




There are many ways to achieve scale in artificial intelligence (AI) and machine learning (ML) — scale up, scale out, elastic scale. Highly scalable infrastructure and data architecture are critical. However, the real secret to AI scaling lies in the design of your AI platform.
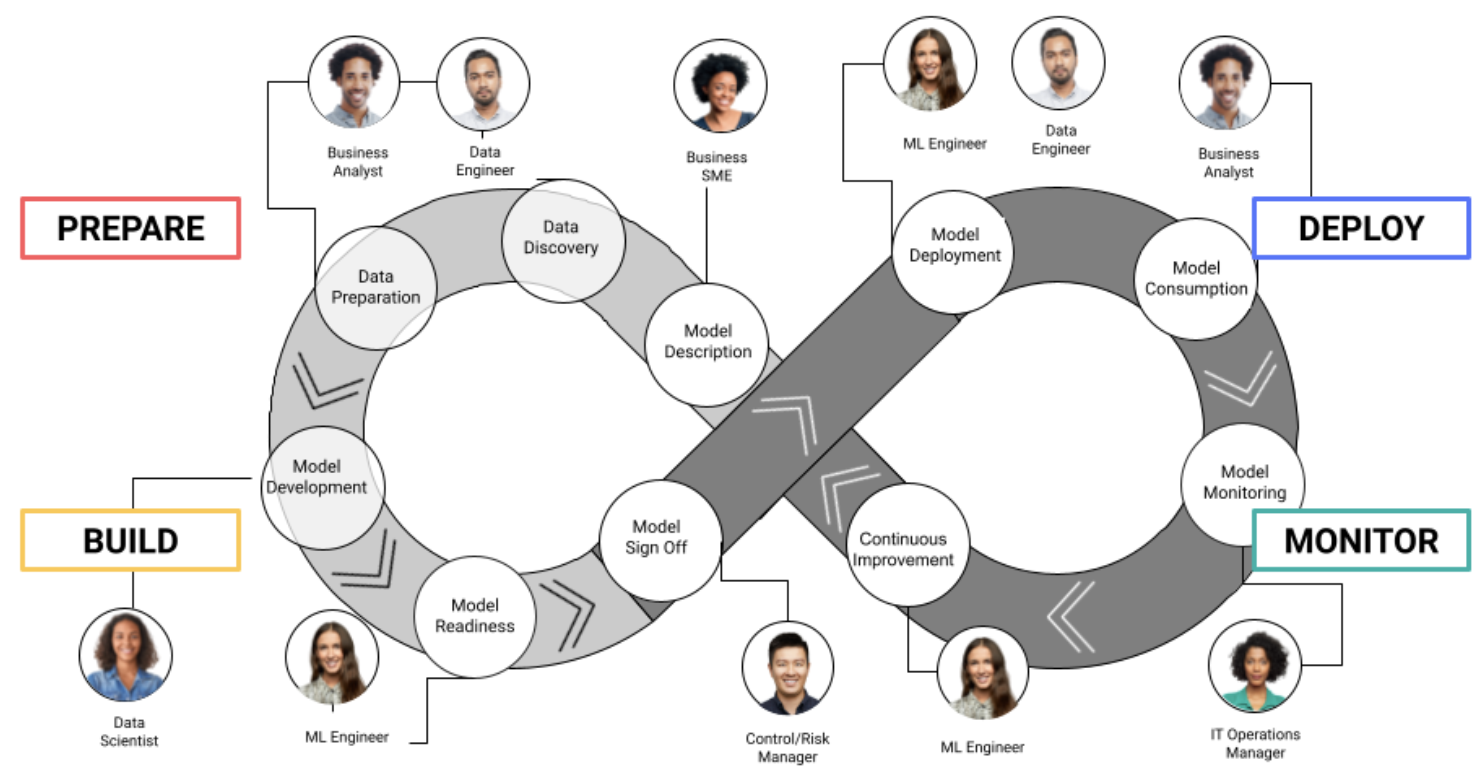
While highly scalable infrastructure is critical, the secret to scaling AI lies in the design of your AI platform and how it scales at each of the major steps in the AI/ML lifecycle, notably Prepare, Build, Deploy and Monitor (which we’ll discuss in more detail below). For IT/cloud architects and analytics leaders, scaling at the right time in the right way is critical to enabling your data science teams.

In Dataiku, each of these stages has dedicated environments that help scale at each step in the life cycle. Scaling in this way enables teams — business analysts, data engineers, data scientists, ML engineers, and IT operations — with a highly performant elastic AI stack for their individual stage in the process and also optimizes the entire AI/ML lifecycle.
