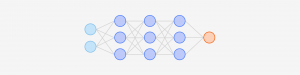
A neural network is a type of machine learning (ML) model based on a number of small mathematical functions called neurons. Like your brain’s neurons, they’re the lowest level of computation. Each neuron is a simple mathematical function that calculates an output based on some input. The power of the neural network, however, comes from the connections between the neurons.
Each neuron is connected to some of its peers, and the strength of each connection is quantified through a numerical weight. They determine the degree to which the output of one neuron will be taken into account as an input to a following neuron.
Neural networks can be very small (a basic one can have six neurons with a total of eight connections between them), or they can be very large — as is the case with LLMs. These might have millions of neurons with many hundreds of billions of connections between them, with each connection having its own weight.
An LLM Uses a Transformer Architecture
How do language models work? LLMs use a particular neural network architecture called a transformer, which is designed to process and generate textual data in sequence.
An architecture in this context describes how the neurons are connected to one another. All neural networks group their neurons into a number of different layers. If there are many layers, the network is described as being “deep” which is where the term “deep learning” comes from.
In a simple neural network architecture, each neuron might be connected to every other neuron in the layer above it. In others, a neuron might only be connected to some other neurons that are near it in a grid. The latter is the case in what are called Convolutional Neural Networks (CNNs). CNNs have formed the foundation of modern image recognition over the past decade. The fact that CNN is structured in a grid (like the pixels in an image) is no coincidence. In fact, it’s an important reason why that architecture works well for image data.
A transformer, however, is slightly different. Developed in 2017 by researchers at Google, a transformer is based on the idea of “attention,” where certain neurons are more strongly connected (or “pay more attention”) to other neurons in a sequence.
Text is both read in and produced in a sequence, one word after the other, with different parts of a sentence referring to or modifying others according to grammatical rules (e.g., adjectives modify nouns but not verbs). It’s no coincidence that an architecture that is built to work in sequence, with different strengths of connection between different parts of that sequence, should work well on text-based data.
LLMs Learn Without Explicit Instructions
In simple terms, a model is a computer program. It’s a set of instructions that perform various calculations on its input data and provides an input.
But what makes ML models or AI models special is that rather than human programmers writing those instructions explicitly, they instead specify a set of instructions (an algorithm) and hyperparameters (algorithm settings) that then reviews large volumes of existing data to define the model weights and parameters itself. As such, the human programmers don’t explicitly build the model — they build the algorithm that builds the model.
In an LLM, this means that the programmers define the architecture for the model and the rules by which it’ll be built — they don’t create the neurons or the weights between the neurons. That’s done in a process called “model training,” during which the model, following the instructions of the algorithm, defines those variables itself.
How are LLMs trained? The data that is reviewed in an LLM is text. In some cases it might be more specialized or more generic, and in the largest models, the goal is to provide the model with as many varieties of text as possible to learn from.
Over this training process, which might consume many millions of dollars’ worth of cloud computing resources, the model reviews this text and attempts to produce text of its own. Initially the output is gibberish, but through a massive process of trial and error — and by iteratively comparing its output to the target output provided in the training data — the quality of the output gradually improves. The text becomes intelligible and closer to the desired target output.
With enough time, enough computing resources, and enough training data, the model “learns” to produce human text that, to the human reader, is indistinguishable from text written by a human. In some cases, human readers may give feedback in a sort of reward model, telling it when its text reads well, or when it doesn’t (this is called “LLM reinforcement learning from human feedback,” or RLHF). The model takes this into account and continuously improves itself, based on that feedback.
An LLM Predicts Which Word Should Come Next
A reductive description of LLMs you might hear is that they, “simply predict the next word in a sequence.” While this is true, it ignores the fact that this simple process can mean tools like ChatGPT generate remarkably high-quality text. It’s just as easy to say that, “the model is simply doing math,” which is also true, but not very useful in helping us understand how the model works or appreciate its power and applications.
The result of the training process described above is a neural network with hundreds of billions of connections between the millions of neurons, each defined by the model itself. The largest models represent a large volume of data, perhaps several hundred GBs, just to store all of the weights. The GPT-3.5 model that GPT-3.5 Turbo model is based on has 175 billion weights, and while the specific number of parameters in GPT-4 has not been publicly disclosed, it likely contains hundreds of billions of parameters or more.
Each of the weights and each of the neurons is a mathematical formula that must be calculated for each word (or in some cases, a part of a word) that is provided to the model for input, and for each word (or part of a word) that it generates as its output.
It’s a technical detail, but these “small words or parts of words” are called “tokens.” These tokens are often how the use of these models is priced when they’re provided as a service. The user interacting with one of these models provides an input in the form of text. For example, we can provide the following prompt to ChatGPT:
Hello ChatGPT, please provide me with a 100-word description of Dataiku. Include a description of its software and its core value proposition.
The models behind ChatGPT then break the prompt into tokens. On average, a token is ⅘ of a word, so the above prompt and its 23 words might result in about 30 tokens.
The model would then generate a response that sounds right based on the immense volume of text that it consumed during its training. Importantly, it is not looking up anything about the query. It doesn’t have any memory where it can search for “dataiku,” “value proposition,” “software,” or any other relevant items. Instead, it’s looking at each token of output text and performing the computation again, generating a token that has the highest probability of sounding right.
LLMs Produce Text That Sounds Right, but Can’t Guarantee It Is Right
LLMs cannot guarantee that their output is right, only that it sounds right. Their responses aren’t looked up in their memories. They’re generated on the fly based on the weights described earlier. Their skill isn’t in recalling facts. The simplest databases do that perfectly well. Instead, their strength is in generating text that reads like human-written text that, well, sounds right. In many cases the text that sounds right will also actually be right, but not always. Plausible-sounding but incorrect facts are known as AI hallucinations and are one of the inherent risks when it comes to using LLMs today, though there are strategies for mitigating this risk.
