




MLOps is being increasingly practiced in the AI / ML space, and for good reason. While the exact MLOps practice could look different for each organization, one key component of all MLOps strategies is the ability to properly monitor models post-deployment and make subsequent model adjustments as needed.
Why does this matter? Inevitably, as data or business requirements change, models in production will need to be updated and tweaked accordingly to ensure that advanced analytics efforts continue driving business outcomes.
In particular, Champion/Challenger model evaluation is a well-known approach to comparing model performance in production. Let’s say that we’ve built a customer churn model and deployed it to production but, over time, the performance decreases. This signals a need to make a change so that the performance can be recalibrated — perhaps we could retrain the model on the newest available data or leverage an entirely new algorithm. Regardless, before we push changes to production, there should be a way to evaluate the existing deployment (Champion) against the new approach (Challenger).
Sample Champion/Challenger Project
Let’s walk through one way Dataiku can be used for Champion/Challenger evaluations. In this sample project that predicts customer churn, we have one model deployed into the production environment. There is a training dataset that was used to train the model, an unlabeled dataset that the model is predicting future values on, and a validation dataset that serves as a way to measure how well the model performs on unseen data over time. The Model Evaluation store measures this model’s performance with the freshest validation data, so it is best practice to have a validation dataset that is different from the training dataset.
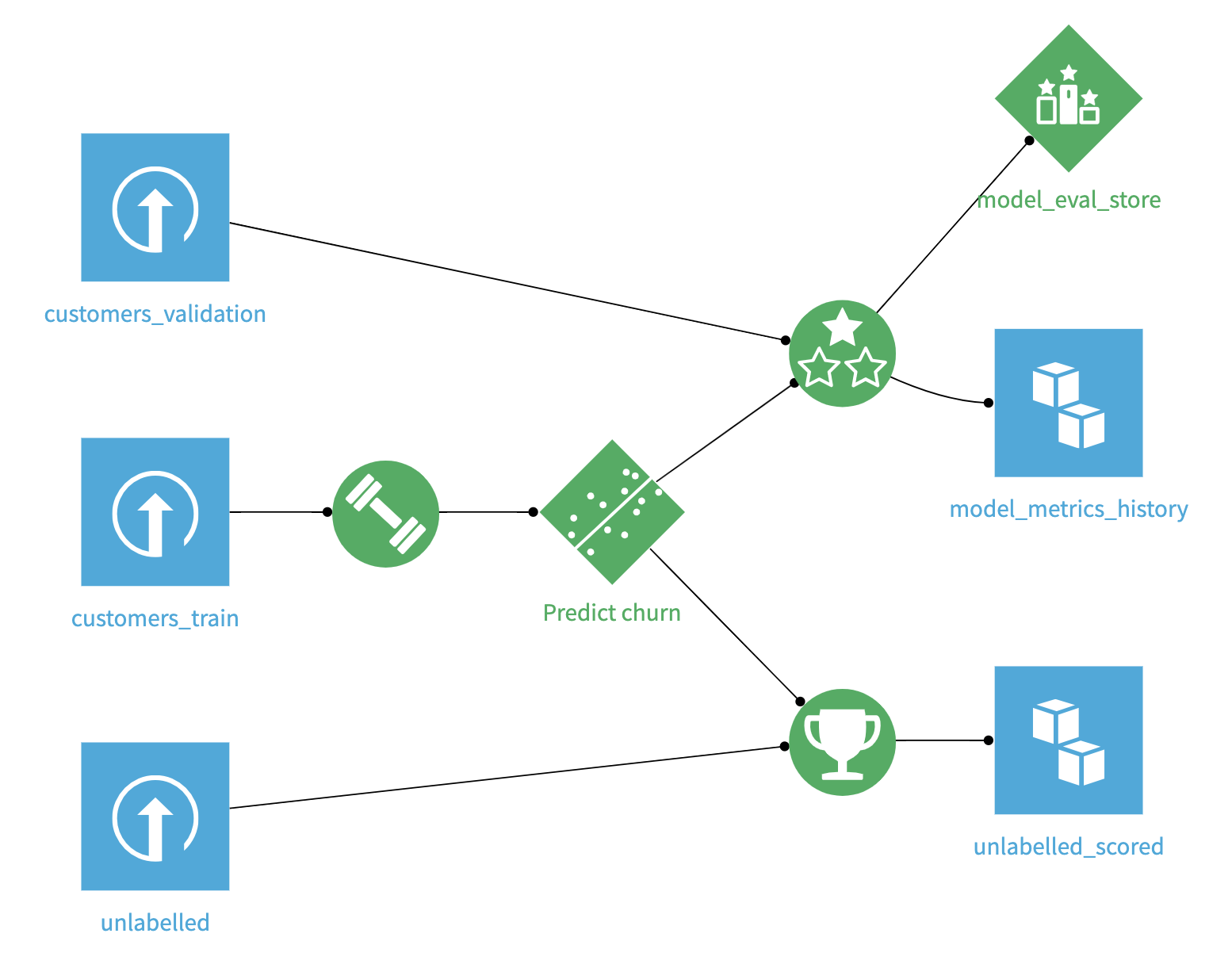
The currently active production model is an XGBoost model (Champion), but for our Champion / Challenger evaluation, we want to see how our newly developed random forest model (Challenger) compares.