Scale Data Preparation
The data preparation phase in AI/ML is where we prepare data for modeling. It includes:
- Data acquisition
- Data discovery
- Data visualization
- Transformations and shaping the data
- Feature selection
- Pre-processing
- Exploratory analysis
Scalability in this context begins with the ability to work with larger datasets as well as more types of datasets. However, with access to massive amounts of data in cloud data warehouses and data lakes, maintaining performance is challenging.
Dataiku has pre-built connections to all the major cloud petabyte and exabyte storage. This includes databases, cloud data warehouses, and blob storage. The platform takes an innovative approach (pushdown execution) to preparing these massive data volumes for modeling.
Whether data is structured, semi-structured, or unstructured, users can choose the most effective engine (local, in-database, or Spark). Pushdown workloads can be executed efficiently in elastic cloud compute clusters or in-database. But, more importantly, Dataiku maintains accessibility to your data no matter the size of your dataset. This means that no matter what, users view and work with data through the same interface.
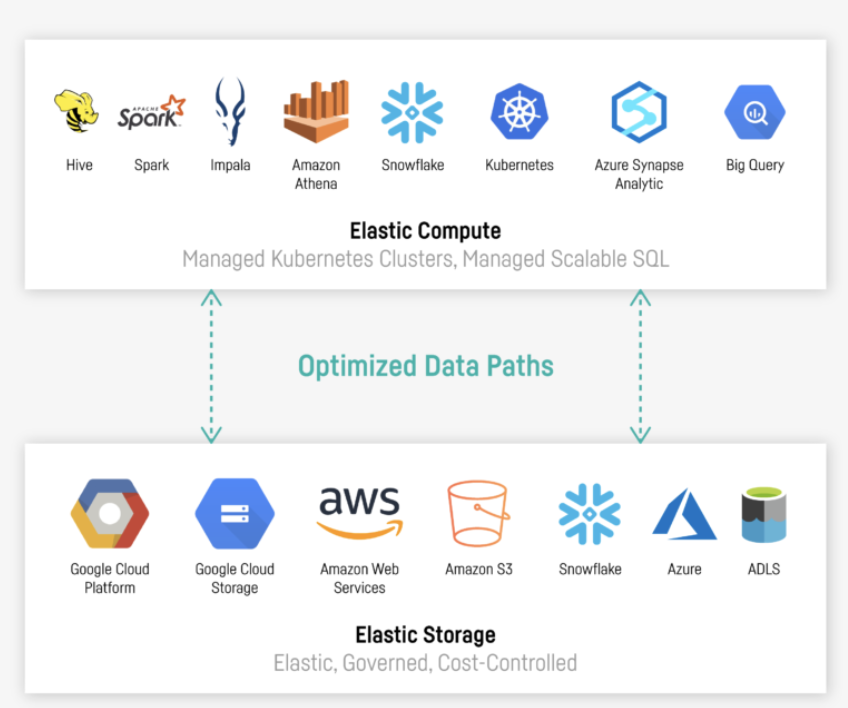
Pushdown also helps optimize the runtime for Dataiku projects. When running on Spark or a SQL database, a long chain of recipes (data preparation tasks) can be executed without building intermediate output.
This helps teams avoid cycles of reading and writing data at each intermediate step. It also reduces or eliminates data movement over the network. Business analysts, data engineers, and others involved in the data preparation phase benefit from the speed of processing with Dataiku. Bonus: They can also take advantage of powerful, built-in data transformers and more handy tools to speed up their work.
Scale Model Experimentation & Training
Scale takes on another dimension when we move into the experimentation and model building phase of an AI/ML project. This process is inherently iterative, which means it is essential to reduce the associated time and expenses.
The requirements to scale training mostly rely on computational power and model parallelization/distributed compute. Dataiku contains a powerful AutoML engine that allows you to get highly optimized models with minimal intervention.
Data scientists appreciate the added speed for model development with a distributed hyperparameter search on Kubernetes for performing grid search. When grid search is not the best strategy, you can use advanced search strategies like random search and Bayesian. In addition to AutoML, Dataiku also enables users to write custom models using Python or Scala.
For training deep learning models, Dataiku provides a dedicated coding environment for defining a network architecture with Keras code. The training/scoring of Keras models can be run on CPU or GPU(s).
