




{kind=link}
It's hard to know where to start once you’ve decided that, yes, you want to dive into the fascinating world of data, analytics, and AI. Just looking at all the technologies you have to understand and tools you’re supposed to master can be dizzying. What data science steps do you take first?
Luckily for you, building your first data analytics project plan is actually not as hard as it seems. Yes, starting with a tool that is designed to empower people of all backgrounds and levels of expertise such as Dataiku helps, but first you need to understand the data science process itself. Becoming a data-powered, AI high achiever is first and foremost about learning the basic steps and phases of a data analytics project and following them from raw data preparation to building a machine learning model, and ultimately, to operationalization.
The following is our take on a data project definition via the fundamental steps of a data analytics project plan in this exciting age of analytics and AI (including generative AI and agentic AI)! These seven data science steps will help ensure that you realize business value from each unique project and mitigate the risk of error. .jpg?width=800&height=450&name=GM3385%20Graphic%20v2%20(1).jpg)
Step 1: Understand the Business
.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(3).jpg) Understanding the business or activity that your data project is part of is key to ensuring its success and the first phase of any sound data analytics project. To motivate the different actors necessary to get your project from design to production, your project must be the answer to a clear organizational need. Before you even think about the data, go out and talk to the people in your organization whose processes or whose business you aim to improve with data (beyond simply using spreadsheets). Then, sit down to define a timeline and concrete key performance indicators. I know, planning and processes seem boring, but, in the end, they are an essential first step to kickstart your data initiative!
Understanding the business or activity that your data project is part of is key to ensuring its success and the first phase of any sound data analytics project. To motivate the different actors necessary to get your project from design to production, your project must be the answer to a clear organizational need. Before you even think about the data, go out and talk to the people in your organization whose processes or whose business you aim to improve with data (beyond simply using spreadsheets). Then, sit down to define a timeline and concrete key performance indicators. I know, planning and processes seem boring, but, in the end, they are an essential first step to kickstart your data initiative!
If you’re working on a personal project or playing around with a dataset or an API, this step may seem irrelevant. It’s not. Simply downloading a cool open dataset is not enough. In order to have motivation, direction, and purpose, you have to identify a clear objective of what you want to do with data: a concrete question to answer, a product to build, etc.
Step 2: Get Your Data
.jpg?width=94&height=94&name=GM3385%20Graphic%20v2%20(4).jpg) Once you’ve gotten your goal figured out, it’s time to start looking for your data, the second phase of a data analytics project. Mixing and merging data from as many data sources as possible is what makes a data project great, so look as far as possible.
Once you’ve gotten your goal figured out, it’s time to start looking for your data, the second phase of a data analytics project. Mixing and merging data from as many data sources as possible is what makes a data project great, so look as far as possible.
Here are a few ways to get yourself some usable data:
Connect to a database: Ask your data and IT teams for the data that’s available or open up your private database and start digging through it to understand what information your company has been collecting. Some tools, like Dataiku, also offer data catalogs that have curated lists of data that can be used in your projects that’s already been approved and connected.
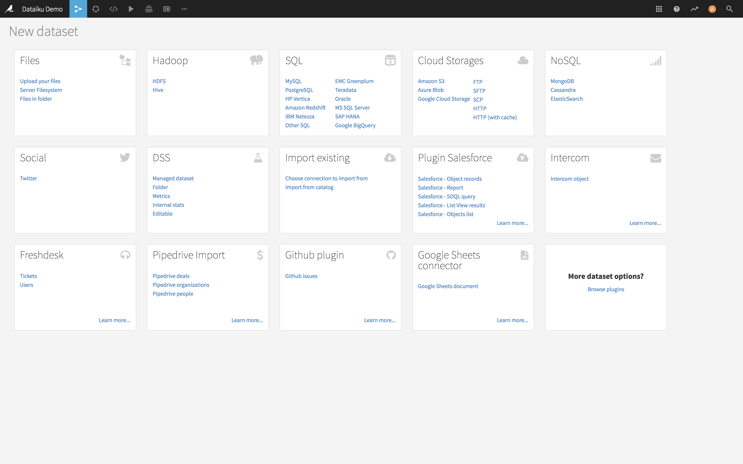
Dataiku’s project dashboard offers several options for creating a new dataset, including by connecting to your existing databases.
Use APIs: Think of the APIs to all the tools your company’s been using and the data these guys have been collecting. You have to work on getting these all set up so you can use those email open and click stats, the information your sales team put in Pipedrive or Salesforce, the support ticket somebody submitted, etc. If you’re not an expert coder, plugins in Dataiku give you lots of possibilities to bring in external data!
Look for open data: The internet is full of datasets to enrich what you have with additional information. For example, census data will help you add the average revenue for the district where your user lives or OpenStreetMap can show you how many coffee shops are on a given street. A lot of countries have open data platforms (like data.gov in the U.S.).