Given that LLMs’ knowledge is limited to the information present in their training dataset, it might be incomplete, wrong, or outdated. For example, the training dataset of ChatGPT ends in September 2021. ChatGPT can only then be aware of facts known before this cutoff date. In addition, most if not all of the facts in this training dataset are publicly available on the internet, which means that ChatGPT can’t answer questions relating to private information. This is a concern because many valuable business use cases require taking into account non-public documents like meeting minutes, legal documents, product specifications, technical documentation, R&D reports, business procedures, and more.
A way to mitigate this drawback whenever a user asks a question is to retrieve relevant facts from an assigned knowledge bank and send both the question and the facts to the LLM. For example, using the Retrieval-Augmented Generation (RAG) approach and Dataiku Answers, our pre-built chat interface, Dataiku has developed a Q&A chatbot to provide answers from Dataiku’s documentation that does just that. Techniques like RAG are a more reliable way to create tailored enterprise chatbots at scale.
Language models can be also augmented with tools that give them access to external knowledge sources, extending their reasoning capabilities and letting them act in the real world. These types of augmented LLMs are usually called “agents.” In this context, a tool is simply any function or program that an agent can use to perform a task. We’ll dig deeper into these techniques later on, when we explain how to enhance LLMs with prompt engineering, RAG, and more.
Using LLMs in the Enterprise
Leveraging LLMs in the enterprise can be done in one of two ways. And each approach has advantages and drawbacks that we’ll explore next.
Option 1: Leveraging LLM APIs
The first way to use LLMs in an enterprise context is to make an API call to a model provided as a service. As an example, companies can access the GPT-3.5 and GPT-4 models that power ChatGPT to build their own proprietary applications.
In addition to LLM-specific providers such as OpenAI, Anthropic, Mistral, and Cohere, the major cloud computing companies also provide dedicated AI services: Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Azure OpenAI Service.
Making an API call requires setting up a small software program, or a script. This script connects to the API and sends a properly formatted request. The API submits the request to the model, which will then provide the response back to the API. The API then sends that response back to the original requester.
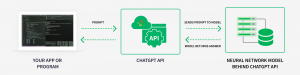
Advantages of Using a Large Language Model-as-a-Service by API
This approach has several advantages, including:
- Low barrier to entry: Calling an API is a simple task. It can be done by a junior developer in a matter of minutes.
- More sophisticated models: The models behind the API are often the largest and most sophisticated versions available. This means that they can provide more sophisticated and accurate responses on a wider range of topics than smaller, simpler models.
- Fast responses: Generally, these models can provide relatively quick responses (on the order of seconds) allowing for real-time use.
Limitations of Using a Large Language Model-as-a-Service by API
The use of public models via API, as we saw above, is convenient and powerful. However, it may also be inappropriate for certain enterprise applications due to the following limitations:
- Data residency and privacy: Public APIs require query content to be sent to the servers of the API service. Enterprises should be careful to check if this architecture respects their data residency and privacy obligations for a given use case.
- Potentially high cost: Most of the public APIs are paid services. The user is charged based on the volume of queries and the quantity of text submitted, which can escalate rapidly, especially if RAG or agent-based approaches are employed. To prevent surprise bills at the end of the month, companies should implement disciplined cost control and monitoring processes.
- Dependency: The provider of an API can choose to stop or change the service at any time. Enterprises should weigh the risk of building a dependency on such a service and ensure that they have a fall-back plan in place.
Option 2: Running an Open-Source Model in a Managed Environment
The second option is downloading and running an open-source model in an environment that you manage. Platforms like Hugging Face aggregate a wide range of such models.
Given the drawbacks of using a public model via API, this option could make sense for certain companies or use cases. These models can be run on servers that an enterprise owns or in a cloud environment that the enterprise manages.
Advantages of Self Managing an Open-Source Model
This approach has multiple interesting advantages, including:
- Security and privacy: These models can be hosted in a private or even offline environment, making them suitable for highly regulated industries or use cases that involve Personally Identifiable Information (PII) or sensitive information.
- Wide range of choice: There are hundreds of thousands of open-source models and model families including LLaMA, Mixtral, Falcon, and more, each of which presents its own strengths and weaknesses. Companies can choose the model that best suits their needs. That said, doing so requires deep familiarity with the technology and how to interpret those tradeoffs and, with so many models to choose from, LLM selection can become such a daunting task that being spoiled for choice almost becomes a drawback.
- Potentially lower cost: In some cases, running a smaller model that is more limited in its application makes sense. It can provide the right performance for a specific use case at lower cost since you only pay for the model storage and computation needed for model inference.
- Independence: By running and maintaining open-source models themselves, organizations are not dependent on a third-party API service. They can fine-tune or adapt these models as they wish.
Tradeoffs to Self Managing an Open-Source Model
There are many advantages to using an open-source model. However, it may not be the appropriate choice for every organization or every use case for the following reasons:
- Complexity: Setting up and maintaining a LLM requires a high degree of data science and engineering expertise. We’re talking beyond that required for simpler machine learning models. Organizations should evaluate if they have sufficient expertise. And more important, if those experts have the necessary time and skills to set up and maintain the model in the long run.