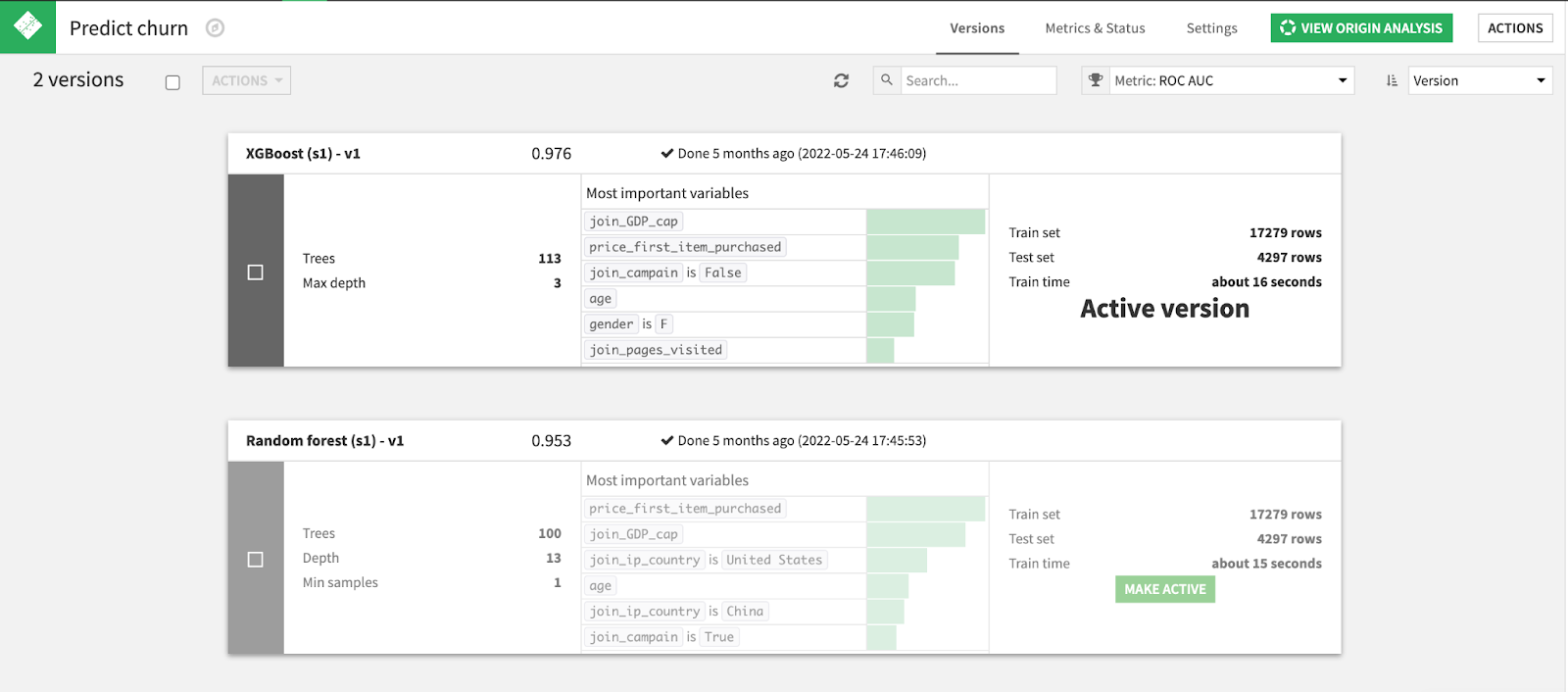
Champion / Challenger evaluations utilize shadow testing which means that, behind the scenes, the Challenger model is getting evaluated on the same data as the Champion model, and if the Challenger model indeed outperforms the Champion, only then should a production change be made.
