




{kind=link}
Deep learning has met increasing hype in the last few years, and with lots of practical success. But does that necessarily indicate an exponential growth in AI over the next few years?
A Parallel History
Amara's law, established by the futurologist Roy Amara, states: "We tend to overestimate the effect of technology in the short run and underestimate the effect in the long run."
In order to understand what’s to come, we need to figure out where we are exactly in the development of not only deep learning, but AI in general.
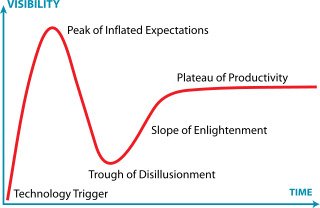
The Gartner Hype Cycle Curve
The Gartner hype curve gives some perspective about the adoption of a technology in the enterprise over a five- to 10-year perspective. But it is not clear that it’s the right model here — AI is not just yet-another-enterprise-technology, but rather a scientific domain on its own where the cycle is more in the 50 to 100-year range.
One way to look at AI is to stop considering it as an invention where we endlessly invent new techniques, but instead view it as more of a discovery where mankind is slowly (and quite empirically) discovering, step by step, the behavior of self-learning systems.
In that regard, we could compare the discovery of AI to scientific discoveries from the past, especially those related to complex systems: the solar system, evolution, electricity, … and why not the atom?
The overarching question I’ll try to answer with this little parallel history lesson is: Where is AI development? Is it already fairly advanced and close to maturity, or is it still as its infancy? Will our descendants in 30 years look back at this period of time and find our experiments in AI quite remarkable given our limited technological tools, but perhaps slightly naive or dangerous? Or another way to put it: Is Yann LeCun the new Richard Feymann, or the new Marie Curie, or both?
A Very Brief History of Nuclear Physics
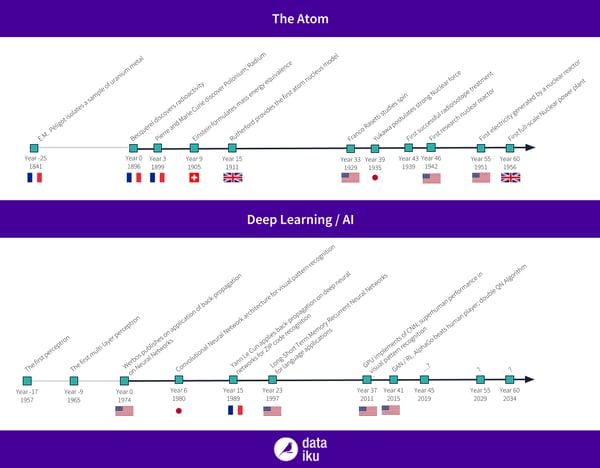
Radioactivity was discovered in 1897 by Becquerel. The discovery itself was quite accidental — Becquerel was originally studying the phosphorescence of uranium salts and their ability to emit x-rays when touched by light. He soon discovered that uranium was emitting x-rays without the need of an external energy source, et voilà.
Marie Curie took over his research and studied radioactivity more elaborately, and among other things, isolated other naturally radioactive compounds besides uranium. The discovery of radioactivity lead to public enthusiasm. We discovered a new substance that magically emits a new kind of beam: x-rays. It could give you superpowers! (Note that this was the pre-comics era, so superpowers was not the actual term used.)

In the meantime, radioactivity was a new phenomenon that needed to be explained by theoretical research and a better understanding of the atom itself. Einstein postulated the famous mass-energy equivalence in 1905, and Rutherford established the first model for the atom (with a nucleus and electron orbiting it) a few years after through an experiment where he bombarded metal sheets (usually gold) with electrons and looked at the collision trajectories.
It’s important to note that science stayed for a good fifteen years without a good model of what the atom actually was — the neutron was still unknown.

The “spin” model, which is still the modern perspective we have on the structuring of the atom, and the strong nuclear force, were only postulated in 1929 and 1935, respectively.
In continuation of this theoretical progress, the progress of engineering and chemistry allowed the refinement of radioactive compounds and their actual (beneficial) use. In 1939, the first successful cancer treatment using isotope happened. The first research nuclear reactor was created in 1942, leading to the first full-scale power plant in 1956.
Artificial Neural Networks: How It Began
Neural networks are old… very old. Like before Woodstock, old. The initial motivation was to write an algorithm that would mimic the (then-believed) behavior of synapse. The first perceptron was discussed in 1957 and the first multi-layer perceptron in 1965.
When the idea of neural networks emerged in the 60s, computers were very slow, so even very simple networks could take days to train. They were basically not as efficient as other techniques, so in the decades that followed, they weren’t used a whole lot.
But that did not prevent people from testing and thinking about properties. A first breakthrough was made by Werbos as he discovered back-propagation in 1974. Back-propagation used the very idea that the neural network operations are differentiable and investible, so when the network makes a mistake, you can back-track the error itself into the network’s various layers to help it self-correct.
Back-propagation marks a strong divergence between the artificial neural networks and biological neutrons — for which it’s not plausible that back-propagation exists (this paper by Yoshua Bengio & al. provides an introduction to that) — and is, in a sense, the beginning of deep learning as we call it today.
A few years after, Kunihiko Fukushima introduced the Neocognitron. This job was inspired by work on perception cells in the visual cortex, which are the introduction for what is called convolutional networks (CNNs) today.
Deep learning (and AI in general) went adrift for a few years due to the lack of actual applications for such technologies as well as a lack of trained data and computing power. Deep Learning was waiting for modern GPU (and Google).
Yann LeCun & Al: The Beam of Light