- Cost: In addition to the expense of the specialized AI engineering resources needed to set up and maintain self-hosted LLMs, you’ll also want to consider the cost of GPUs and ongoing computation. One way or another, those calculations must be run on hardware that is installed, managed, and consuming electricity, for which someone will have to pay the bill at the end of the month. Major LLM providers can distribute the hardware and compute costs across their entire customer base, significantly lowering the cost burden for individual customers.
- Narrower performance: The very large models provided via public APIs are astonishing in the breadth of topics that they can cover. Models provided by the open-source community are generally smaller and more focused in their application.
Become AI-Powered With Dataiku
Our core vision has always been to allow enterprises to quickly integrate the latest technology. This philosophy continues with LLMs.
For enterprise LLM applications, the decision to use AI services versus self-hosted models will depend on the use case. Fortunately, Dataiku fully supports both approaches, as well as the broader framework necessary for using LLMs at scale. Dataiku provides a direct connection to over 15 major cloud and AI vendors like Amazon Web Services (AWS), Databricks, Google Cloud, Microsoft Azure, Snowflake (Arctic), and more.
In addition, Dataiku provides additional deep learning and NLP capabilities. These are built on LLMs to assist in building machine learning models using natural language or images as an input. For example, embedding models registered to your LLM Mesh makes it simple to convert both text and images to numerical values, while still preserving the pertinent information in these forms of unstructured data. These vectorized features can then be easily used in the visual machine learning interface for classification and regression tasks.
Go Further
Discover Generative AI Use Cases: Real Applications, Real Safety
Enhancing LLMs With Prompt Engineering, RAG, and More
Think of LLMs as a Swiss Army knife: fluent in multiple languages, packed with expertise across a vast array of topics, and deeply knowledgeable about almost all publicly available information. Whether you need quick explanations on quantum physics, a summary of a Shakespearean play, or assistance in crafting compelling storytelling for your brand, this is your versatile assistant, capable of answering a diverse set of questions with skill and ease.
But here’s the catch: As pre-trained models, they have limits. While skilled at discussing history, literature, science, etc. based on their broad training, they lack knowledge of recent events, emerging trends, and undisclosed details. They cannot access your organization’s private documents and data or tailor their answers to your industry’s unique context. And in their desire to assist, LLMs can sometimes offer answers that seem plausible but are, in fact, hallucinations — convincing statements not backed by data. This is a significant caveat when accurate and credible information isn’t just a good-to-have, but a must-have. In your data-driven role, you often need specific, timely insights you can completely trust — not just plausible responses.
To overcome these limitations, you can employ prompt engineering, which involves crafting more complex prompts and incorporating relevant industry documents and data. Note that this process requires careful selection of pertinent information within the vast sea of available data and can sometimes result in lengthy prompts. While submitting a prompt without any examples of an expected or ideal response (known as zero-shot learning) is possible, including a handful of examples in your prompt as additional context to guide the LLM (a technique called few-shot learning) often yields significantly better results with precise answers tailored to your unique context.
While LLMs and prompt engineering provide an excellent starting point, the twists and turns of the maze you’re navigating requires specialized equipment attuned to your business environment.
The Knowledge Forest: RAG Lights the Way
If you’re sitting on a goldmine of text documents — be it contracts, user guides, or endless PDFs — there’s a compass to guide you through the maze: RAG.
What is RAG in an LLM? Imagine your organization’s documents are like a vast library. In this scenario, RAG acts as an ultra-efficient librarian: You ask a question, and RAG identifies the most relevant sections from various documents. These handpicked pieces are then coupled with your query and given to an LLM, which crafts an answer directly based on the information found in your documents. That’s RAG in a nutshell.

First, it chunks your documents into bite-sized pieces, transforms them into vectors, and stores them in a cozy little place called a vector store. When you throw a question into the ring, RAG acts like your very own librarian. It scans the vector store to find the vectors — essentially the document chunks — that are closest to your query. These are then paired with your question and fed to an LLM like ChatGPT, which then crafts an answer directly sourced from your documents.
If you’re wondering how to implement all of this without getting tangled in technicalities, Dataiku is rolling out a set of components that integrate this RAG technique right into your workflow. The visual embed recipe comes with a document parser and vector store baked in, and Dataiku even provides a template for an intuitive web app interface where you can simply ask your questions in natural language to instantly generate answers sourced from your documents.