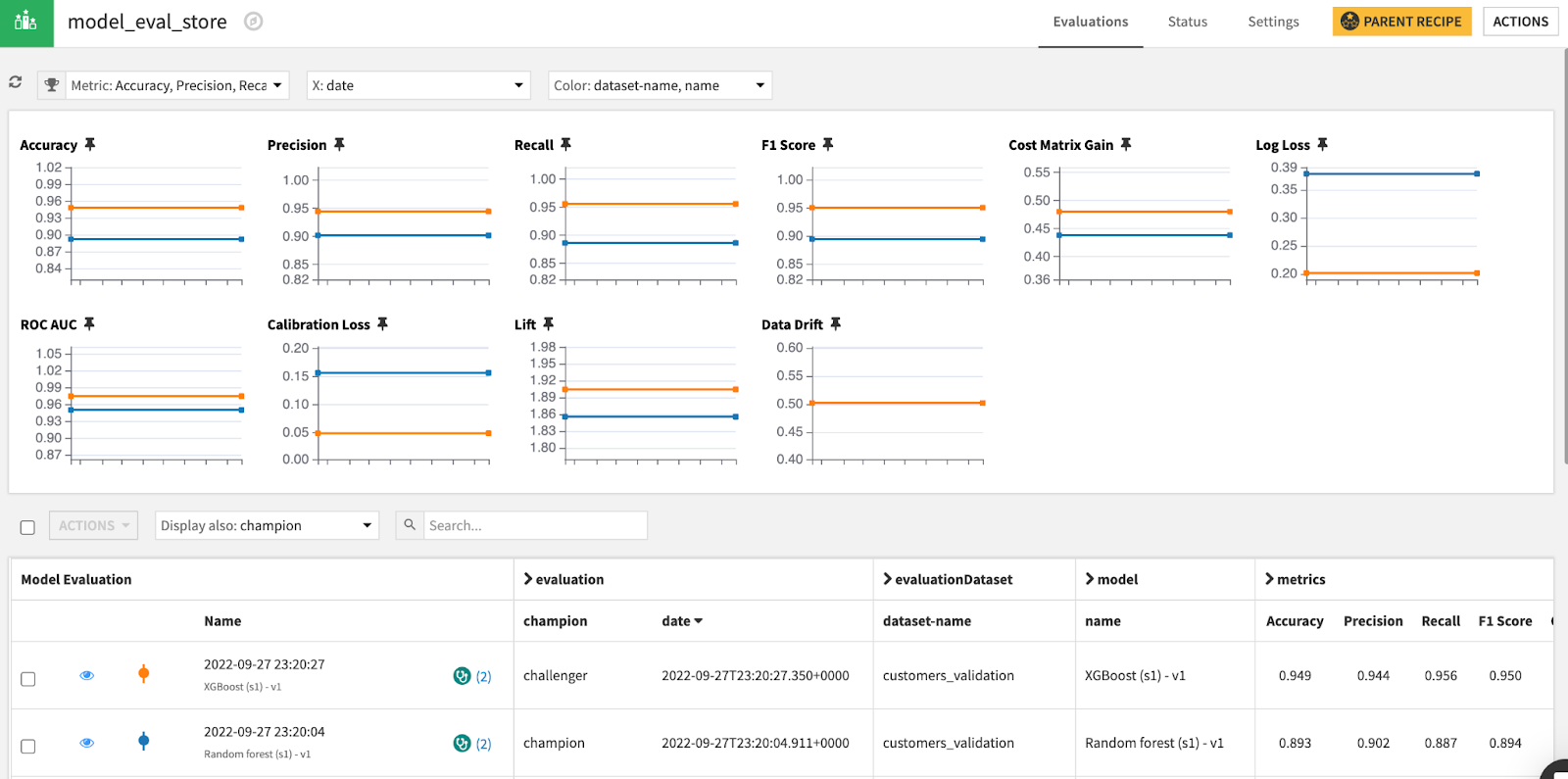
Let’s leverage Dataiku’s Model Evaluation Store, an interface that centralizes and tracks model performance over time by calculating performance metrics and data drift scores, to visually inspect the differences between the Champion and Challenger model performances. By evaluating both models against the same validation dataset, we can get an accurate comparison of performance. Immediately, we can see that the Challenger model performs better on all fronts. Dataiku’s Model Evaluation Store supports MLOps frameworks by enabling users to quickly detect trends or unwanted model behavior.
