




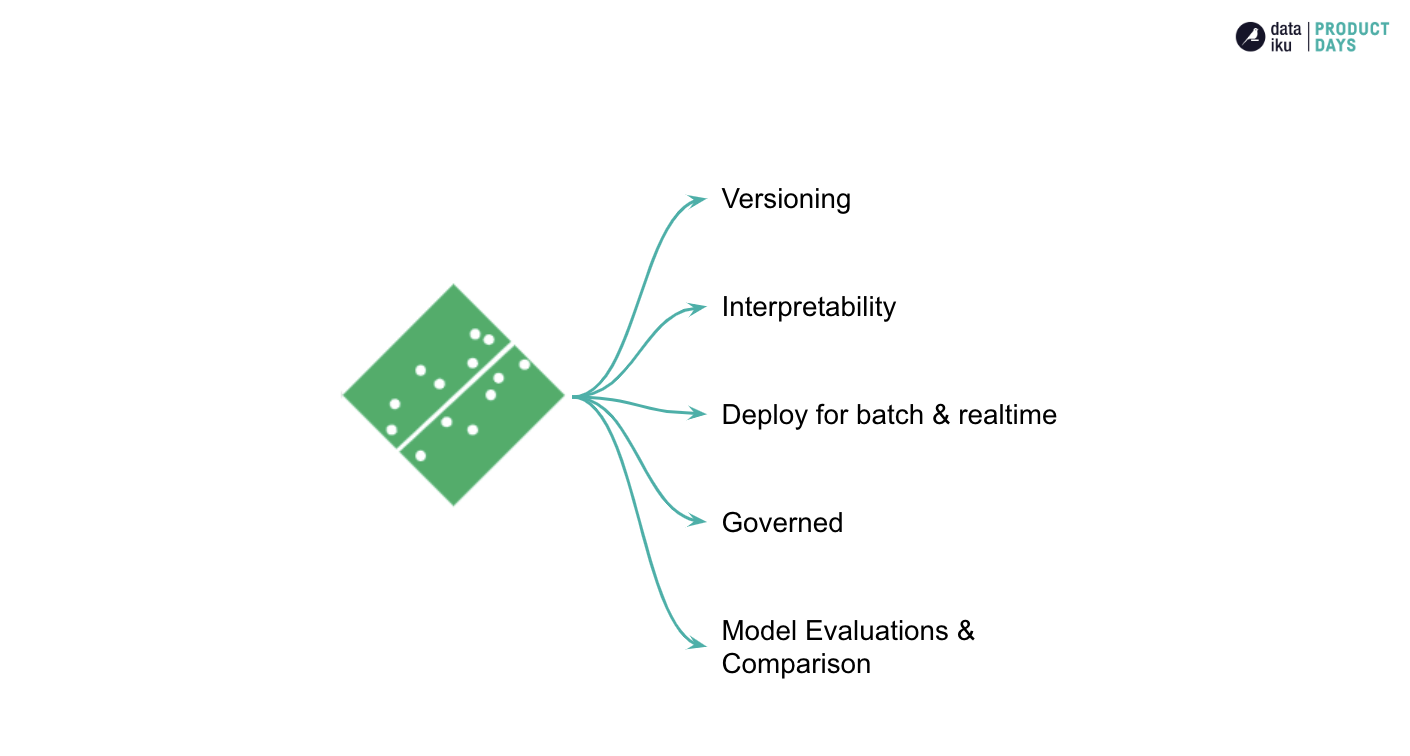
In a recent Dataiku Product Days session, we walked through an example of importing MLflow models as Saved Models in Dataiku, but no worries if you prefer a quick rundown written out. In this blog, we will outline the brief introduction to MLflow Saved Models that was covered in the session.  First, let’s chat about Saved Models in Dataiku. When you start with your dataset in Dataiku with the intention of building a model, you can go into the lab to create a visual analysis. In there, you are able to take your data and apply a variety of feature handling methods and processes as well as select different hyperparameters for your specific algorithms. You can then evaluate your models in order to assess model performance. Once you have selected the best candidate amongst your models, you can choose to deploy a model version to the flow. Et voilà! That’s what we call a Saved Model! Here you can recognize the saved model as the green diamond:
First, let’s chat about Saved Models in Dataiku. When you start with your dataset in Dataiku with the intention of building a model, you can go into the lab to create a visual analysis. In there, you are able to take your data and apply a variety of feature handling methods and processes as well as select different hyperparameters for your specific algorithms. You can then evaluate your models in order to assess model performance. Once you have selected the best candidate amongst your models, you can choose to deploy a model version to the flow. Et voilà! That’s what we call a Saved Model! Here you can recognize the saved model as the green diamond:
Why Saved Models in Dataiku Are a Hit
We’ve found that customers love how easy it is to go from that initial dataset to one of these Saved Models deployed on the flow. You get the opportunity to take advantage of model versioning, understand your important features with interpretability tools, assess fairness, and play out What-If scenarios. Dataiku also offers seamless deployment for batch and real-time inference across a variety of deployment architectures. Not to mention