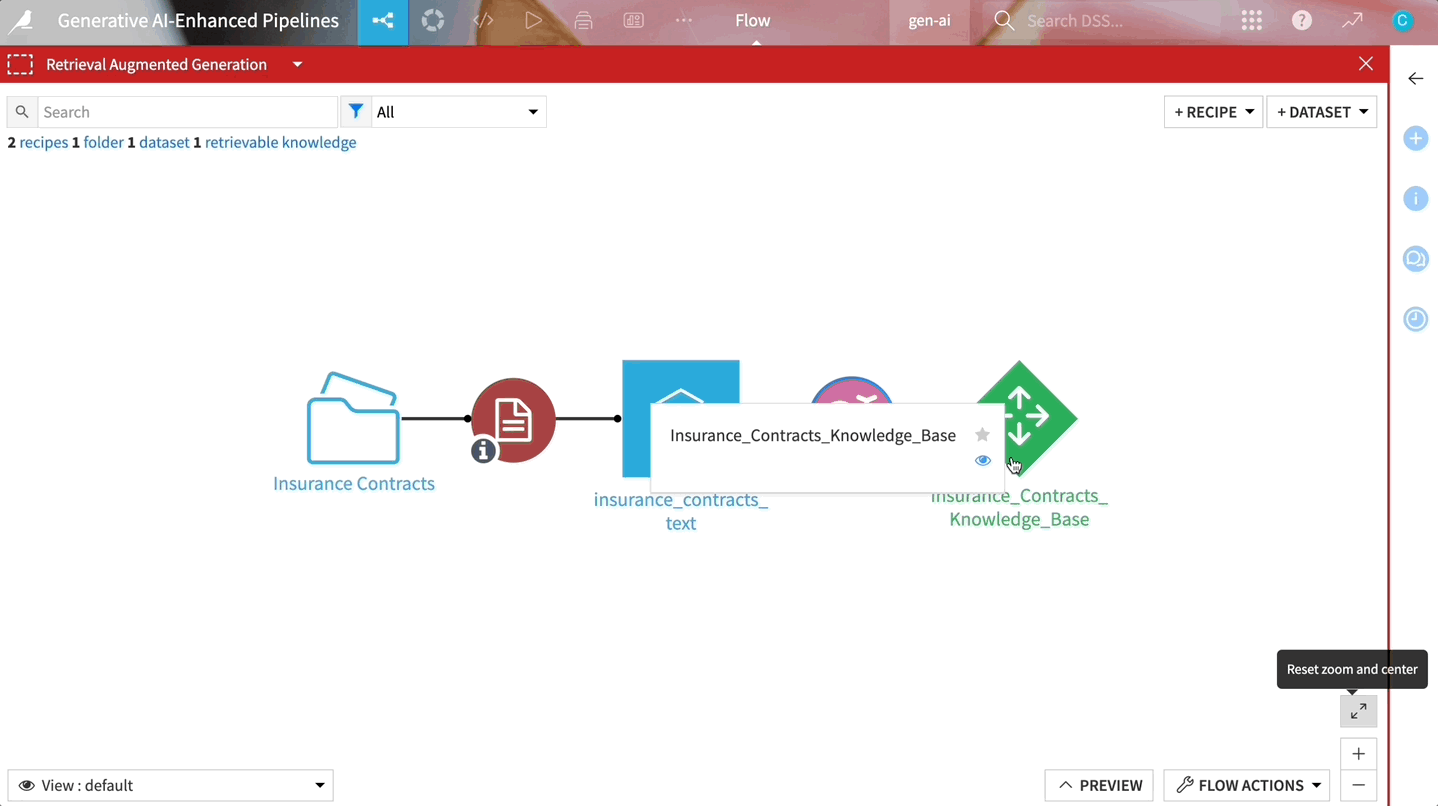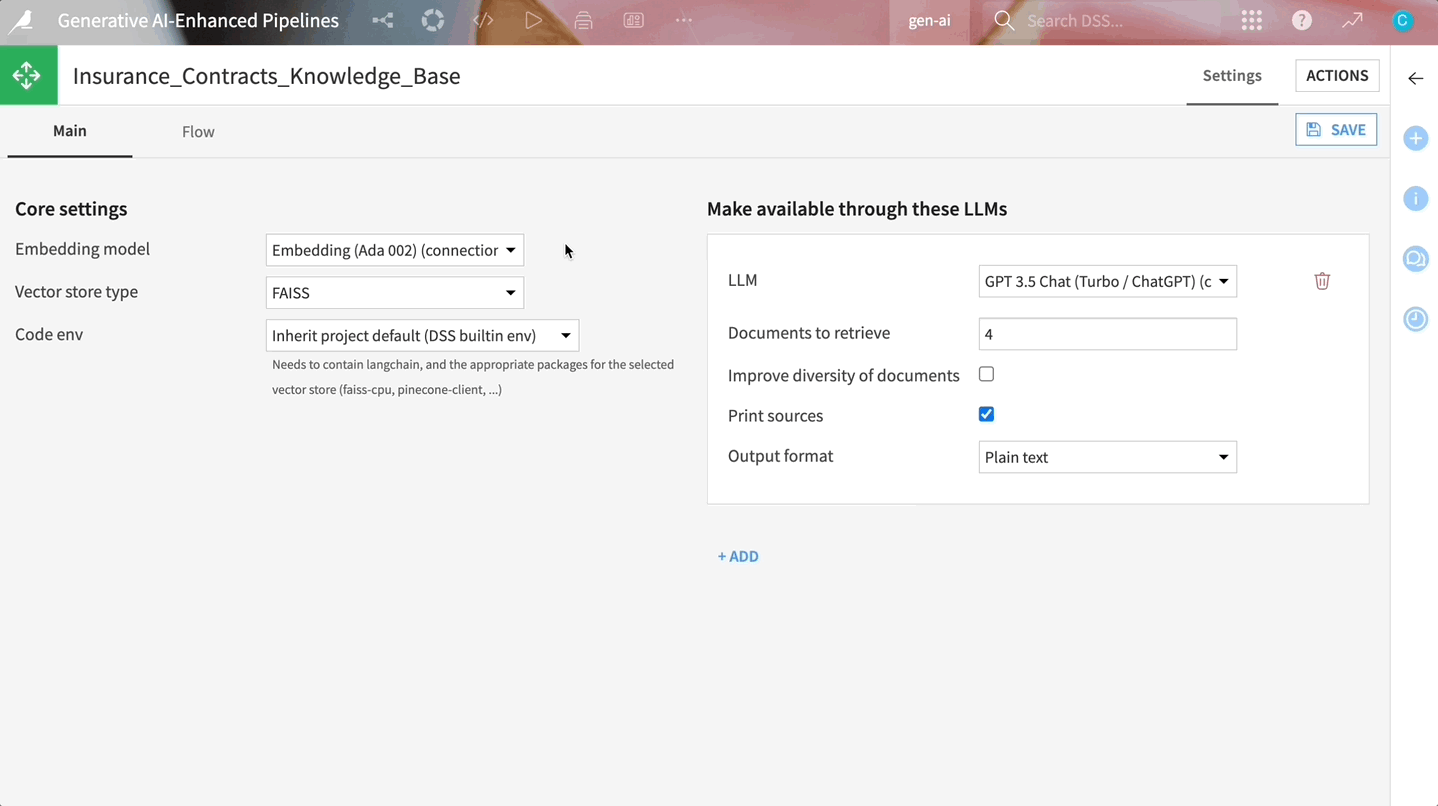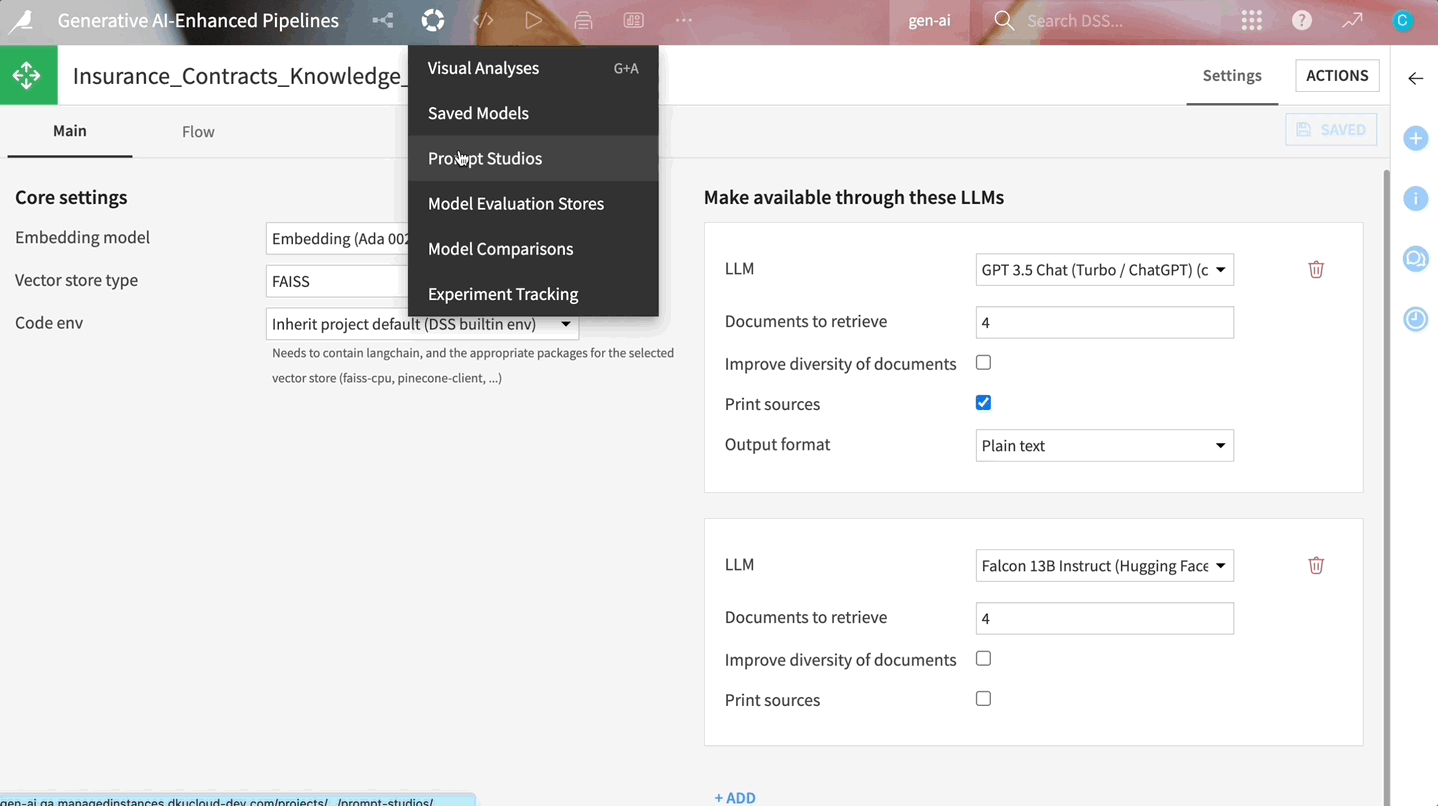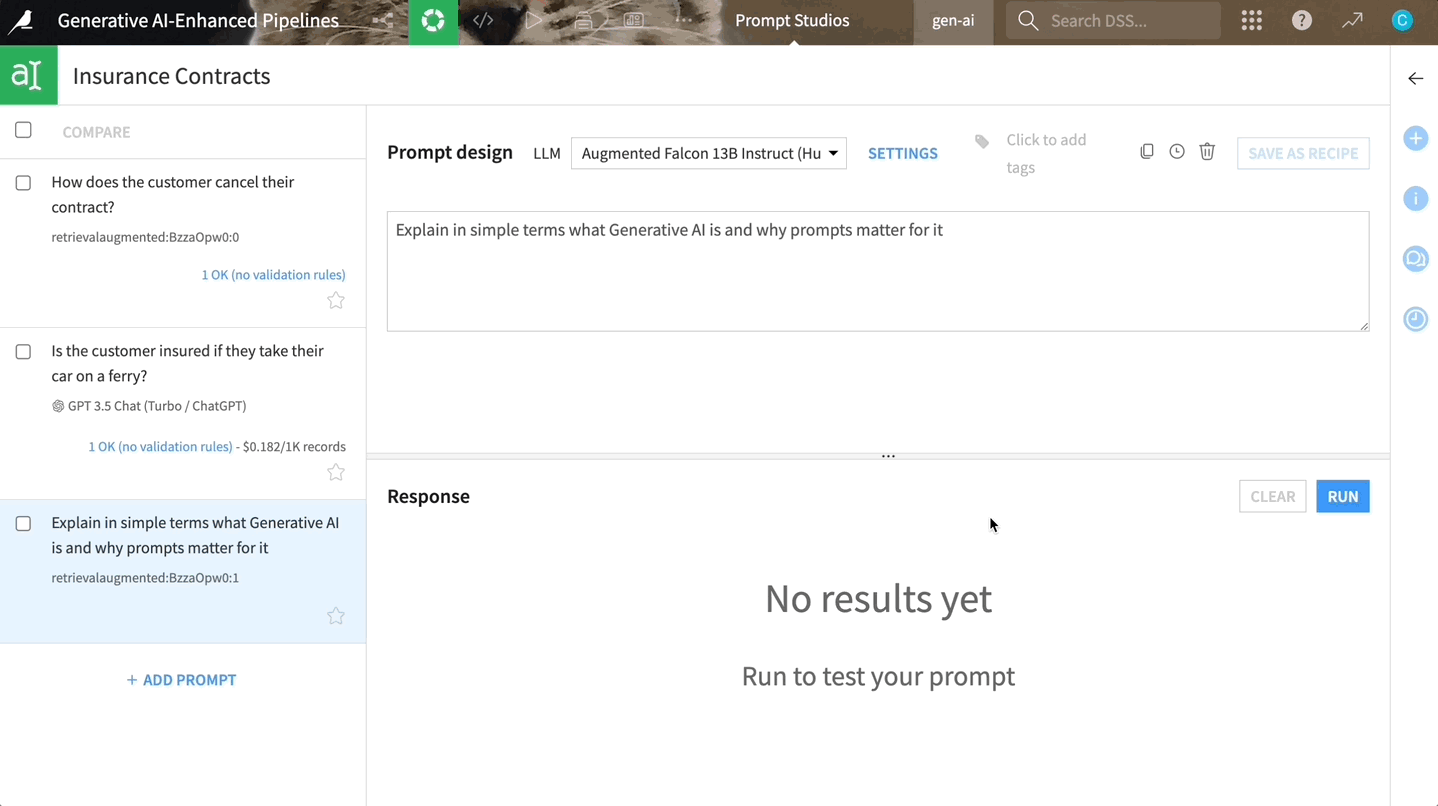
Dataiku’s built-in components extract the text from your documents, vectorize and store the information, and use it to enrich a foundational LLM.
Now picture this frustrating scenario: You’re geared up, eager to unleash RAG on your data, only to realize you’re not working with text documents but with datasets that span millions of rows. Why won’t RAG work here? Because embedding tables as vectors isn’t exactly its forte. It’s time to uncover the maze’s secret passageways. Let’s delve into a technique called “Instruction-Driven Query Execution” that takes you beyond RAG’s limitations and allows you to not only integrate LLMs with your tabular data, but also generate charts and dashboards to illuminate your path.