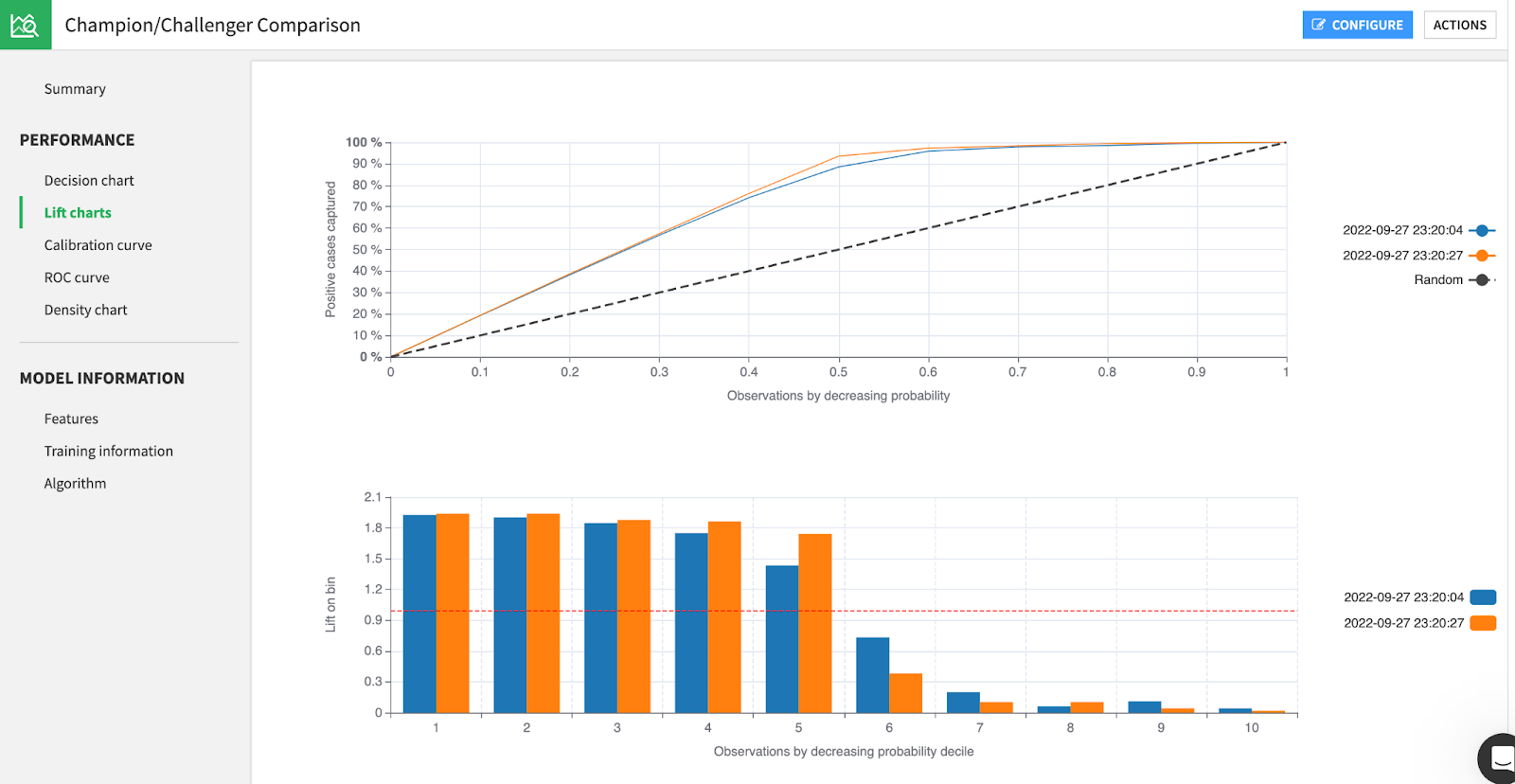
From this Evaluation Store, we can create a model comparison to get granular performance charts out of the box.