Step 3: Explore and Clean Your Data
The next data science step is the dreaded data preparation process that typically takes up to 80% of the time dedicated to a data project.
-1.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(4)-1.jpg) Once you’ve gotten your data, it’s time to get to work on it in the third data analytics project phase. Start digging to see what you’ve got and how you can link everything together to achieve your original goal. Start taking notes on your first analyses and ask questions to business people, the IT team, or other groups to understand what all your variables mean.
Once you’ve gotten your data, it’s time to get to work on it in the third data analytics project phase. Start digging to see what you’ve got and how you can link everything together to achieve your original goal. Start taking notes on your first analyses and ask questions to business people, the IT team, or other groups to understand what all your variables mean.
The next step (and by far the most dreaded one) is cleaning your data. You’ve probably noticed that even though you have a country feature, for instance, you’ve got different spellings, or even missing data. It’s time to look at every one of your columns to make sure your data is homogeneous and clean.
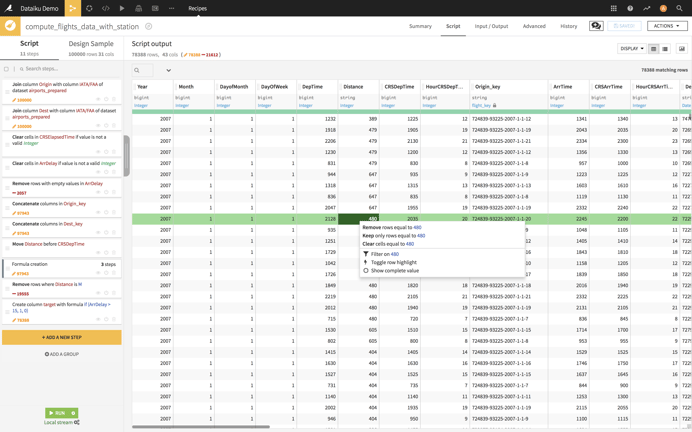
What spreadsheets won’t tell you: Dataiku gives you a comprehensive view of the cleanliness of your data, allowing you to find the data points that need attention before building your models.
Warning! This is probably the longest, most annoying step of your data analytics project. It's going to be painful for a little bit, but as long as you keep focused on the final goal, you’ll get through it. To make it easier, Dataiku’s AI Prepare or generate recipe allows people with the widest possible range of skills to build production-ready data transformations, simply by typing what they want done to their data. This breaks down the last barriers between knowing what needs to be done and making it happen in enterprise databases and cloud environments.
Finally, one crucially important element of data preparation not to overlook is to make sure that your data and your project are compliant with data privacy regulations. Personal data privacy and protection is becoming a priority for users, organizations, and legislators alike and it should be one for you from the very start of your data journey. In order to execute privacy compliant projects, you’ll need to centralize all your data efforts, sources, and datasets into one place or tool to facilitate governance. Then, you’ll need to clearly tag datasets and projects that contain personal and/or sensitive data and therefore would need to be treated differently.
Step 4: Enrich Your Dataset
.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(6).jpg) Now that you have clean data, it’s time to manipulate it in order to get the most value out of it. You should start the data enrichment phase of the project by joining all your different sources and group logs to narrow your data down to the essential features. One example of that is to enrich your data by creating time-based features, such as:
Now that you have clean data, it’s time to manipulate it in order to get the most value out of it. You should start the data enrichment phase of the project by joining all your different sources and group logs to narrow your data down to the essential features. One example of that is to enrich your data by creating time-based features, such as:
- Extracting date components (month, hour, day of the week, week of the year, etc.)
- Calculating differences between date columns
- Flagging national holidays
Another way of enriching data is by joining datasets — essentially, retrieving columns from one dataset or tab into a reference dataset. This is a key element of any analysis, but it can quickly become a nightmare when you have an abundance of sources. Luckily, some tools such as Dataiku allow you to blend data through a simplified process, by easily retrieving data or joining datasets based on specific, fine-tuned criteria.
When collecting, preparing, and manipulating your data, you need to be extra careful not to insert unintended bias or other undesirable patterns into it. Indeed, the data that is used in building machine learning models and AI algorithms is often a representation of the outside world, and thus can be deeply biased against certain groups and individuals. When you train your model on biased data, it will interpret recurring bias as a decision to reproduce and not something to correct. Perhaps it’s no surprise that, according to a survey done by Dataiku and Databricks, 53% of AI Leaders report that fears around AI are justified and are more worried than excited about the future of AI.
This is why an important part of the data manipulation process is making sure that the used datasets aren’t reproducing or reinforcing any bias that could lead to biased, unjust, or unfair outputs. Accounting for the machine learning model’s decision-making process and being able to interpret it is nowadays as important a quality for a data scientist, if not even more, as being able to build models in the first place.
