




{kind=link}
Large language models (LLMs) excel at generating coherent and credible continuations of input texts and this ability can be used to accomplish a wide range of natural language processing tasks. However, they suffer from major limitations:
- Limited knowledge: LLMs know (at most) the information present in their training dataset. This information may be incomplete, erroneous, or simply outdated;
- Poor abilities for certain tasks: Surprisingly, LLMs struggle on some straightforward tasks, for example, multiplying two large numbers or counting the number of letters in a word;
- No interactions with the real world: LLMs only generate text and, as a result, they cannot affect the real world when they are used in isolation.
A powerful approach to overcome these weaknesses is to turn the LLM into an agent (i.e., to give it the possibility to use external tools). In this blog post:
- We describe a motivating example to better illustrate the notion of agent;
- We explain the most popular approach to induce an agent to trigger tools;
- We show how to create tools;
- We briefly discuss how to improve the reliability of agents;
- We introduce a publicly available and reusable Dataiku project that demonstrates the creation and use of an agent.
A Motivating Example
Let’s imagine a telecommunications company offering internet and phone services to private customers. The company receives support requests from its customers, such as:
- “I have a problem with my internet connection. Can you please solve this?”
- “I forgot my password. What can I do?”
- “I want to sign up for the Premium option.”
The company already has various tools in its IT system to accomplish various tasks (cf. table below for some examples) but the key challenge is to properly interpret the customers’ requests, and accordingly select and use the right tools. This is exactly where an agent can help!
ReAct: A Simple Approach to Implement Agents
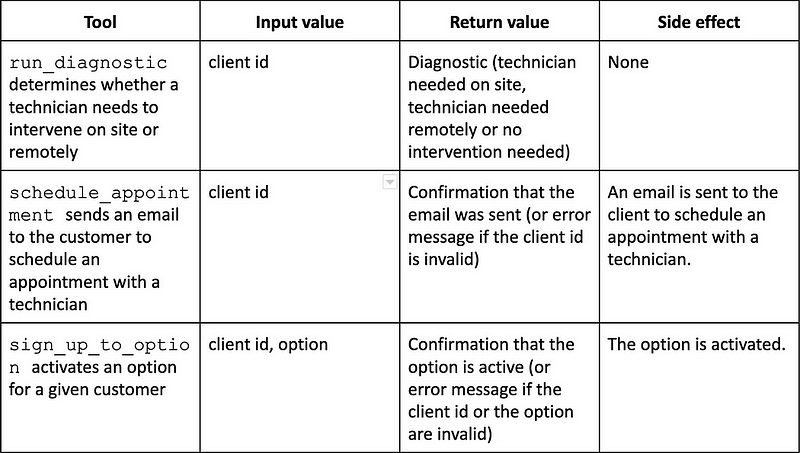
ReAct is a popular approach to implement agents. It is both simple and effective and it only requires an off-the-shelf LLM like gpt-3.5-turbo (the model that powers ChatGPT). Here is how ReAct works:
- We initiate a prompt with the overall context, the request to process, the list of tools with their descriptions, and instructions to follow a certain structure. This prescribed structure consists in a loop with three elements:
— A paragraph starting with “Thoughts:” with the current analysis of the situation;
— A line with “Action:” followed by the name of a tool and the corresponding input values or a line starting with “Action: Finish” followed by the final answer;
— A paragraph starting with “Observation:” with the result of the action. - We ask the LLM to generate the continuation of the prompt above. If the LLM is powerful enough and if the prompt is adequate, the LLM will follow the prescribed structure. We stop the text generation whenever we detect “Observation:” or a line starting with “Action: Finish.”
- If we stop in the previous step at “Observation:,” we parse the LLM output to retrieve the requested tool and its input values. We use the tool (independently from the LLM) and we append the output of the tool (which needs to be formatted as text) to all the text generated so far. We then go back to Step 2.
- If the text generation in Step 2 was interrupted because of a line starting with “Action: Finish,” we extract the final answer and end the process.
Defining Tools
Given the way ReAct works, defining a tool requires specifying:
- A name and a description, included in the prompt at Step 1;
- A function that is executed at Step 3.
We now illustrate what these names, descriptions, and functions can be with three concrete examples.
A Tool Querying a Predictive Model
An existing predictive model can easily be converted into a tool. For example, the fictitious run_diagnostic tool mentioned above may leverage a predictive model. In this case,
- The name of the tool should suggest what the predictive model does (e.g., run_diagnostics);
- The description should specify what the input values are and what prediction is provided. The input values can be either directly the features of the model or an identifier of the individual or object for which a prediction is requested (cf. the run_diagnostic tool mentioned above which only requires a client id). The description can also include more details about the circumstances in which the tool should be used (see this for an example);
- The function calls the predictive model and returns its prediction. Depending on the situation, the function can include a pre-processing step to retrieve the input features (if only an identifier is provided) and a post-processing step to convert the raw predictions into an explicit text output.
