




{kind=link}
This article was written in collaboration with our friends at Aimpoint Digital.
This blog is the second part of a two-part series. To understand the overall project goals, data preparation steps, and initial model creation, we recommend reading part one before reading this post. The blog's second and final part is focused on creating a predictive model and maintaining our data project in production. Critically, we continue with the trend of gaining insights from data without writing code.

Model Testing
Before testing any models, let us define the task at hand. After feature extraction and cleansing, we have 60 columns and 85,000 rows. The most critical column is our target variable, "on-time-delivery," which designates each row with "on-time" or "missed delivery window." Our goal is to find a model (or ensemble of models) that minimizes the false negatives (i.e., we are okay with our model classifying a delivery request as late, even if it has a slightly higher than 50% chance of making it within the delivery window).
Dataiku offers an incredible depth of features for visually creating machine learning (ML) models. However, there is always an option for code. Check out this walkthrough for 'Using Jupyter Notebooks in Dataiku.'
Model Design
We will conduct model testing in two phases. First, we will use Dataiku AutoML to create baseline models. Second, we will interrogate and customize the baseline models.
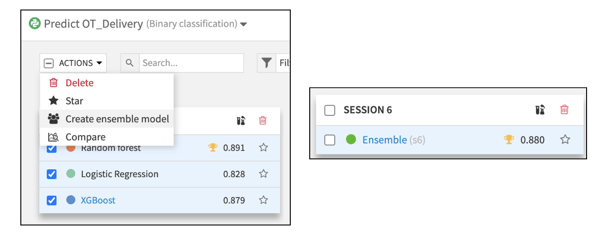
Let us take a look at the baseline models from AutoML and, for the first time, understand how our data responds to the automatically selected models. Dataiku segments each model run by sessions, the models from AutoML are always session one. Sessions two and three are subsequent changes to the models. We notice that random forest has a ROC AUC of 0.891, but what does that mean? Beyond just creating models, Dataiku lets users focus on model explainability.
Dataiku is extensively committed to Responsible AI; thus, there are many fantastic model explainability features this blog does not cover. I highly recommend bookmarking this aptly titled article 'Explain Your Model.'
Model explainability helps us create models that respond well to new data. For instance, the screenshot above shows the importance of the top variables for predicting on-time delivery. In our case, we can see that the number of times the delivery appointment is changed significantly influences a delivery making it within the delivery window.
Model Ensemble
We have created three classification models (random forest, logistic regression, and XGBoost), and each model has a reasonable ROC AUC. Instead of choosing across the three models, we can ensemble them; It is almost like using "wisdom of the crowds." Aggregated predictions from a collection of good models are likely to outperform any single model alone.
The task of ensembling models is generally reserved for advanced users. However, with Dataiku, we simply need to select the models and click 'create ensemble model,' and Dataiku creates a new model that we can deploy to our training pipeline.
MLOps
Once we have a model we are satisfied with, MLOps is the next logical step. MLOps or Machine Learning Operations refers to deploying and maintaining models in production. In a data project, MLOps is often the difference between a project that stalls and amounts to nothing more than an academic exploration versus a project that is actively contributing to saving cost, generating revenue, or both.
Dataiku offers a full suite of capabilities dedicated to MLOps beyond the scope of this business analysts-focused blog. Each company's MLOps strategy will differ based on company-wide IT policies, the company's infrastructure strategy, and the specific goals of the project itself. There are, however, two critical components for deploying and maintaining projects in production: automation and API endpoints. Automation refers to scheduling the data pipeline and monitoring data drift. As the name suggests, API endpoint is the process of deploying our predictive model(s) as a REST API endpoint. For an in-depth review of MLOps with Dataiku, I highly recommend checking out this video by one of my colleagues or our MLOps practitioner learning path in the Dataiku Academy.
Recap
Across the two blogs, we covered a significant amount of content, yet it is the tip of the iceberg for Dataiku's capabilities. Let us close out our blog series with an overview of the critical steps and goals. The critical steps consisted of extensive data exploration and preparation, model testing, and finally deploying the ensembled model to our training pipeline. The goal was clear, an ML model that can help us reduce the number of missed delivery windows. Last but not least, recall that all the steps outlined required zero code experience. We went from exploring data to creating an advanced model iteratively and collaboratively.