




AI is revolutionizing the healthcare and pharmaceutical industry, from drug discovery all the way to clinical decision making in doctors’ offices. However, these algorithms can be complex and even entirely black box, making it hard for us to determine exactly how models reach their unique decisions. As we also become increasingly aware of biases in institutions such as healthcare (e.g., systemic racism, sexism, or intersectional bias), and as we see these biases impact algorithms in this space, how far can we trust these emerging technical systems in healthcare settings?
Veena Calambur, Data Science Manager at Pfizer responsible for building out ethical AI frameworks, recently joined us for the Dataiku Product Days session, Utilizing Dataiku to Scale AI Ethics With Pfizer, to explore that hot question — “Can we trust artificial intelligence in healthcare?” — and to tell us about the ways that Pfizer is navigating the AI ethics conversation with Dataiku. Algorithm fairness and transparency are primary priorities for AI ethics at Pfizer, and they have built out an AI Ethics Toolkit which utilizes Dataiku for bias detection, bias mitigation, and model transparency.


Bias Detection
To begin with model evaluation, the data science team at Pfizer starts at the core by asking questions about representation or lack thereof in the data. A critical first step in bias detection is identifying the various factors that lead to unrelated outcomes which stray from original targets. After identification, the next step is to understand the structural or institutional reasons that these phenomena may occur.
For example, you could observe patients missing from a certain demographic in your healthcare data regarding propensity and risk for a disease. This leads to questioning whether they are naturally less likely to acquire a particular disease or if it is that the group has lower access to healthcare leading to selection bias or survivorship bias which ultimately affects how the algorithms learn. Ideally, this bias should be detected early in the exploratory phase to prevent long-term impact.
The data science team at Pfizer utilizes Dataiku’s Interactive Statistics for EDA to paint a broad picture of what is going on in the data from beginning to end. Veena’s team has also developed Dataiku plugins such as an odds and disparate impact ratio calculator to quantify target outcome differences in the data.