that all of this is governable, transparent, and auditable. So throughout the model lifecycle, you are assured that you have a clear understanding of how the model was developed, deployed, and continues to perform. As new data and labels come in, you have the opportunity to monitor data and performance drift, and also retrain models for comparison against your existing ones.
Another key feature that’s a huge attraction to the more code-inclined, advanced data scientists is the ability to extend what we have in visual machine learning (ML). When you’re working on the feature handling part of your ML pipeline, you have the ability to specify custom preprocessing — essentially, you are able to write your own function to prepare your variables exactly as you would like. Furthermore, you’re able to specify custom metrics and custom algorithms so that at no point are you bound or limited to what we have in visual ML. We know that no matter how open and extensively customizable a platform is for your ML pipeline, there will always be an appetite to be completely unbound by the framework that’s provided.
Up until now when you’ve worked in notebooks rather than within the customizable functionalities of visual ML, you’ve likely had to give up some of the out-of-the-box accelerators that we offer such as versioning, interpretability, seamless model deployment of real-time architectures, governance capabilities, and the ability to easily compare and continuously improve your work. So, we thought long and hard about what we could do to simplify the experience of training models outside of the Visual ML experience to see how we can bring to you some of these benefits you were missing out on.

Meet MLflow
What we have heard from talking to data scientists is that there are so many options that exist for training in terms of tools and frameworks, and equally as many options out there for deployment. It can be overwhelming, and there’s so much (tedious) complexity in writing all of the necessary glue code that it takes to go from one environment or framework to another. Luckily, MLflow provides some relief for these major pain points.