Step 5: Build Helpful Visualizations
.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(7).jpg) You now have a nice dataset (or maybe several), so this is a good time to start exploring it by building graphs. When you’re dealing with large volumes of data, visualization is the best way to explore and communicate your findings and is the next phase of your data analytics project.
You now have a nice dataset (or maybe several), so this is a good time to start exploring it by building graphs. When you’re dealing with large volumes of data, visualization is the best way to explore and communicate your findings and is the next phase of your data analytics project.
Dataiku’s powerful visualization tools give you a whole new view onto your model outputs — making your insights more shareable in the process.
The tricky part here is to be able to dig into your graphs at any time and answer any question someone would have about a given insight. That’s when data preparation comes in handy: You’re the guy or gal who did all the dirty work, so you know the data like the palm of your hand! If this is the final step of your project, it’s important to use APIs and plugins so you can push those insights to where your end users want to have them.
Graphs are also another way to enrich your dataset and develop more interesting features. For example, by putting your data points on a map you could perhaps notice that specific geographic zones are more telling than specific countries or cities.
Step 6: Get Predictive
.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(8).jpg) The next data science step, phase six of the data project, is when the real fun starts. Machine learning algorithms can help you go a step further into getting insights and predicting future trends.
The next data science step, phase six of the data project, is when the real fun starts. Machine learning algorithms can help you go a step further into getting insights and predicting future trends.
By working with clustering algorithms (aka unsupervised), you can build models to uncover trends in the data that were not distinguishable in graphs and stats. These create groups of similar events (or clusters) and more or less explicitly express what feature is decisive in these results.
More advanced data scientists can go even further and predict future trends with supervised algorithms. By analyzing past data, they find features that have impacted past trends, and use them to build predictions. More than just gaining knowledge, this final step can lead to building entirely new products and processes.
In this step you may also want to utilize large language models (LLMs) for generative AI applications. These can be used for categorization, summarization, sentiment analysis, and even unstructured data use cases. Visual recipes for generative AI in Dataiku mean that this groundbreaking new technique is accessible to advanced data scientists and analysts alike.
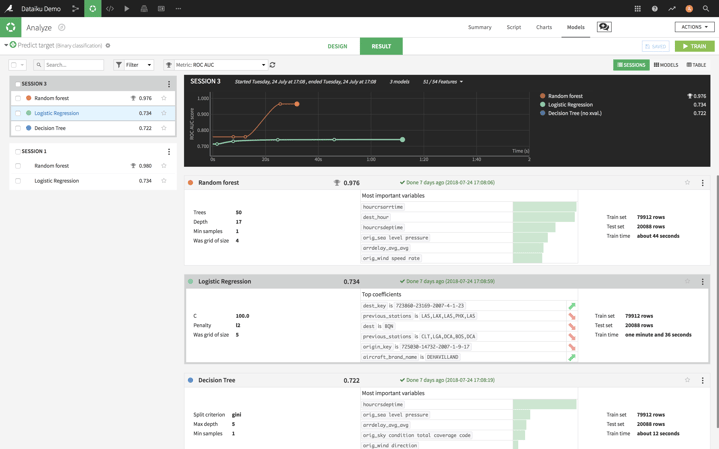
Follow your model as it learns: Take advantage of machine learning capabilities and get a real-time view into the coefficients your model is using to make predictions.
Even if you’re not quite there yet in your personal data journey or that of your organization, it’s important to understand the process so all the parties involved will be able to understand what comes out in the end.
Finally, in order to garner real value from your project, your predictive model must not sit on the shelf; it needs to be operationalized. Operationalization simply means deploying a machine learning model for use across an organization. Operationalization is vital for your organization and for you to realize the full benefits of your data science efforts.
Step 7: Iterate, Iterate, Iterate
.jpg?width=80&height=80&name=GM3385%20Graphic%20v2%20(9).jpg) The main goal in any business project is to prove its effectiveness as fast as possible to justify, well, your job. The same goes for data projects. By gaining time on data cleaning and enriching, you can go to the end of the project fast and get your initial results. This is the final phase of completing your data analytics project and one that is critical to the entire data life cycle.
The main goal in any business project is to prove its effectiveness as fast as possible to justify, well, your job. The same goes for data projects. By gaining time on data cleaning and enriching, you can go to the end of the project fast and get your initial results. This is the final phase of completing your data analytics project and one that is critical to the entire data life cycle.
One of the biggest mistakes that people make with regard to machine learning is thinking that once a model is built and goes live, it will continue working as normal indefinitely. On the contrary, models will actually degrade in quality over time if they’re not continuously improved and fed new data.
Ironically, in order to successfully complete your first data project, you need to recognize that your model will never be fully “complete." In order for it to remain useful and accurate, you need to constantly reevaluate, retrain it, and develop new features. If there's anything you take away from these fundamental steps in analytics and data science, it is that a data scientist’s job is never really done, but that’s what makes working with data all the more fascinating!