They look at things like odds ratios which measure the strength of association between two events (i.e., the strength of association between target outcomes and different feature values of their data). Disparate impact ratio compares the relative likelihood of the target outcome occurring across different groups, usually to compare privileged groups versus underprivileged groups. These measurements allow data scientists to understand patterns of target behavior and outcomes long before training a model, and Dataiku’s platform makes it easy to explore with the team’s chosen plugins.
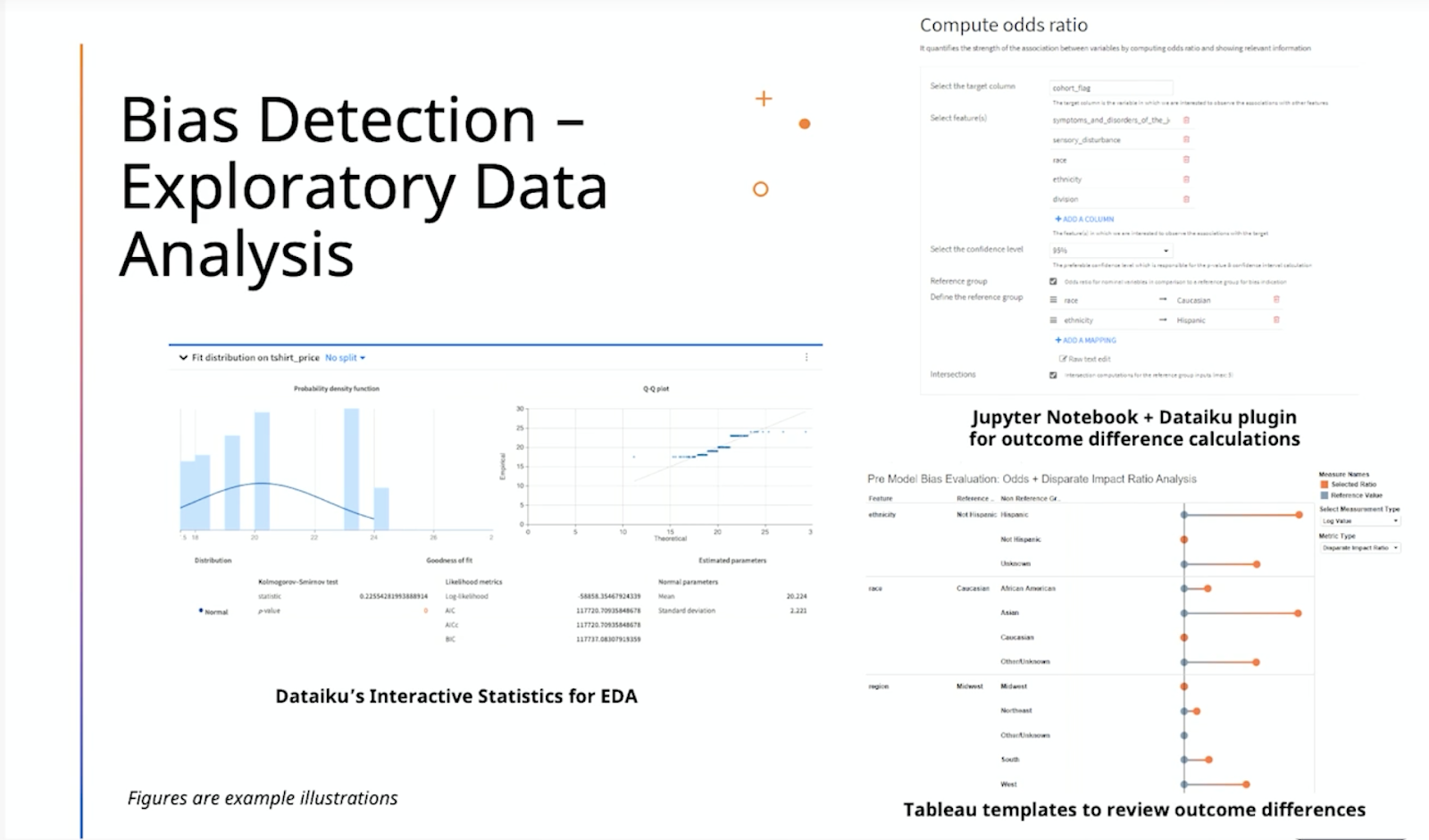
Once the EDA process is complete and a model is trained, it is really important to understand if any potential bias has been exacerbated in model building. Algorithms try to devise the best ways to differentiate between groups and any factor that can cause a differentiation will often be amplified by the algorithm as a part of its learning objective. Therefore, data science teams always need to be mindful that including things in the demographics of their data that will later be trained in the model could possibly further exacerbate outcomes that it doesn’t need to.
Data scientists use Dataiku’s subpopulation analysis within the visual model suite as a way to quickly understand and break down model performance consistency by different variables. The end goal is identifying, with reasonable confidence, who models work for and who they do not work as well for and then sharing those results directly with data scientists as they evaluate models.

Bias Mitigation
The next step after identifying areas of bias is determining what to do about it. The ethical AI team at Pfizer has looked towards more traditional social science as a primary form of bias mitigation, through matching algorithms. Historically, matching algorithms have been used in cases for observational studies, such as case control studies or cohort studies. The objective of matching is to minimize population differences that receive different treatments to try to closely mimic randomized control experiments.
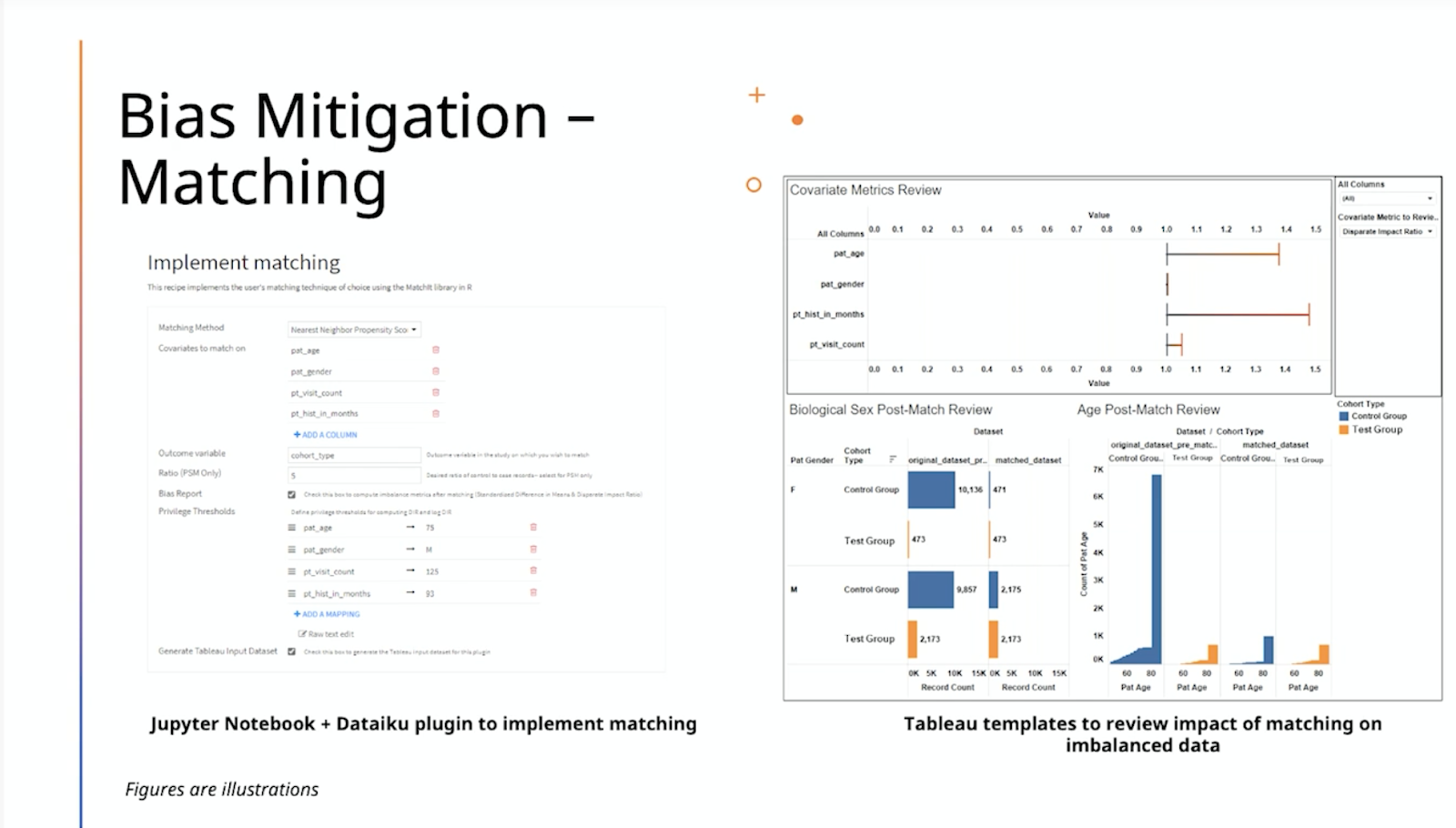
{kind=link}
Model Transparency
To build trust with emerging AI systems, the final step in the AI ethics toolkit is to explore model transparency. As AI becomes more and more embedded into modern healthcare, it becomes crucial for us to understand how models reach their final decisions. The ethical AI team at Pfizer uses key questions to clarify and guide the role of model transparency in any given analysis:
- Do your end users need to understand why the model is making the decisions it is?
- Will your model be published, released, or deployed (internally or externally)?
- Will your model be used to influence a person’s or a group’s decision-making (i.e., patient-related care, business strategy, process management)?
There are typically approaches we see repeatedly when it comes to explainable AI:
- Full population explanations allow data scientists to determine the main factors that drive predictions over the entire population the model was trained on.
- Individual explanations reveal what the main factors driving a prediction are and the confidence score of those predictions.
- Subpopulation explanations allow scientists to determine if the main factors driving the predictions are consistent across subpopulations.
Dataiku has individual explanation algorithms already implemented in the Dataiku visual suite. After you’ve trained a model you can spot check the individual explanations and you can leverage the scoring recipe in Dataiku as well. One thing to take note of it is that these are model-agnostic approximations. We may not know how well a given explanation will actually fit to an individual record in a real-world application, as it is just an approximation. Alongside Dataiku, data scientists at Pfizer use a method called BayesLIME, an open source library, which takes a LIME algorithm and puts a Bayesian framework on it. This lets data scientists identify how many approximations are needed to derive a solid explanation, essentially drawing up a confidence interval (a credible interval in Bayesian statistics).
Regardless of approach, at the end of the day, no matter how well a model works for the general population or even a subsegment, an individual is only going to care about how the model works for or impacts them.
The Takeaway
It is difficult to definitively answer the question of whether or not we can fully trust AI in healthcare. However, we can be certain that there are important steps to take and tools to employ which allow organizations to effectively scale AI ethics. We have seen this clearly demonstrated through Pfizer’s AI Ethics Toolkit that utilizes Dataiku.
Disclaimer: The views and opinions expressed in this presentation and any related discussion(s) are solely those of the individual presenter(s) and may not express the views of and opinions of Pfizer Inc.