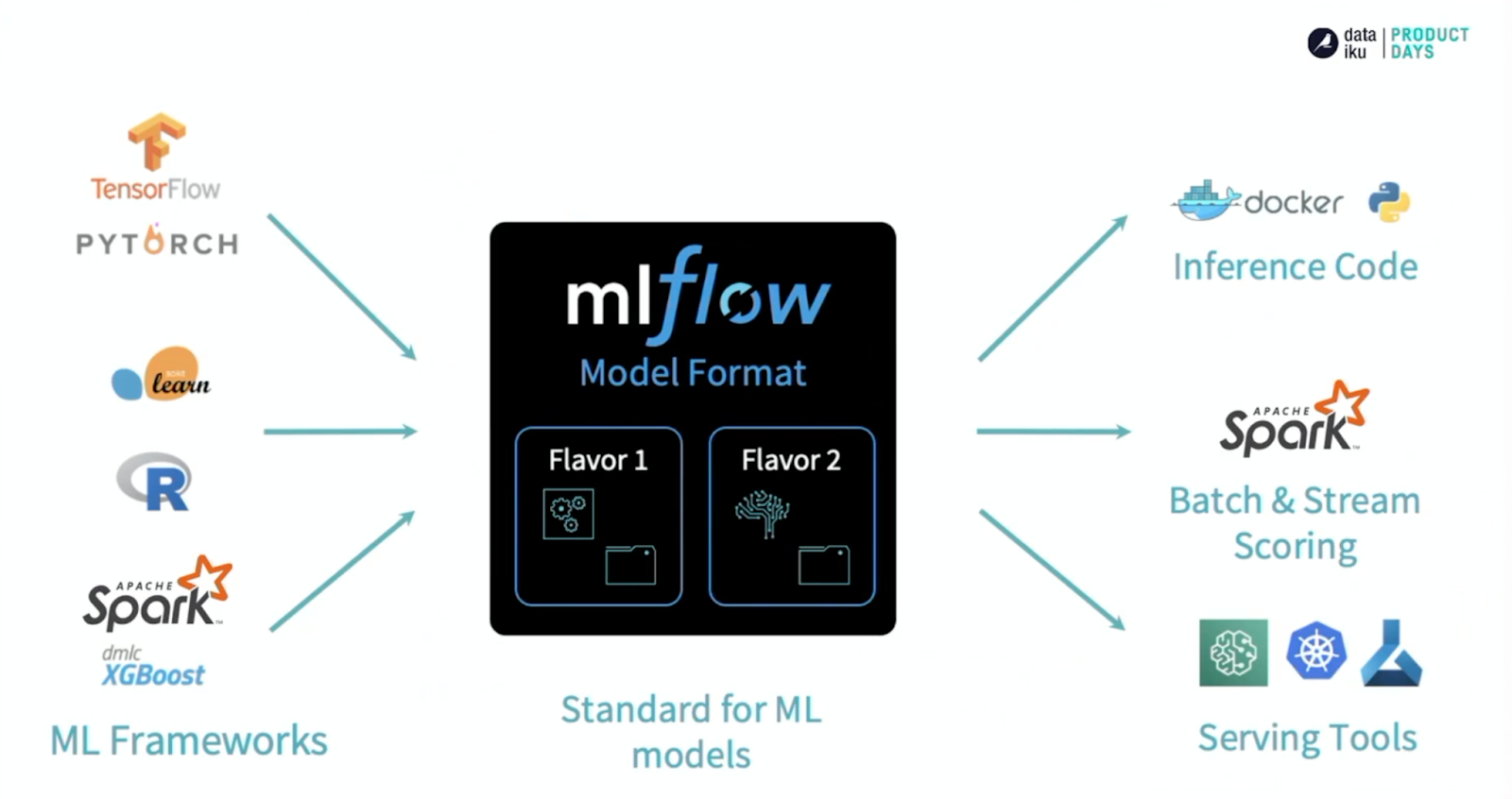
MLflow is an open source platform for managing the ML lifecycle. It has many interesting capabilities, but the one we focus on here is the idea of MLflow Models. The idea behind MLflow Models is simplifying the explosion that you get with heterogeneous training and serving infrastructure by standardizing the way that you package and save your trained models.
In one funnel, you can take models that have been developed across a variety of frameworks and store them in a consistent manner that can be understood by a variety of different serving infrastructures. This allows you to have seamless prediction and scoring functions available no matter which framework you chose to train your model in.
{kind=link}
What Does This Look Like?
A model saved the MLflow way is really just a directory. It has the brain behind your model — the artifact that contains the logic of the model and some metadata describing the configuration necessary to produce predictions from the model object(s). A key thing to note here is that these are just the artifacts related to a fitted model, i.e., something that you have trained. It is quite simple!
What you can do with this directory here is not only bring this into Dataiku as a saved model but use this for all of the infrastructure options that recognize the MLflow model format. The rich, interpretable, and interactive evaluations that can be taken from an MLflow Saved Model in Dataiku would take much more effort and a significant amount of glue code to produce if you were working in a notebook alone.
In Dataiku, you’re actually able to use our evaluate recipe and place the evaluations directly into a store so that they are readily available for comparison. You’re also able to take this model directly from the flow and utilize our familiar deployment and governance functionality. It is easy to create an API or incorporate model insights into business initiatives in Dataiku Govern.
Hopefully now you can clearly see some of the benefits of importing your custom Python models as MLflow Saved Models in Dataiku!