Tackling Advanced Challenges With Instruction-Driven Commands
As you navigate datasets rather than documents, you need a different compass to guide you. Enter instruction-driven querying.
The main idea is simple: You provide the LLM with your dataset’s schema — think column names, types, and descriptions — and then specifically ask it to generate executable instructions for your query. These aren’t just any instructions; they’re typically in Python or SQL, designed to run locally to pull the exact insights you’re after. Just describe the information you seek in natural language, and the LLM crafts the exact code to produce charts, metrics, and visualizations attuned to your data. No coding needed from you — the LLM becomes the programmer, statistician, and data scientist all in one.
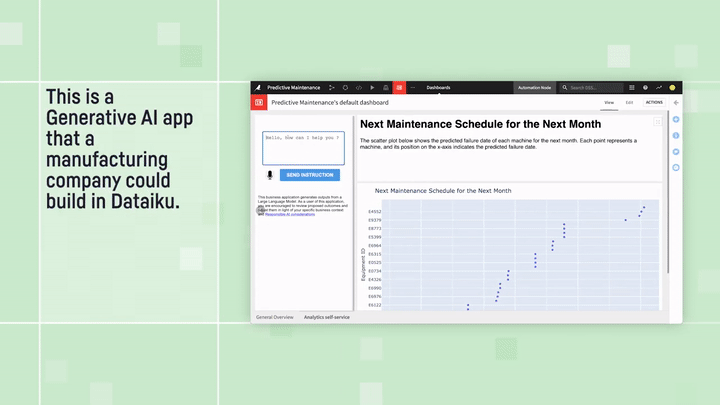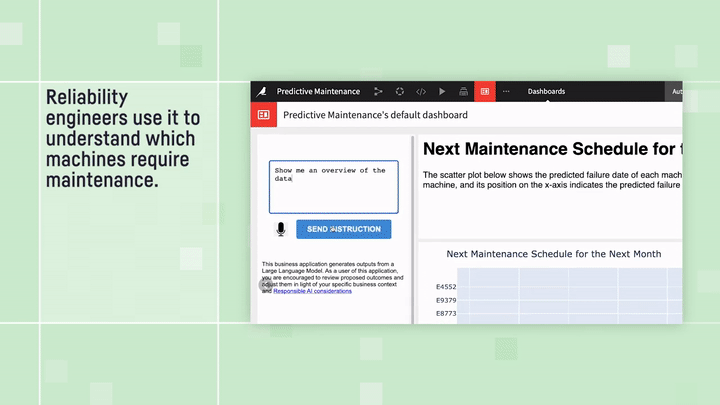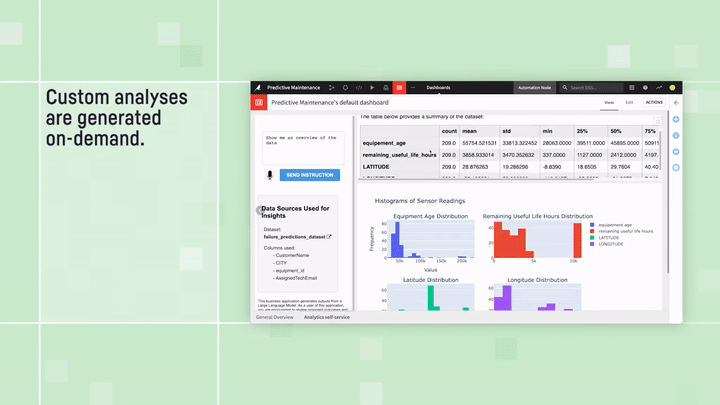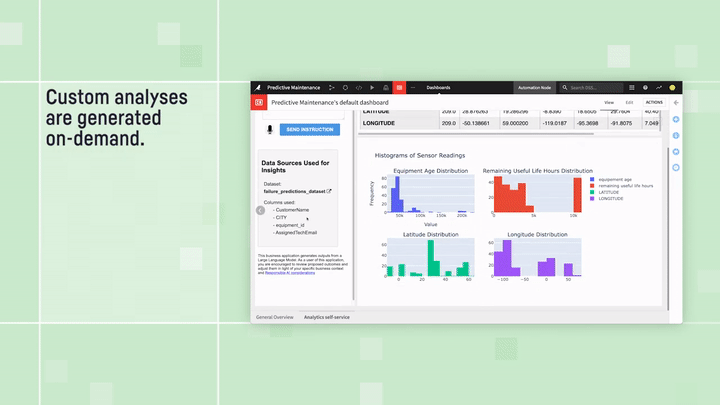
Predictive Maintenance Analysis: “text to dashboard” example
Safety first, of course. Dataiku ensures a secure experience, offering code execution that scales across various infrastructures and Python APIs to give you seamless access to datasets, models, recipes, and dashboards. Plus, all code is executed under profiles with controlled security measures, ensuring no accidental data mishaps.
And if your data is a bit more free-form — say, a collection of customer reviews — you’re not out of luck. You can employ “structure” patterns