A Tool Answering Questions on a Set of Documents
A tool can also help answer a question on the basis of a set of documents. In our example, we can assume that an operating manual describes how to process the customers’ request and a tool leveraging this document could help the agent properly address these requests. For this tool:
- The name of the tool should allude to the types of questions answered by the tool (e.g., query_documents);
- The description should be more specific about the content covered by the tools. For example, it can specify the scope and purpose of the documents (see this for an example);
- The function is an LLM chain based on the retrieval-augmented generation (RAG) approach. The RAG approach is described in detail in one of our previous blog posts. The function takes a question as input and returns an answer grounded in the documents.
A Tool Querying Datasets With SQL
Our last example is a tool based on a collection of datasets. Just like in the previous section, our tool is used for question-answering, but this time is based on a collection of datasets. In our example, such datasets could include billing and consumption information and the tool may answer questions regarding these data. In this situation:
- As before, the name of the tool should allude to the types of questions answered by the tool (e.g., query_datasets);
- The description should give more explicit information about the answers potentially provided by the tool. In particular, it can list the datasets and summarize their content (see this for an example);
- The function is based on an LLM text2sql chain with the following steps: conversion of the question into an SQL query with an LLM, execution of the SQL query, transformation of the resulting table into a natural language answer with an LLM.
Implementing Dataiku-Specific Tools
We demonstrate the implementation of agents corresponding to our running example in two Dataiku sample projects. In the first one (cf. the “4. LLMs combined with tools” Flow zone), the tools are simply derived from Python functions thanks to LangChain. In the second project, we go a step further and build the tools starting from pre-existing Dataiku objects:
- The API endpoint corresponding to an arbitrary Python function or a model;
- A managed folder;
- A collection of datasets.
For each of those, we wrote a generic Python function that creates the corresponding LangChain tool. With such functions, if your relevant resources are already in Dataiku, it becomes very straightforward to experiment with agents.
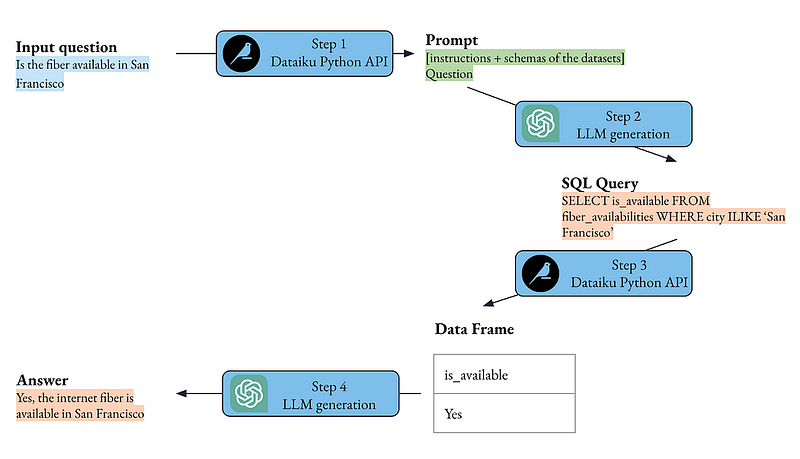
To dive a little deeper, let’s see how the function of query_datasets works:
- A text2sql LLM chain is instantiated with the input question and the schemas of the datasets obtained programmatically with the Dataiku Python API;
- The text2sql LLM chain is executed and returns an SQL query;
- The SQL query is executed with the Dataiku Python API (either through SQLExecutor2 if the datasets are accessed through a SQL connection or through the Dataset objects and pandas if not) and returns a table;
- An LLM is called to convert the answer in a natural language answer.
Improving the Reliability of Agents
Even if the results obtained with an agent can be quite impressive (cf. the results in our examples obtained with gpt-4 or gpt-3.5-turbo), mistakes remain possible. An agent can overlook instructions, inadequately use certain tools or even “hallucinate” non-existing tools. You should then consider various measures to make your agents more reliable:
- Extensively test on realistic scenarios;
- Use a sufficiently powerful model (e.g., gpt-3.5-turbo or even gpt-4);
- Adjust the tools’ names, descriptions, and outputs so that the LLM understand when and how to use each tool;
- Whenever possible given the context, give the agent only “restricted” tools rather than “general” tools. For example, if we know that a request corresponds to a certain client, we can create an ad-hoc agent whose tools have the “client id” field pre-populated with the right value. This point is shown in our Dataiku sample projects.
- Reduce the risks of formatting errors or hallucinations using frameworks like LMQL, Guidance or the OpenAI function calling feature;
- Include a human verification step for certain tools;
- Refrain from including some tools when their inadequate use is too likely or detrimental.
Conclusion
External tools open the way to particularly innovative and powerful LLM use cases, in which agents can interact with the real world.
Experimenting with such agents is surprisingly straightforward:
- The definition of a tool just requires a name, a natural language description, and a function;
- Tools can be easily derived from existing objects, for example from Python functions with LangChain or from Dataiku objects as illustrated in our Dataiku sample project;
- The ReAct approach is the same regardless of the actual set of tools and is easy to implement with frameworks like LangChain.
However, deploying agents in production will be challenging and will require extensive testing and many iterations on the scope and specific implementation details of the tools.