In addition to evaluating a model by performance metrics, it’s important that the model is ethical and is interpretable by the business decision makers. Dataiku aims to help organizations build trustworthy, transparent, and bias-free models through interactive what-if analysis, feature importance visualizations, and more.
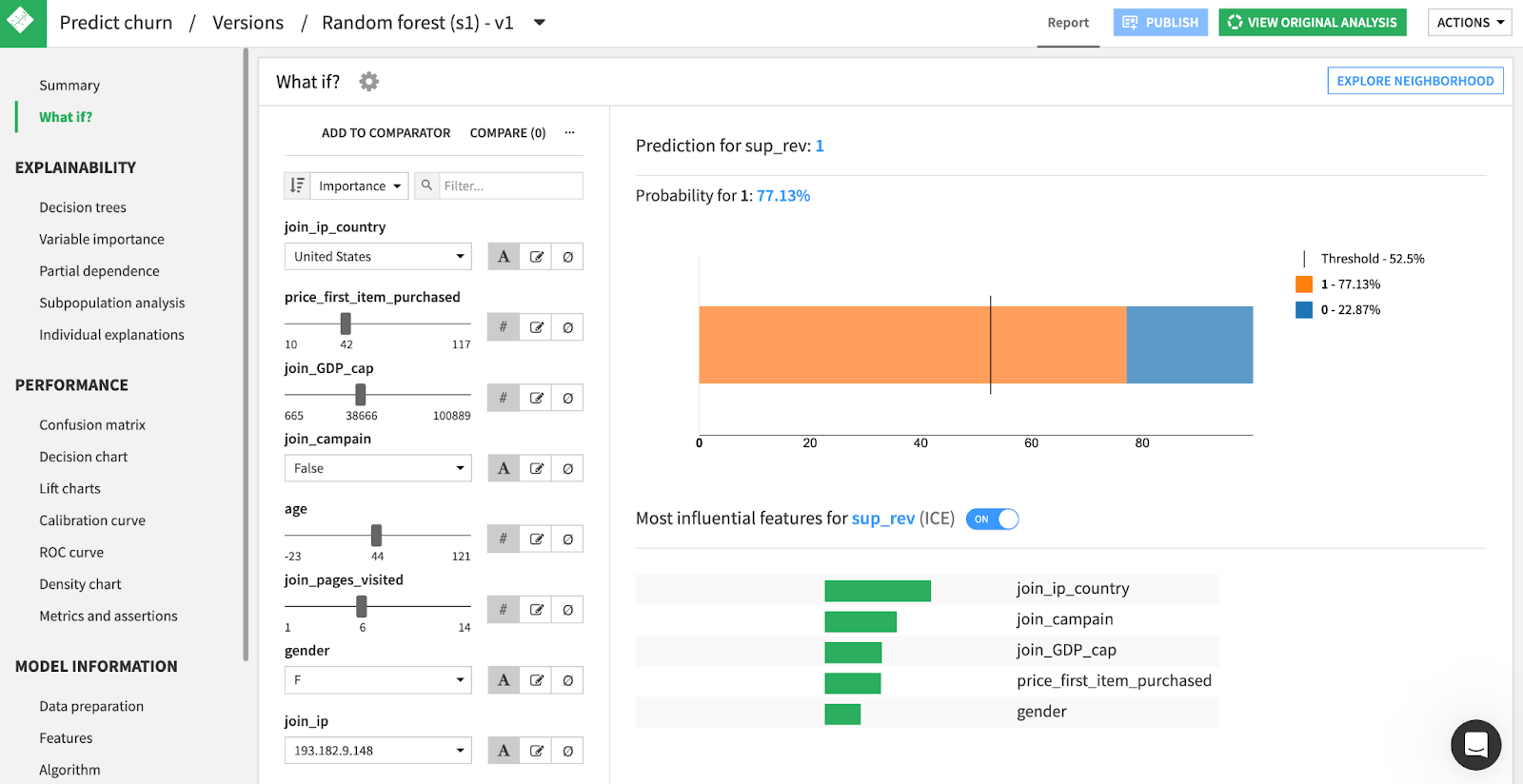
Automating Champion/Challenger Evaluations