to turn that unstructured text into a neat dataset. Check out this blog to see how this is done. This allows you to take advantage of the Instruction-Driven Query Execution method, after your data has been classified, tagged, or organized.
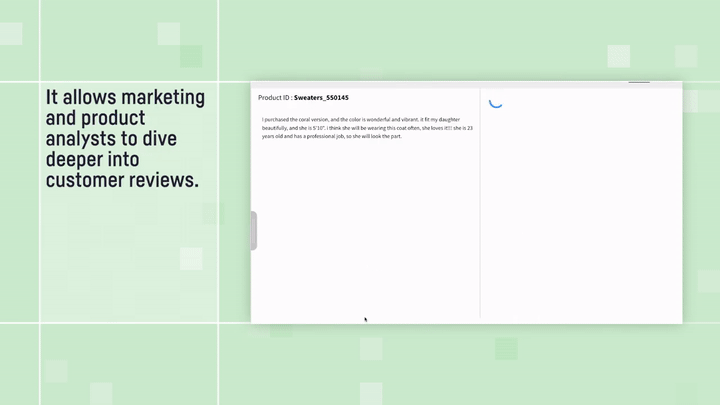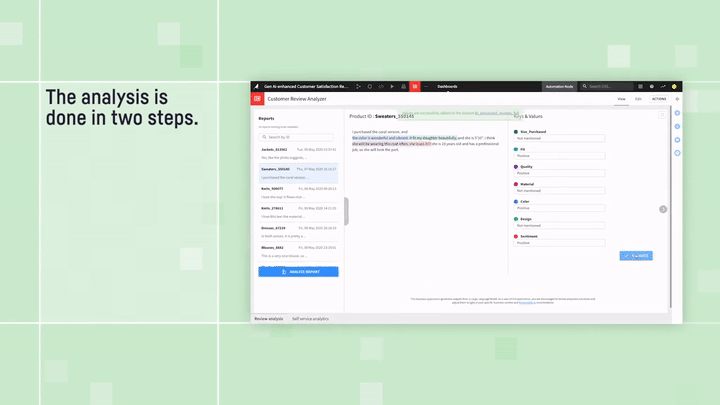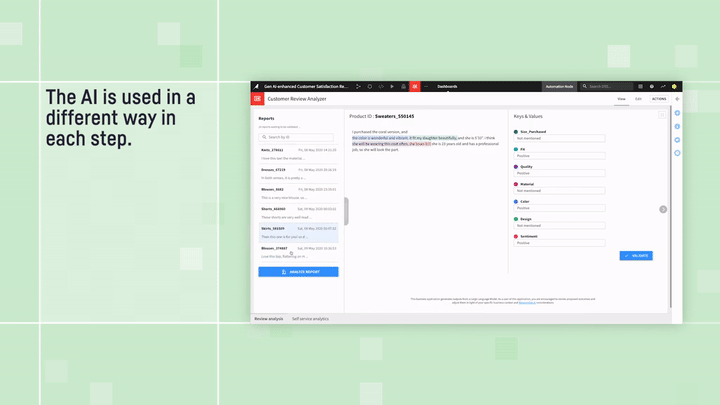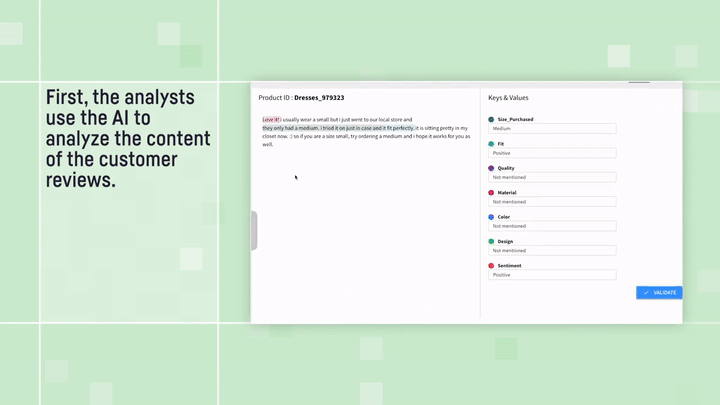
Customer Review Analyzer: text structuring example
You’ve upgraded your toolkit with RAG and instruction-driven queries, but the winding maze ahead contains a mix of documents, datasets, and other challenges requiring a fusion of tools. The next level is integrating these into a custom-designed intelligent guide who knows when and how to apply each tool to illuminate the way.