Dataiku natively supports the use of GPUs for training. If the Dataiku instance has access to GPU(s) — either locally or on your infrastructure via containers — you can use them to train the model. To train or score a model, at least one CUDA-compatible NVIDIA GPU is required.
Discussing GPUs in full is not the purpose of this particular post. However, here's a helpful discussion of when to use GPUs (or not) if you want to learn more.
Scale Production & Monitoring
Production model workloads tend to be transient and highly burstable. For example, real-time API calls might peak because of increased demand from a marketing campaign. Batch scoring might happen on a trigger or schedule and need to complete the job in a specific timeframe.
Each of these has different requirements for:
- Infrastructure (e.g., GPU vs CPU)
- Highly customized environments for execution
- Large compute (big data) capabilities
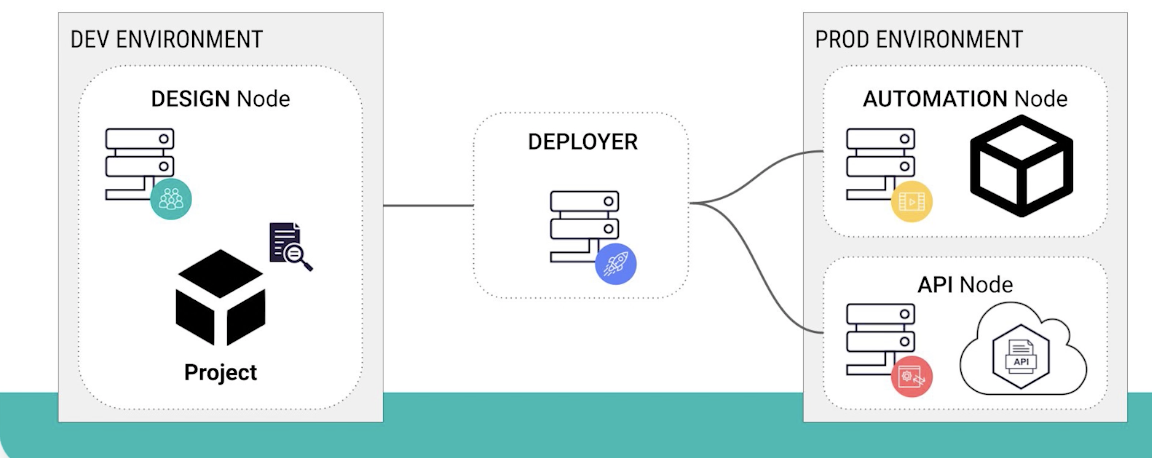
ML engineers and IT operations therefore require scalable deployment architecture. When dealing with operationalization, multi-node architecture is a must. Dataiku has:
- A design node where workloads for data prep and model training are managed.
- An automation node where batch and real-time scoring are managed. Adding additional Automation nodes is made simple with cloud stack accelerator, a clickable interface for deploying Dataiku instances in the cloud.
- An API node for operationalizing models. API nodes are horizontally scalable and highly available web servers and often deployed on auto-scaling Kubernetes clusters. Customers can scale out by deploying as many API nodes as required to meet their scaling requirements or SLAs.
{kind=link}
Dataiku's architecture enables scale with self-service deployment. It also speeds the process of model inference and monitoring, replacement, and redeployment within its node architecture.
Dataiku leverages a fully-managed Kubernetes solution and can offload production workloads to compute clusters for elastically scaling to meet the needs of both batch and real-time scoring. Enterprises can scale workloads across multiple clusters. They can automatically scale up to meet the requirements of new load conditions as well as scale down to optimize costs.
In addition, the speed of scoring models can be increased significantly by pushing down into Snowflake using Java UDF batch scoring, for example. In one recent example, Snowflake achieved an 8x increase in scoring speed over environments like Spark leveraging Snowflake’s UDF capabilities.
Finally, Dataiku supports containerization. It is compatible with all of the major cloud container services. This includes Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), and Azure Kubernetes Service (AKS), as well as on-premises Kubernetes/Docker clusters.
Scalable AI With Dataiku
Getting value from AI requires the right scaling options and the right design elements for each stage of the life cycle. Dataiku enables various approaches to technical scale at each stage. At the same time, it hides much of the complexity of technical architecture for broader adoption among non-coders.
Business analysts, data engineers, data scientists, ML engineers, and IT operations can all achieve the AI capabilities they require with Dataiku. IT and cloud architects can enable their data science teams with a flexible, scalable, elastic AI stack spanning these teams. What's better than being able to facilitate scale independently, but sharing a common, collaborative platform?