One first beam of light within the AI winter was Yann LeCun’s application of back-propagation and CNNs to identifying zip codes on letters for mail routing. And here’s the thing: It was working, and it was actually usable! But it would still take another good 20 years or so to actually make deep learning more mainstream.
The Three Gs: Google, GAN, & GPU
In 2014, Ian Goodfellow had a heated argument in a bar with colleagues from University of Montreal. They were discussing the ability to generate realistic images automatically and how to teach a neural network how do so. Ian’s crazy idea over beers was to have two neural networks “fight” against one another, with one network generating images, and the other “training” the first one.
His friends dismissed the idea (in a heated, slightly inebriated, argument). From the perspective of his friends, it could never work, for it would be like “training without substance” — after all, you can’t generate a network from “nothing.”
(Picture this: One century before, some physicists perhaps had similar heated arguments in a Parisian bar, arguing that radioactivity does not produce energy out of “nothing!”)
In a sense, it’s not clear why generative adversarial networks (GANs) — what we now know Goodfellow’s “fighting” neural network invention as — work. The theoretical reason why it’s a good idea to have two neural networks operating in parallel (as opposed to, let’s say, having a big neural network doing both tasks at the same time) is unclear. It’s still subject to debate, research, and controversy
GAN is one example of a learning technique that emerged in the last few years, but others include:
- Learning with exploration and curiosity. An issue with learning is that inherently, AI systems wouldn’t learn something new because they would tend not to explore enough possibilities. New techniques such as Random Network Distillation compensates for that by incentivizing networks to explore situations that are “hard to predict” (by another network). That’s neat, and it works (but not sure why).
- Deep Double Q-Learning (DDQN), where a deep learning network tries to learn a strategy (e.g., playing Atari Pong). Acting with a double network, each network separately evaluates whether a particular step is smart and interlinks results. Because with a single “brain,” you tend to be over-optimistic (that’s what my better half would tell me).
- YOLO (You Look Only Once) object detection algorithms, which detect objects in an image in an odd way. Instead of detecting object boundaries and then trying to recognize each object, the algorithm would “just” try to classify object parts in a given, fixed, grid. YOLO was the first algorithm enabling general object recognition at video (>40 frames per second) speed.
When you look at the various ideas (like back-propagation, CNN, GAN, RNN, LTSM, etc.) that were created around the basic neurons, it’s rather tempting to draw an analogy with the world of the atom. We’re playing with chemical concepts, and try to combine and recombine them in different ways, launch then on our GPUs, and wait to see if they shine in the night.
What Could the Future Look Like?
Let’s imagine what AI could look like in 20 or 30 years. Maybe we will have built some form of general AI — maybe not. The truth is that the answer to this question is beyond the scope of this simple blog post.
But let’s try to make some assumptions based on scientific discovery from the past and figure out what it will take to really make a significant advance with AI:
- We need more theory. Our current mental map of AI is similar to the nucleus model without the spin and neutron. Maybe research will build an applicable theory of learning that would contain drivers (such as curiosity, generalization) and mingle together those concepts in a theory of what can be learned.
- We need more engineering, and an engineering domain needs reusable components. You couldn’t build the nuclear industry without a common usage and reuse of parts and tools, starting with simple things such as an electrometer. In deep learning, embeddings, and reusable representations are becoming a trend but are still far from being super easy to use (notably, it’s still challenging to train, share, reuse, etc.). It’s like we’re missing the pipes and the rubber — the things that will enable us to plug and replug neural networks more automatically and that would have learned a piece of the puzzle. This is would be no small feat; but imagine at some point in the future neural nets that learned how to understand voice, the concept of good, color sentiment association, common aesthetic and preferences for the human body shapes, color harmony, etc. Imagine a practical application where you could then combine all these learned pieces to build a clothes shopping assistant.
- We need a wire into real life. The challenging engineering part with radioactivity was to make it useful in a controlled way. Not just get x-rays, but get actual, controlled electricity. For AI, the correspondent is a formal description of real-life elements. AI operates largely in the digital, not-real-world, and this limits some of its real-life application. Sensors, cameras, and carefully crafted human-machine interface fills the gap when you create domain-specific AI, like a car. But it leads to some limits in systems that are conceptually complex, for instance, a manufacturing process (whatever the process: making a hamburger or building a car). The process itself is not available in digital or logic form, making it impossible to apply AI simply. Some new emerging concepts, such as the “factory digital twin” go to the line of creating a virtual twin of a factory on which AI can operate to give insights on optimization. In the future, you could imagine that most business process (and software supporting them) could come with some “AI interface” that describes what the process or software is doing so that an AI can comprehend those processes and act upon them.
- We need hardware. Radioactivity was discovered at a time where even building an electrometer was a scientific breakthrough (that’s actually what Pierre Curie, Marie Curie’s husband, was doing). Will AI be developed on the current generation of hardware (including GPU and TPU) or will we need a new kind of hardware (quantum-based or related) to make it real?
Imagine that at least any two of the “predictions” above become true. How would AI specialist in 30 years look at us? The might think “They were plugging together neural networks without having a single clue of how it works” or “They were starting every project from scratch! What a nuisance!” or “Because they had no digital formalism for most things, they were kind of operating in fake world and trying to plug back results into real world, in an odd way,” or “Damn, they had no real hardware. I don’t understand how they managed to get things done with so little power! And I think that this famous scientist even built his own computer!” or “That’s funny, they were trying to patent different variations of learning diagrams, actually drawn on paper! Can you imagine that?”
So yes, they might look back at deep learning research from the early 21st century with some mix of admiration and surprise. And yes, maybe Yann LeCun is a new Marie Curie.