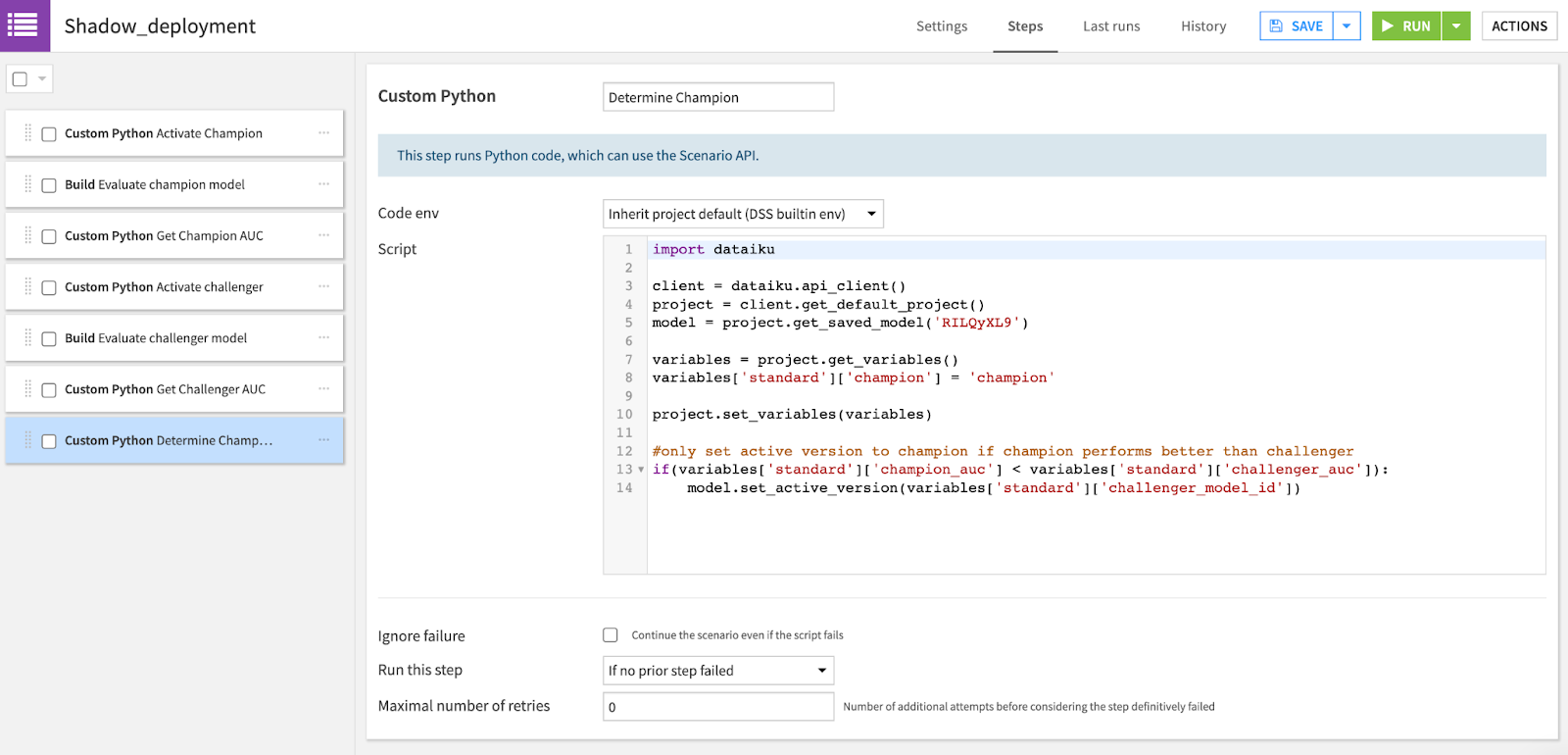
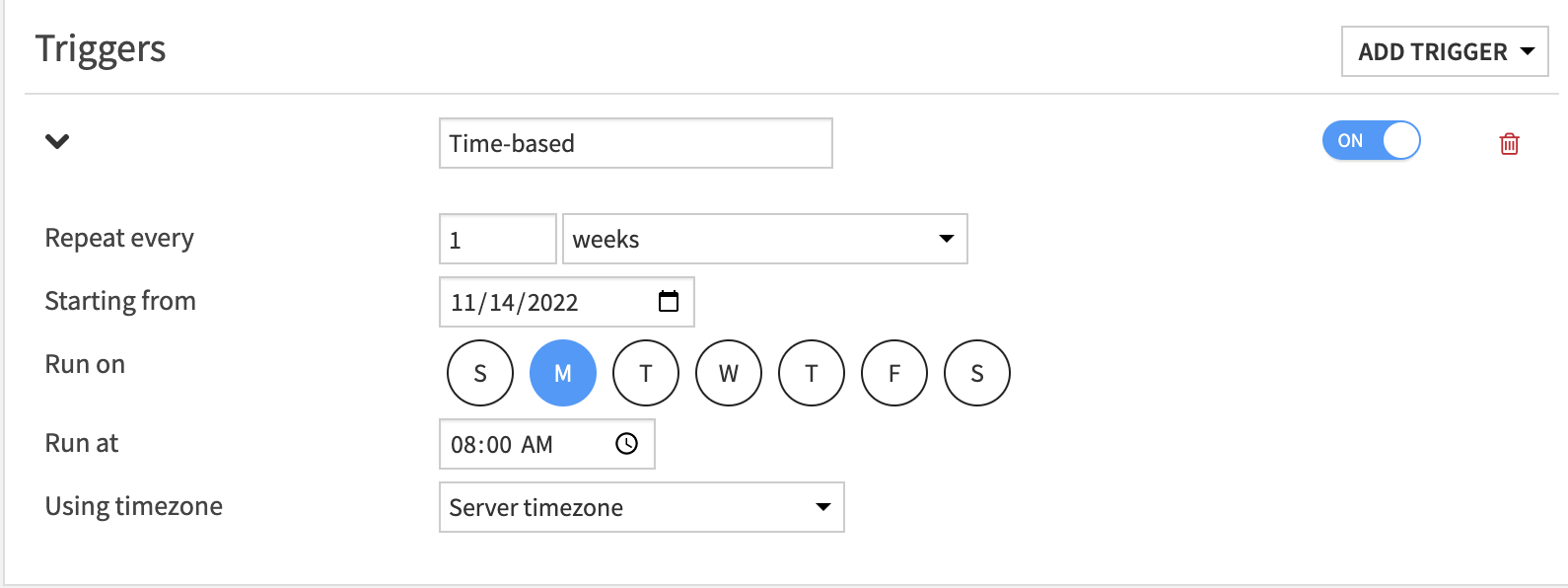
Now that we’ve confirmed that the Challenger model is better than the initial Champion, we can activate it. But what if we want to continuously compare the champion model against future challengers? This is where automation comes in with Dataiku scenarios. In the example below, the scenario repeats the steps performed previously in order to evaluate the Champion and Challenger models on the same validation data, compare their performance, and activate a new champion model accordingly. Additionally, you can see a Python code snippet that we wrote to compare the AUC performance metric and only activate the Challenger model if it performs better than the Champion. This scenario can be run on a timed basis to automate the process of promoting higher performing models to production.