Master Agents That Unleash Full Potential
The winding maze stretches onward, filled with a myriad of twists, turns, and mixed data types. Documents, datasets, websites: You need a guide capable of dynamically selecting the right tool for each challenge. Enter AI agents — your custom-designed master orchestrator.
Much like a knowledgeable explorer, AI agents determine the optimal approach for a given situation by combining reasoning with action. Need to answer a question using internal documents and a dataset? The agent dispatches a RAG-based tool to quickly retrieve relevant texts and calls on instruction-driven queries to generate custom analytics code. And when facing an unfamiliar challenge, the agent can iteratively try combinations of tools, expanding its capabilities over time.
Dataiku helps organizations move from chatbots to agents by offering a complete set of capabilities to leverage emerging frameworks such as ReAct and LangChain. Take a look at our LLM Starter Kit to learn more on how to build an LLM, explore examples of LLMs, and start building your own advanced LLM chains.
AI frameworks like ReAct combine reasoning with action by allowing an AI agent to first engage in a reasoning process about the best approach (potentially considering context from documents, the prompt, or other content generation), then execute other actions based on the results of that reasoning. This process can ensure tools an AI agent uses are guided by a logical reasoning sequence, leading to higher quality responses and actions.
Fine-Tuning an LLM on Your Data
You might think that fine-tuning an LLM on your organization’s internal documents is the obvious next step. After all, it sounds like the holy grail for those familiar with traditional models. But be cautious — this route comes with its share of challenges.
Firstly, fine-tuning is a resource-heavy endeavor. It’s not just about the computational costs but also about the time and expertise needed to set up a balanced training dataset. Plus, the model will require frequent updates as new documents or changes roll in.
Secondly, fine-tuning is a double-edged sword when it comes to learning. Go too far, and the model might forget its general knowledge, becoming overly specialized in your industry’s jargon. The balance between retaining worldly wisdom and acquiring the specifics of your documents is hard to strike.
Lastly, even with a fine-tuned model, you’ll still need to verify the information it provides. Unlike RAG, which cites its sources, a fine-tuned model leaves you to do the homework of ensuring its answers aren’t hallucinations.
That said, fine-tuning isn’t without its merits. It can be an effective approach for specific needs, like teaching the model a new style of writing or enabling it to better understand domain-specific terminology, jargon, and context. For this reason, Dataiku provides both visual and code-based components to simplify the process of fine-tuning LLMs, whether open-source local models or LLM API services, to suit your particular purposes.
Assembling the Right AI Tools for Large Language Models
In the complex world of modern data, the journey is less about following a single, straight path and more about navigating a diverse terrain. No single tool can conquer every challenge; instead, we need a versatile toolkit where various instruments work in concert, each offering its unique strengths when faced with different data landscapes.
As we forge ahead in this pioneering work, we must also cultivate Responsible AI practices, taking care to audit for biases, ensure transparency, and firmly establish human oversight. By integrating the right tools and grounded principles, we can reshape how knowledge is synthesized across data sources to deliver ethical, consistent and auditable insights. The path forward holds endless potential, but it requires adopting a nuanced toolkit coupled with Responsible AI values to guide us. Looking for a great place to start? This Dataiku ebook explores the risks and introduces the RAFT (Reliable, Accountable, Fair, and Transparent) framework for Responsible AI, applicable to both traditional and GenAI systems.
In the grand scheme of things, we are but explorers in the vast expanse of the data universe. But equipped with a robust toolkit, a spirit of innovation, and a commitment to Responsible AI, we’re more than ready to navigate the path ahead. The journey continues, and we’re excited to see where it leads.
Now you’ve seen how LLMs as part of a strong toolkit can help navigate even the most difficult data challenges. The next section explores how LLMs can be best used as part of an enterprise — perhaps the most tangible application of how this branch of AI can be leveraged.
Conclusion: Time to Build Your Large Language Models
LLMs have revolutionized the way we interact with and use AI, offering unprecedented capabilities in NLP and more. Whether you’re leveraging APIs for quick integration or managing open-source models for greater control, understanding how these models work and the best practices for their deployment is crucial.
As enterprises explore these technologies, tools like prompt engineering, RAG, and instruction-driven querying become essential in maximizing the potential of LLMs while mitigating risks. By integrating these strategies, businesses can harness the full power of LLMs, transforming vast data into actionable insights.