Ensuring a Human-in-the-Loop Approach
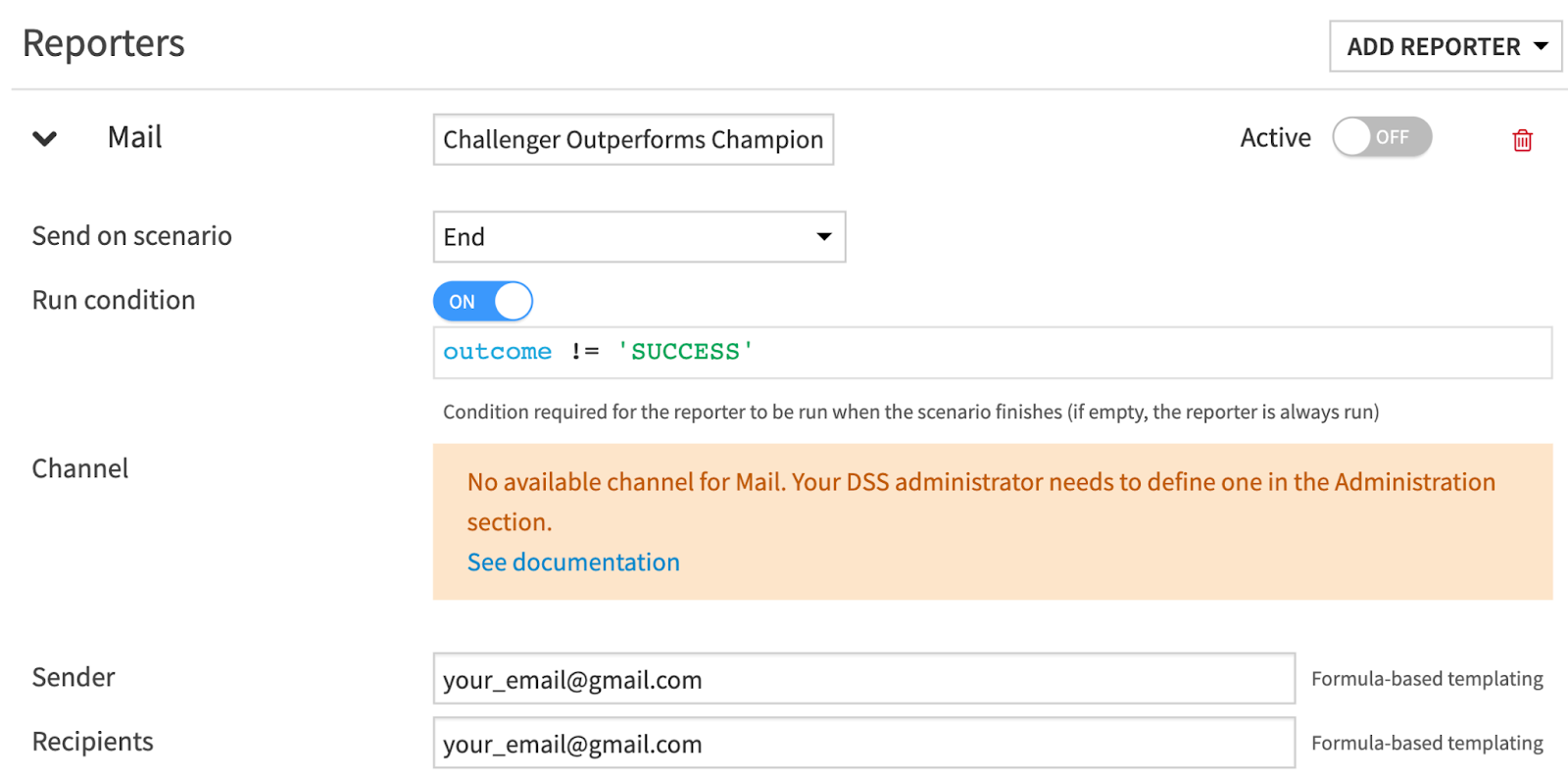
As much as we’d like to automate as much as possible, having a human-in-the-loop would add governance and control to any MLOps framework. With this example of automating Champion/Challenger evaluations, we could have the last step be a scenario reporter that sends an email to a relevant stakeholder.
Specifically, if the Challenger outperforms the Champion, instead of letting the scenario activate the Challenger model, an email trigger can be used to notify the relevant stakeholders and allow the humans to make the final call when it comes to changes in production.
{kind=link}
Key Takeaways
Dataiku’s end-to-end platform was built with MLOps frameworks in mind. This sample project is just one of many approaches to Champion / Challenger Evaluations; you could offload as much as you’d like to an automation scenario, or control as much as you want with a human-in-the-loop and governance.
Regardless of which approach you choose, features like the model evaluation store and scenarios provide a toolbox for you to leverage and customize to your organization’s needs.